音乐旋律提取算法 附可执行demo
2021-05-17 00:29
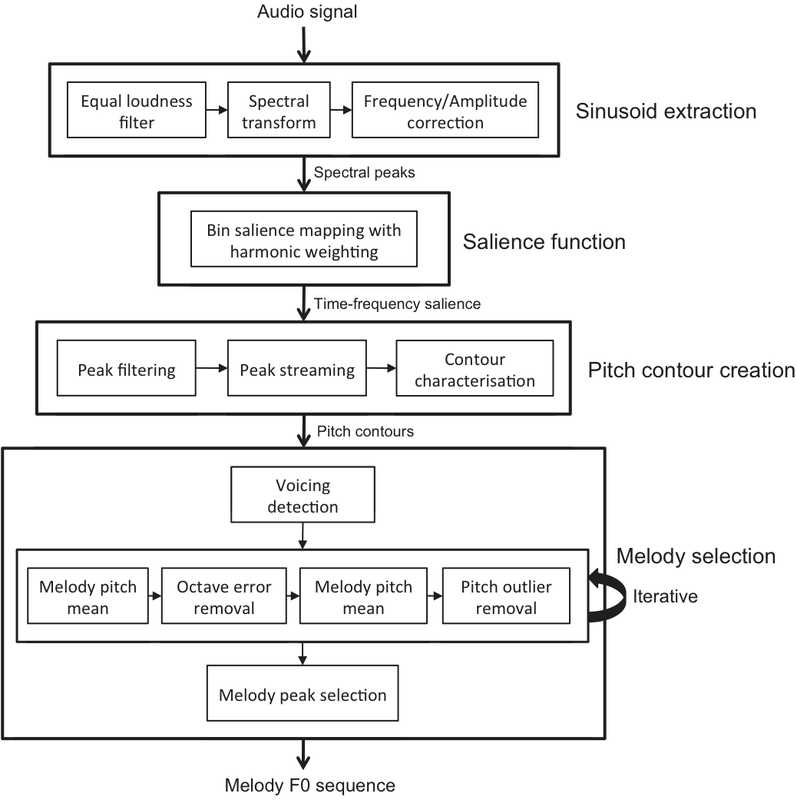
标签:格式 erp tps 下一步 dia 另一个 分享 图像 ash 前面提及过,音频指纹算法的思路。 也梳理开源了两个比较经典的算法。 https://github.com/cpuimage/shazam https://github.com/cpuimage/AudioFingerprinter 后来一段时间,稍微看了下这两个算法,还有不少可以精简优化的空间。 例如抗噪,特征有效性等优化思路。 音频指纹切片后的hash特征信息还是太多了, 不过作为哼唱搜歌的基本应用,是足够的了。 不过我觉得还是可以再进一步提取歌曲的旋律特征的,在音频指纹的基础上更进一步。 旋律是最重要的音乐要素之一,多应用于音乐内容分析、音乐创作、音乐教育、抄袭检测等方面。 主旋律提取旨在从一段音乐中自动估计对应于主旋律单音音符序列的音高或基频。 流行音乐一般属于复杂的多音音乐,因此主旋律提取面临着许多挑战。 在这里要特别说一下,音频处理领域碰到的问题都是相似的。首当其冲主要是噪声,其次是音量和语速。 特别是在一些场景下的asr识别,例如实时对话,同声传译之类环境下,语速和音量的干扰影响很多时候多过于噪声。 而很多提供asr服务的厂商对这类情况支持不佳,而据我所知,讯飞的asr中是有内置前处理算法的。 好像有点偏题了,回到主题上来。 也就是说不管做音频还是音乐 上面提到的问题都会造成一定精度影响。 音频前处理算法是非常重要的,一直在做这方面的研究工作,前面着重于降噪和增益方向,下一步应该会着重在语速方面的研究。 而刚才提到的旋律,也可以认为是语速的一个点。 旋律,节奏,节拍,精确准确度从另一个侧面就可以评估语速,以及风格内容。 所以提取旋律节奏是一个非常值得研究的课题。 也许大家最熟悉的应用场景应该是 游戏节奏类app或者唱K的旋律评分系统。 关于旋律提取这方面的资料比较有限。 在这方向上面,一开始我也是有点蒙圈。 直到我看到一个思路,我突然间豁然开朗。 那就是将歌曲音频 转换为midi电子音乐。 众所周知,midi电子音乐体积非常非常小,在游戏领域应用非常广,几乎是标配。 例如超级玛丽的背景音乐,经典中的经典。 那么是不是可以实现一种算法,将音频转为midi,作为此段音频的指纹呢? 理论上,完全可行,而且刚才提到的唱K的评分系统就是类似的实现。 参照下图: 上面是一段音乐,下面是其对于的midi。 把这个图放大给大家感受一下。 是不是有似曾相识的感觉。 KTV 的节奏条。 所以毫无疑问,KTV的评分系统极其有可能就是采用了MIDI作为声纹进行相似度匹配, 最后给出评分。 当然关于旋律提取有很多不同的实现,不过,大多数算法都有3个共同的目的, 分别是算法的速度性能(复杂度),最终效果,抗噪抗干扰。 针对这三个方面,各有各的技巧。 如果能兼顾三者,无疑是最佳的。 而关于wav转midi的资料,真的是极其稀少。 