python统计词频
2021-05-18 12:29
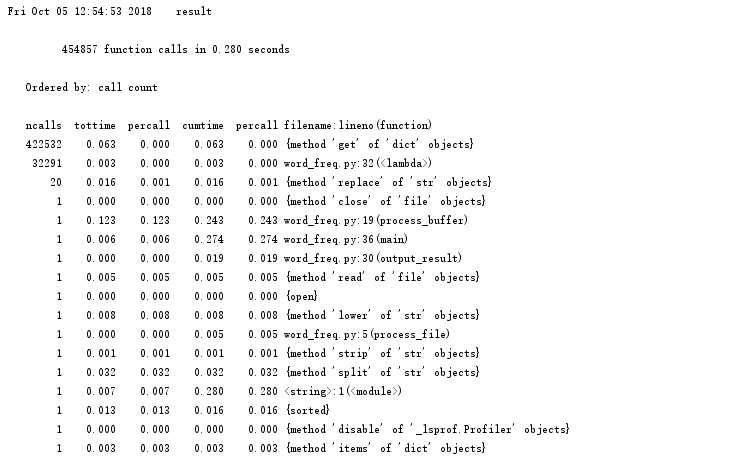
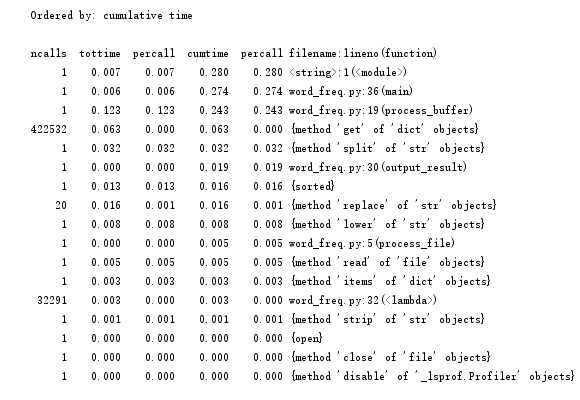
标签:环境变量 col 目标 形参 性能分析 缓冲区 spl 调用次数 lambda (1)将文件读入缓冲区(dst指文本文件存放路径,设置成形参,也可以不设,具体到函数里设置) (2)设置缓冲区,将文本度数缓冲区,并对文本的特殊符号进行修改,使其更容易处理,并读入字典。 (3)设置输出函数,运用lambda函数对词频排序,并以“词”——“频”格式输出 (4)封装main函数,以便接下来的cProfile的性能评估 使用4个空格进行缩进 每行代码尽量不超过80个字符 本次编程最长一行代码(算上下划线和空格):78个字符 分行书写import语句 词频统计结果截图 执行次数最多: 执行时间最多: 综合执行次数最多和时间最长,我们可以发现,字典中的get方法是所有话数里用的最多的,要想减少时间,我们可以从替换的符号入手,因为名著《飘》不是一个数学学术性的报告之类的,所以想@#¥%……&*这些之类的符号基本不可能在这本书里出现,所以在规范文本的过程中,我们可以减去对这些符号的替换修改。下面是两次时间和调用次数的前后对比图。 前: 后: 由此可见快乐大约0.016秒左右。 下载gprof2dot.py将此一个PY(无需将一整个文件夹放入)放到词频统计的相同目录,在graphviz官网下载zip文件,解压,并将其bin目录添加到系统的环境变量里。 最后结果分析如下: python统计词频 标签:环境变量 col 目标 形参 性能分析 缓冲区 spl 调用次数 lambda 原文地址:https://www.cnblogs.com/MonC/p/9744687.html一、程序分析
def process_file(dst): # 读文件到缓冲区
try: # 打开文件
txt=open(dst,"r")
except IOError as s:
print s
return None
try: # 读文件到缓冲区
bvffer=txt.read()
except:
print "Read File Error!"
