python学习基础1
2021-05-18 15:29
标签:xxx ons 技术分享 字典 必须 状态码 根据 status 学习 根据静觅老师博客所写 博客地址:https://cuiqingcai.com/ Requests -- Python实现的简单易用的HTTP库 安装方法 pip install Requests response = requests.get("www.baidu.com") 基本 get 方式 response = requests.get("www.baidu.com") 解析 json 有些网页返回来的是一些字典形式 我门提取里面的数据就可以用这个 import requests 获取二进制数据 --图片 音视频 都是二进制文件 response.content 添加headers --加一个头可以访问一些常规认为你是爬虫的网站 headers是字典形式 必须构造成字典形式传入参数 headers = 基本post请求 data ={ } headers={ } response = requests.post("www.xxx.com",data = data,headers =headers) response.status_code 返回请求网页的状态码 对于后面根据验证码返回来的是否是自己想要状态码加以判断 resposne.cookies 返回当前的网页的cookies respionse.text 返回当前的网页源代码 response.url 返回当前的网页url 状态码判断 response = requests.post("www.xxx.com",data = data,headers =headers) if (not) response.status == xxx print(" ") else print(" ") 高级操作 文件上传 files ={‘file‘,open("文件地址","rb")} response = requests.post(url,files = files) 会话维持 --模拟登陆 每次get请求就会请求一次网页 前面的cookies就不能用于后面的网页使用 引入会话机制 s = requests.Session() s.get(url) s.get(url/xxx)j就可以正常使用 证书验证 --他会弹出一个界面 你不能访问 解决办法 response = requests.get("https://www.12306.cn",verify = “False”) 会出现一些警告 from requests.packages import urllib3 urllib3.disable_warnings() 解决 python学习基础1 标签:xxx ons 技术分享 字典 必须 状态码 根据 status 学习 原文地址:https://www.cnblogs.com/abhay/p/9744495.html
import json
response = requests.get("http://httpbin.org/get")
print(type(response.text))
print(response.json())
print(type(response.json()))
print(response.json()[‘url‘])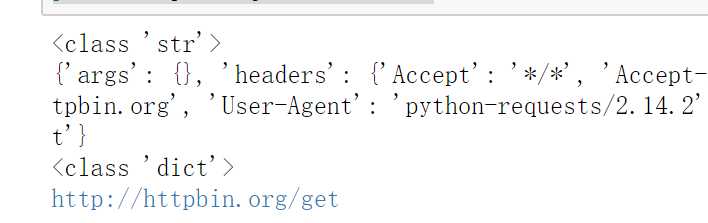
![]()
上一篇:python - socketserver 模块应用
下一篇:《C语言》打印(2)