Java函数式编程之Stream流编程
2021-05-19 21:31
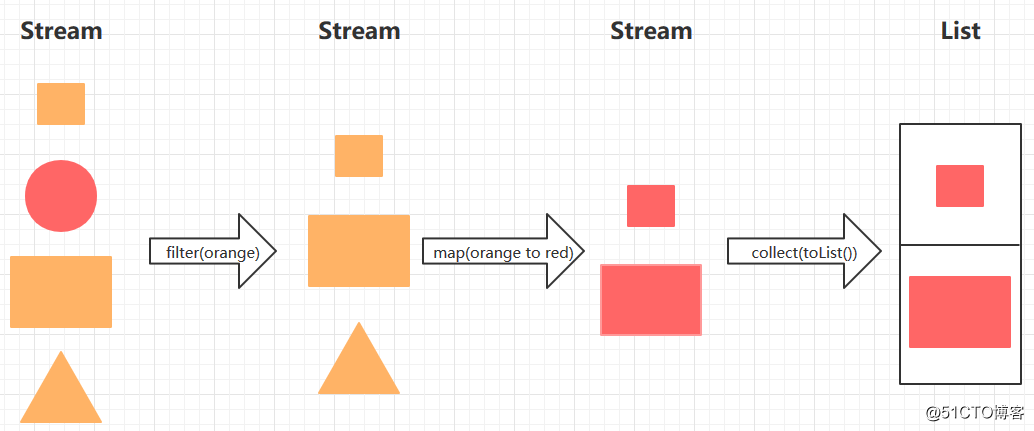
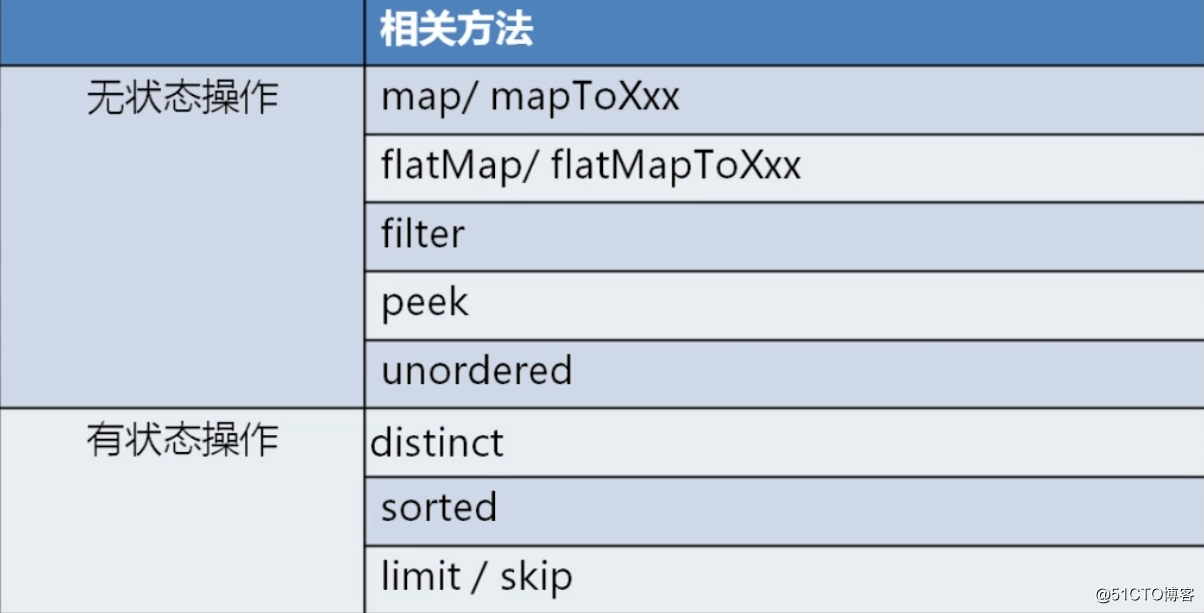
标签:拆分 tag 简单的 package arraylist RoCE 地理 type 中间 概念: 这个Stream并非是I/O流里的Stream,也不是集合元素,更不是数据结构,它是JDK1.8带来的新特性,是一种用函数式编程在集合类上进行复杂操作的工具。Stream就像工厂里的流水线一样,有输入和输出。Stream不可以重复遍历集合里面的数据,数据在Stream里面就像水在渠道里面一样,流过了就一去不复返。 简而言之,Stream是以内部迭代的方式处理集合数据的操作,内部迭代可以将更多的控制权交给集合类。Stream 和 Iterator 的功能类似,只不过 Iterator 是以外部迭代的形式处理集合的数据。 在JDK1.8以前,对集合的操作需要写出处理的过程,如在集合中筛选出满足条件的数据,需要一 一遍历集合中的每个元素,再把每个元素逐一判断是否满足条件,最后将满足条件的元素保存返回。而Stream 对集合筛选的操作提供了一种更为便捷的操作,只需将实现函数接口的筛选条件作为参数传递进来,Stream会自行操作并将合适的元素同样以 stream 的方式返回,最后进行接收即可。 内部迭代与外部迭代: 使用for循环等利用Iterator进行迭代操作的,我们都叫做外部迭代,而使用stream流进行迭代操作的叫做内部迭代。内部迭代最明显的好处就是当数量很大的情况下,我们不需要对数据进行拆分,并且可以通过调用指定函数实现并行遍历。 外部迭代示例代码: 使用stream内部迭代示例代码: 使用stream流操作时的一些概念: 如何区分中间操作和终止操作呢?可以根据操作的返回值类型判断,如果返回值是Stream,则该操作为中间操作。如果返回值不是Stream或者为空,则该操作是终止操作。 如下图所示,前两个操作是中间操作,只有最后一个操作是终止操作: 可以形象地理解Stream的操作是对一组粗糙的工艺品原型(即对应的 Stream 数据源)进行加工成颜色统一的工艺品(即最终得到的结果),第一步筛选出合适的原型(即对应Stream的 filter 的方法),第二步将这些筛选出来的原型工艺品上色(对应Stream的map方法),第三步取下这些上好色的工艺品(即对应Stream的 collect(toList())方法)。在取下工艺品之前进行的操作都是中间操作,可以有多个或者0个中间操作,但每个Stream数据源只能有一次终止操作,否则程序会报错。 接下来,我们通过一个简单的示例来演示以上所提到的几个概念,代码如下: 运行以上代码,控制台输出结果如下,可以看到由于惰性求值的原因,doubleNum方法没有被调用: 对一个流完整的操作过程:流的创建 -> 中间操作 -> 终止操作。流的创建是第一步,而流的常见创建方式如下表: 代码示例如下: 然后我们来看看流的中间操作,中间操作分类两类,一类是无状态操作,一类则是有状态操作。如下表: 无状态操作: 有状态操作: 共同点: 代码示例如下: 接下来我们看看流的终止操作,同样的,终止操作也分类两类,分别是短路操作和非短路操作。如下表: 短路操作: 非短路操作: 具体代码及注释,请参考如下示例: 以上的例子中大多数创建的都是单线程流,其实我们可以创建多线程并行的Stream流,即并行流。使用并行流时,我们并不需关心多线程执行以及任务拆分等问题,因为Stream都已经帮我们管理好了,所以用起来也是很方便的。 我们先来看一个不使用并行流的示例,以下代码会每隔3秒打印一行信息: 运行结果如下: 而使用并行流后,会发现同时打印了多行信息。代码如下: 至于同时会打印多少行,默认取决于cpu的核心数量,例如我电脑cpu有4个核心,所以会同时打印四行,也就是说开启了四个线程。运行结果如下: 通过以上的例子,我们得知可以调用parallel方法来创建并行流。那么同样的,也可以调用类似的方法创建串行流,这个方法就是sequential。如果现在有一个需求:当进行第一步操作时需使用并行流,而第二步操作则需使用串行流。那么我们可以通过结合这两个方法来实现这个需求吗?