标签:new efault package icon 直接 标签 ret 方式 add
使用JSOUP就行 这里给出点思路
我只做了自己的首页和其他人的微博首页的抓取 其他的抓取没尝试(不好意思 比较懒...)
首先是利用JSOUP进行登陆 获取页面 看了下微博的登陆表格 发现用了ajax的方式 所以代码获取cookie有点难
所以偷了个懒就用IE的开发者工具获取到了cookie 获取到的cookie要写成map的形式 然后用代码:
Java代码

- Response res=Jsoup.connect("http://weibo.com").cookies(map).method(Method.POST).execute();
- String s=res.body();
得到了下发现挺多的:
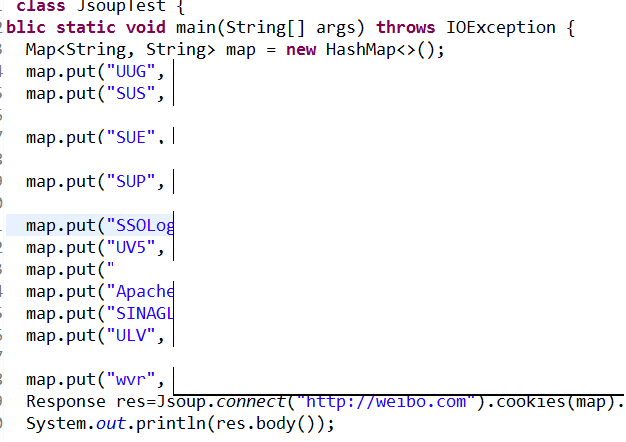
可以自己写段脚本来打印map.put(xxx,xxx)
我这里用scala写了段 用java写一样的 无所谓:
Scala代码
- s.split("; ").foreach(s => {val x=s.split("=");println(s"""map.put("${x(0)}","${x(1)}");""")});
最后得到的body 嗯......是一大堆的script标签 最上面是微博的固定的顶上那一栏的内容(导航条的内容)
lz尝试了下 发现需要的是
然后lz进行了下简单的处理 没有用正则 因为....额...写不好:
Java代码
- String s=res.body();
- //System.out.println(s);
- String[] ss=s.split("
- int i=0;
- //pl_content_homeFeed
- // for(String x:ss){
- // System.out.println(i++ + "======================================");
- // System.out.println(x.substring(0, x.length()>100?100:x.length()));
- // System.out.println("===========================================");
- // }
- String content=ss[8].split("\"html\":\"")[1].replaceAll("\\\\n", "").replaceAll("\\\\t", "").replaceAll("\\\\", "");
- content=content.substring(0, content.length()13?content.length():content.length()-13);
- System.out.println(content);
输出的content就是首页显示的微博内容
不过这个输出的话unicode没有被转成中文字符 需要用native2ascii工具 去网上找到了一个:
http://soulshard.iteye.com/blog/346807
实测可以使用:
Java代码
- System.out.println(Native2AsciiUtils.ascii2Native(content));
注意了 以上的代码 lz是固定了主页的 所以在截取时直接用了index为8的
把post方法改成get方法 也可以获取到其他人的微博页
然后给出一个打印出获取的所有html内容的做法(试了一些主页可行):
Java代码
- package jsoupTest;
-
- import java.io.IOException;
- import java.util.ArrayList;
- import java.util.HashMap;
- import java.util.List;
- import java.util.Map;
-
- import org.jsoup.Connection.Method;
- import org.jsoup.Connection.Response;
- import org.jsoup.Jsoup;
-
- public class JsoupTest {
- public static void main(String[] args) throws IOException {
- Map map = new HashMap();
- //map.put请根据自己的微博cookie得到
-
- Response res = Jsoup.connect("http://weibo.com/u/别人的主页id")
- .cookies(map).method(Method.GET).execute();
- String s = res.body();
- System.out.println(s);
- String[] ss = s.split("
- int i = 0;
- // pl_content_homeFeed
- // pl.content.homeFeed.index
- List list = new ArrayList();
- for (String x : ss) {
- // System.out.println(i++ + "======================================");
- // System.out.println(x.substring(0,
- // x.length() > 200 ? 200 : x.length()));
- // System.out.println("===========================================");
- if (x.contains("\"html\":\"")) {
- String value = getHtml(x);
- list.add(value);
- System.out.println(value);
- }
-
- }
- // content=ss[8].split("\"html\":\"")[1].replaceAll("(\\\\t|\\\\n)",
- // "").replaceAll("\\\\\"", "\"").replaceAll("\\\\/", "/");
- // content=content.substring(0,
- // content.length()
- // System.out.println(Native2AsciiUtils.ascii2Native(content));
- }
-
- public static String getHtml(String s) {
- String content = s.split("\"html\":\"")[1]
- .replaceAll("(\\\\t|\\\\n|\\\\r)", "").replaceAll("\\\\\"", "\"")
- .replaceAll("\\\\/", "/");
- content = content.substring(0,
- content.length() 13 ? content.length()
- : content.length() - 13);
- return Native2AsciiUtils.ascii2Native(content);
- }
- }
抓取的内容应该要适当格式化一下才可以用Jsoup做解析
不过试了下直接做解析也没什么问题(虽然有一些标签错误)
这只是个页面抓取的策略 其他的我不想多写了 大家自己实践一下 前提是你用自己的新浪微博的cookie进行抓取
爬取微博的数据时别人用的是FM.view方法传递html标签那么jsoup怎么解析呢
标签:new efault package icon 直接 标签 ret 方式 add
原文地址:http://www.cnblogs.com/qianzf/p/7749660.html