大概有: 1. https://github.com/mrk21/wav2midi https://mrk21.kibe.la/shared/entries/3931bfea-0f31-4aa1-9e72-b7cd6f010697 2.https://github.com/justinsalamon/audio_to_midi_melodia http://www.justinsalamon.com/melody-extraction.html 等 仔细学习查阅之后,你会跟我一开始一样,一脸懵逼。 首先,第三方依赖特别多,也就意味着,这个算法并不简单。 就效果对比而言,audio_to_midi_melodia 更佳,当然深度学习大火之后 也有人在尝试通过深度学习的方式,建立wav 到 midi的映射。以寻求新的突破。 当然还在试验阶段,暂时还没看到有特别优秀的模型放出。 不过可以拭目以待。 而这个算法有多复杂,看下算法的流程图: 说难也不难,说简单也不简单。 大部分环节是为了解决语速,音量,噪音所造成的误差问题,使得算法更佳稳定,更鲁棒。 根据这个思路,自行实现算法并不困难。 改进算法思路的首要前提,理解算法的核心思想, 所以至少你要把整个算法思路实现一遍,加深理解,不管能否理解到精髓。 然后站在巨人的肩膀上,继续改进。 这个算法花了我一段时间去实现,原本预计几个星期可以搞定, 但是后来因为其他原因搁置了。 趁国庆假期,捡起来,把一些工作继续推进,复现了该算法。 这个过程挺漫长的,有不少环节还可以进一步改进优化。 不过这是后面的工作了。 算法暂没有开源计划,放出demo 供大家评测。 这个方向的算法, 有一个专用名词叫做mir, 全称 为 music/audio information retrieval/signal processing 。 有兴趣的朋友,可以查阅一下相关资料。 基本上都是dsp(数字信号处理)。 学习dsp必须把傅里叶变换好好理解一下。 为了理解傅里叶变换的算法思路,我把市面上能找到的实现,都过了一遍。 用纯c 进行学习复现,也足足花了我1个多月的业余时间, 就差喷一口老血出来。 可执行demo下载地址: https://files.cnblogs.com/files/cpuimage/wav2midi.zip 使用方法:拖放wav文件到可执行文件上即可。 或者采用命令行 wav2midi.exe demo.wav 执行后生成 demo.mid 文件。 目前仅支持wav的1通道和2通道格式,其他的格式暂没做支持。 在学习音频算法的时候,经常会联系到图像方面的算法,进行类比,举一反三。 都有共通的地方,就看你怎么应用了,温故而知新。 用以前说过的一句话来总结就是, 任何算法都有缺点,但是一定要用它最优秀的思路。 就好比说,用人只要用其长处,天下皆是可用之才。 若有其他相关问题或者需求也可以邮件联系俺探讨。 邮箱地址是: 音乐旋律提取算法 附可执行demo 标签:格式 erp tps 下一步 dia 另一个 分享 图像 ash 原文地址:https://www.cnblogs.com/cpuimage/p/9747247.html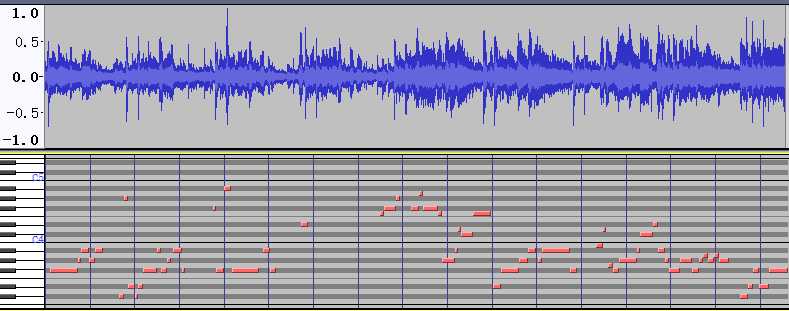

gaozhihan@vip.qq.com
上一篇:中文分词算法综述
下一篇:springmvc上传图片《2》