我们来看一个简单的例子就知道了,代码如下: 运行结果如下: 从运行结果可以看到,运行过程始终是串行的,是一行行打印的。所以可以得出一个结论:多次调用 parallel/sequential方法,会以最后一次调用的为准,自然就无法实现以上所提到的需求了。 接下来我们看看并行流里线程相关的东西,在上文中,我们提到了默认情况下,并行流开启的线程数量取决于cpu的核心数量。那么并行流使用的是哪个线程池?如何设置开启的线程数量? 先来回答第一个问题,并行流里使用的线程池是 关于第二个设置线程数量的问题,则是需要在创建并行流之前,设置ForkJoinPool里parallelism属性的值,例如我要开启20个线程,具体代码如下: 还有一点需要注意的就是,所有的并行流默认都将会使用同一个ForkJoinPool线程池,若我们的并行任务比较多的话,可能会出现任务阻塞的情况。如果想要防止一些比较关键的任务出现阻塞的情况,则需要自行创建线程池去处理这些任务。如下示例: 本小节我们来看一下收集器相关的东西,收集器就是将流处理完后的数据收集起来,例如将数据收集到一个集合里,或者对数据求和、拼接成字符串等行为都属于收集器。 以下使用一组例子来演示一下收集器的常见使用方式。首先定义一个Student类以及相关的枚举类,代码如下: 使用收集器的示例代码如下: 运行结果如下: 通过以上几个小节的内容,我们已经掌握了流的基本操作。但是我们对流的运行机制还不太清楚,所以本小节我们将简单认识一下Stream的运行机制。 同样的,我们首先来编写一段简单的Stream操作代码,如下: 运行以上代码,控制台输出如下: 1.从运行结果中可以看到,peek和filter是交替执行的,也就是说所有操作都是链式调用,一个元素只迭代一次 2.既然是一个链式的调用,那么这条链是怎么样的呢?是如何维护的呢?我们在终止操作上打上断点,通过debug运行。如下图,可以看到每一个中间操作返回一个新的流,而流里面有一个属性sourceStage,它都指向同一个地方,就是链表的头Head: 3.而Head里指向了nextStage,nextStage里又指向了nextStage,一直指向到链尾的null值。就如: 这就是Stream里实现链式调用所需的一个链表结构,是一条单链 以上的例子只有无状态操作,如果加入有状态操作,会发生什么变化呢?示例代码如下: 运行以上代码,控制台输出如下: 从输出的日志信息可以发现,用于排序的中间操作截断了流,并没有像无状态操作那样交替执行。所以我们就可以得知有状态操作会把无状态操作截断,会单独进行处理而不会交替执行。 然后我们再加上并行流,看看并行情况下又是怎样的,输出的日志信息如下: 从日志打印可以看到,排序操作依旧是main线程执行的,而其他的操作则是线程池里的线程执行的。所以我们通过这个例子可以得知即便在并行的环境下,有状态的中间操作不一定能并行操作。 顺带说明一下 parallel/ sequetial 这2个操作也是中间操作 (也是返回stream) ,但是区别在于它们不会创建流,,它们只修改 Head 的并行标志,因为这两个方法修改的是同一个地方,所以才会以最后一次调用的为准: Java函数式编程之Stream流编程 标签:拆分 tag 简单的 package arraylist RoCE 地理 type 中间 原文地址:http://blog.51cto.com/zero01/2292374
int[] nums = {1, 2, 3};
// 循环属于外部迭代
int sum = 0;
for (int num : nums) {
sum += num;
}
System.out.println("计算结果为:" + sum); // 计算结果为:6int[] nums = {1, 2, 3};
// 使用stream进行内部迭代
int sum = IntStream.of(nums).sum();
System.out.println("计算结果为:" + sum); // 计算结果为:6
package org.zero01.example.demo;
import java.util.stream.IntStream;
public class StreamDemo {
public static void main(String[] args) {
int[] nums = {1, 2, 3};
