Python入门
2021-05-18 12:31
标签:can 指定 通过 开源 自动生成 声明 port 导致 统一 1.若想像执行shell脚本一样执行python脚本,则需要在py文件头部指定解释器 这样一来,执行./hello.py即可。 ps:执行前要给与hello.py执行权限,chmod 755 hello.py 1.python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill) 2.ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。 3.显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536, 注:此处说的的是最少2个字节,可能更多 UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存... 所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话: 应该告诉python解释器,用什么编码来执行源代码 当行注视:# 被注释内容 多行注释:""" 被注释内容 """ Python有大量的模块,从而使得开发Python程序非常简洁。类库有包括三中: Python内部提供一个 sys 的模块,其中的 sys.argv 用来捕获执行执行python脚本时传入的参数 执行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。 ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。 变量的作用:昵称,其代指内存里某个地址中保存的内容 变量定义的规则: 2 是一个整数的例子。 int(整型) 基本操作: 常用操作: Python入门 标签:can 指定 通过 开源 自动生成 声明 port 导致 统一 原文地址:https://www.cnblogs.com/pythonlearing/p/9744592.html1.python内部执行过程
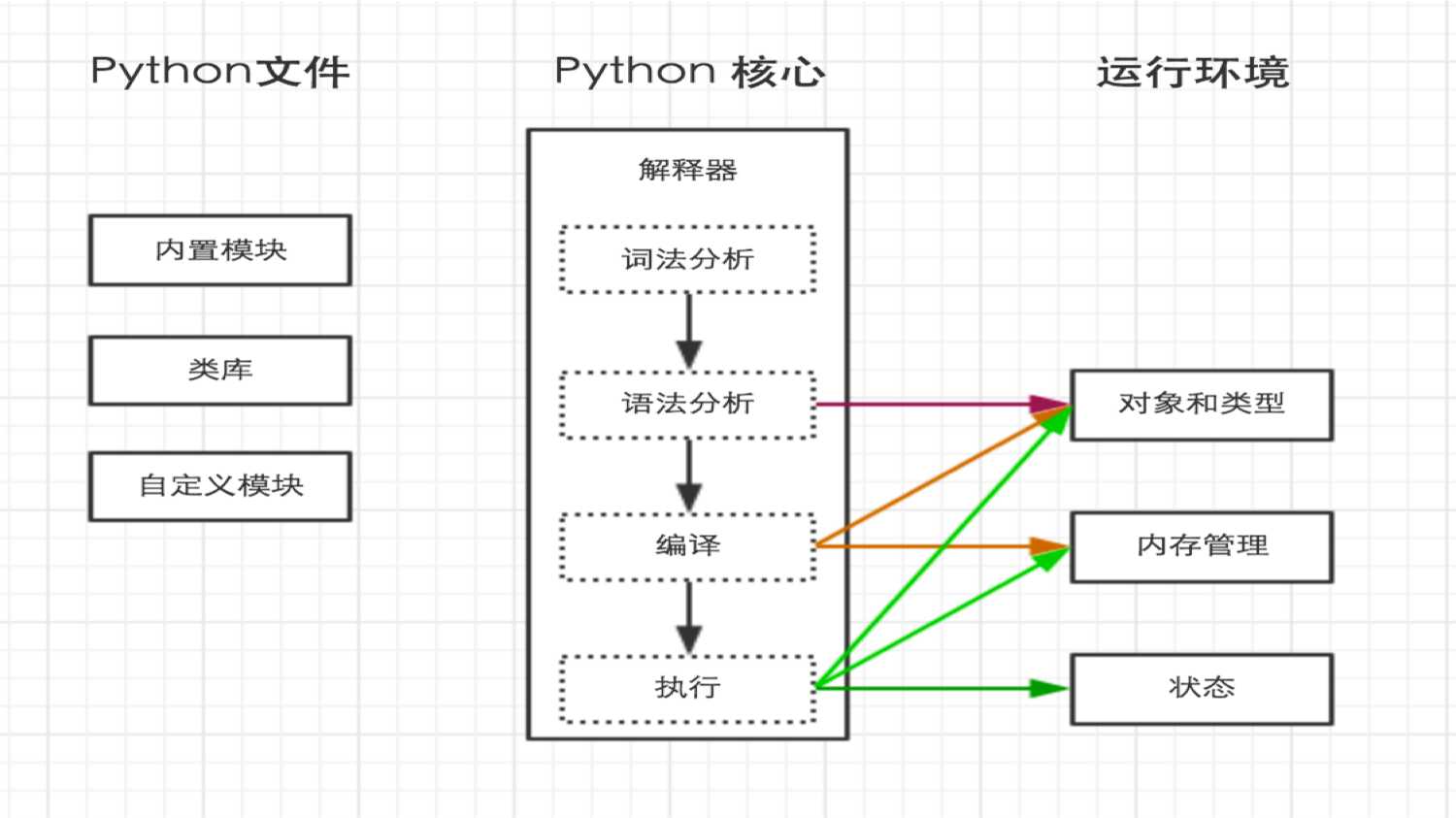
2.python解释器
#!/usr/bin/env python
print("Hello world!")
3.内容编码
#!/usr/bin/env python
print("你好,世界") #会报错,ascii无法表示中文
#!/usr/bin/env python
# -*- coding: utf -8 -*-
print("你好,世界")
4.注释
5.执行脚本传入参数
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
print(sys.argv)
6.pyc文件
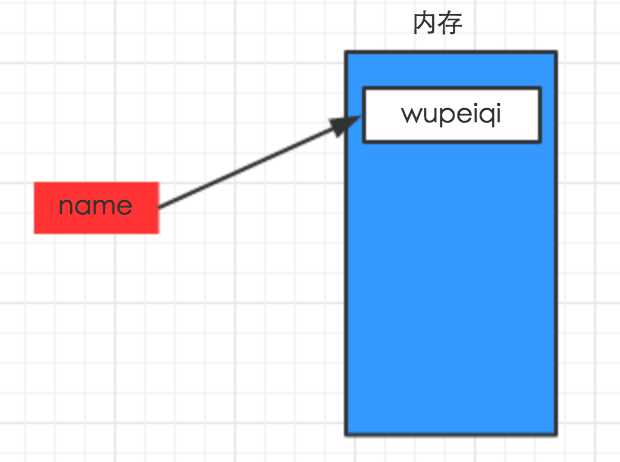
7.变量
[‘and‘, ‘as‘, ‘assert‘, ‘break‘, ‘class‘, ‘continue‘, ‘def‘, ‘del‘, ‘elif‘, ‘else‘, ‘except‘, ‘exec‘, ‘finally‘, ‘for‘, ‘from‘, ‘global‘, ‘if‘, ‘import‘, ‘in‘, ‘is‘, ‘lambda‘, ‘not‘, ‘or‘, ‘pass‘, ‘print‘, ‘raise‘, ‘return‘, ‘try‘, ‘while‘, ‘with‘, ‘yield‘]8.数据类型
长整数 不过是大一些的整数。
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。
(-5+4j)和(2.3-4.6j)是复数的例子。
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。name="hzw"
name_list = [‘alex‘, ‘seven‘, ‘eric‘]
name_list = list([‘alex‘, ‘seven‘, ‘eric‘])
ages = (11, 22, 33, 44, 55)
或
ages = tuple((11, 22, 33, 44, 55))
person = {"name": "mr.wu", ‘age‘: 18}
或
person = dict({"name": "mr.wu", ‘age‘: 18})
上一篇:Python运算符