return None
txt.close()
return bvffer
def process_buffer(bvffer):
if bvffer:
word_freq = {}
# 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq
bvffer=bvffer.lower()
for x in ‘~!@#$%^&*()_+/*-+\][‘:
bvffer=bvffer.replace(x, " ")
words=bvffer.strip().split()
for word in words:
word_freq[word]=word_freq.get(word,0)+1
return word_freq
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]: # 输出 Top 10 的单词
print item
def main():
dst = "Gone_with_the_wind.txt"
bvffer = process_file(dst)
word_freq = process_buffer(bvffer)
output_result(word_freq)
if __name__ == "__main__":
import cProfile
import pstats
cProfile.run("main()", "result")
# 直接把分析结果打印到控制台
p = pstats.Stats("result") # 创建Stats对象
p.strip_dirs().sort_stats("call").print_stats() # 按照调用的次数排序
p.strip_dirs().sort_stats("cumulative").print_stats() # 按执行时间次数排序
p.print_callers(0.5, "process_file") # 如果想知道有哪些函数调用了process_file,小数,表示前百分之几的函数信息
p.print_callers(0.5, "process_buffer") # 如果想知道有哪些函数调用了process_buffer
p.print_callers(0.5, "output_result") # 如果想知道有哪些函数调用了output_res
二、代码风格说明
缩进
def process_buffer(bvffer):
if bvffer:
word_freq = {}
行宽
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
import语句
import cProfile
import pstats
三、程序运行命令、运行结果截图

四、性能分析结果及改进
四、性能分析结果及改进
for x in ‘!%()_/-\][‘:
bvffer=bvffer.replace(x, " ")
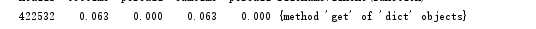
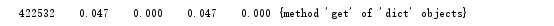
五、可视化操作
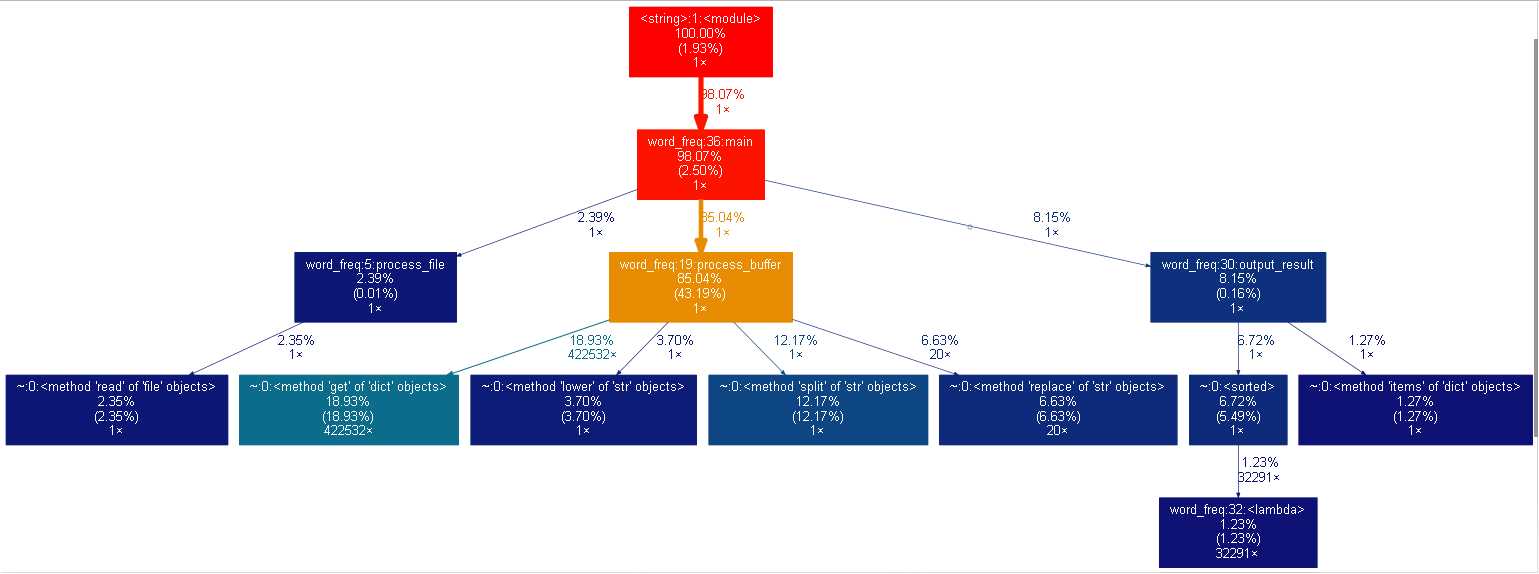
1. 性能分析:python -m cProfile -o result -s cumulative word_freq.py Gone_with_the_wind.txt;分析结果保存到 result 文件;2. 转换为图形;gprof2dot 将 result 转换为 dot 格式;再由 graphvix 转换为 png 图形格式。 命令:python gprof2dot.py -f pstats result | dot -Tpng -o result.png