// IntStream创建数字流,of则是输入一个数组,这里的map就是中间操作(返回stream流的操作),sum则是终止操作
int sum = IntStream.of(nums).map(i -> i * 2).sum();
System.out.println("计算结果为:" + sum);
System.out.println("惰性求值就是终止操作没有调用的情况下,中间操作不会执行");
IntStream.of(nums).map(StreamDemo::doubleNum);
}
public static int doubleNum(int i) {
System.out.println("doubleNum 方法执行了");
return i * 2;
}
}计算结果为:12
惰性求值就是终止操作没有调用的情况下,中间操作不会执行
流的创建

public static void main(String[] args) {
List
流的中间操作
public static void main(String[] args) {
String str = "my name is zero";
// 把每个单词的长度打印出来
System.out.println("---------------map---------------");
Stream.of(str.split(" ")).map(String::length).forEach(System.out::println);
// 只打印长度大于2的单词
System.out.println("---------------filter---------------");
Stream.of(str.split(" ")).filter(s -> s.length() > 2)
.map(String::length).forEach(System.out::println);
// flatMap 适合用于A元素下有B属性,并且这个B属性是个集合,最终得到所有的A元素里面的所有B属性集合
// 这里调用了 boxed() 方法的原因是intStream\LongStream等数字流并非是Stream的子类,所以需要装箱
System.out.println("---------------flatMap---------------");
Stream.of(str.split(" ")).flatMap(s -> s.chars().boxed())
.forEach(integer -> System.out.println((char) integer.intValue()));
// peek 一般用于debug,类似于forEach,不同的是peek是中间操作而forEach是终止操作
System.out.println("---------------peek---------------");
Stream.of(str.split(" ")).peek(System.out::println).forEach(System.out::println);
// limit 主要用于限制无限流,我们可以结合filter来产生特定区间的随机数
System.out.println("---------------limit---------------");
new Random().ints().filter(i -> i > 100 && i
流的终止操作

public static void main(String[] args) {
String str = "my name is zero";
// 通常会在使用并行流的时候使用forEachOrdered,forEachOrdered可以在并行的情况下保证元素顺序的一致
str.chars().parallel().forEachOrdered(i -> System.out.print((char) i));
System.out.println();
// 而forEach则无法在并行的情况下保证元素顺序的一致
str.chars().parallel().forEach(i -> System.out.print((char) i));
System.out.println();
// collect属于收集器,使用可以将放入流里面的数据收集成集合类型
List
并行流
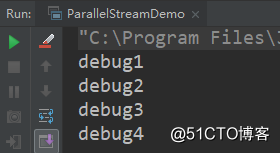
public static void main(String[] args) {
// 不使用并行流
IntStream.range(1, 100).peek(ParallelStreamDemo::debug).sum();
}
public static void debug(int i) {
System.out.println("debug" + i);
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
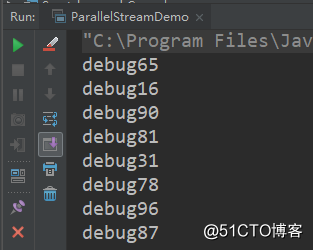
public static void main(String[] args) {
// 不使用并行流
IntStream.range(1, 100).parallel().peek(ParallelStreamDemo::debug).sum();
}
public static void debug(int i) {
System.out.println("debug" + i);
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
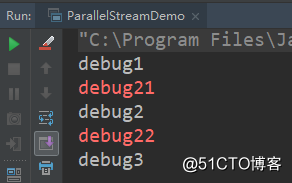
public static void main(String[] args) {
IntStream.range(1, 100)
// 1.调用parallel产生并行流
.parallel().peek(ParallelStreamDemo::debug)
// 2.调用sequential产生串行流
.sequential().peek(ParallelStreamDemo::debug2).sum();
}
public static void debug(int i) {
System.out.println("debug" + i);
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void debug2(int i) {
System.err.println("debug2" + i);
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
java.util.concurrent.ForkJoinPool,这一点可以直接在方法里打印线程名称得知,所以这里就不演示了。对ForkJoinPool感兴趣的话,可以查阅fork/join相关的概念。System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "20");public static void main(String[] args) {
// 使用自己创建的线程池,不使用默认线程池,防止任务阻塞
ForkJoinPool forkJoinPool = new ForkJoinPool(20);
forkJoinPool.submit(() -> IntStream.range(1, 100).parallel().peek(ParallelStreamDemo::debug).sum());
forkJoinPool.shutdown(); // 关闭线程池
// 防止主线程提前结束
synchronized (forkJoinPool) {
try {
forkJoinPool.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
收集器
// ...省略getter/setter以及全参/无参构造函数...
public class Student {
private String name;
private int age;
private Gender gender;
private Grade grade;
}
/**
* 性别
*/
enum Gender {
MALE, FEMALE
}
/**
* 班级
*/
enum Grade {
ONE, TWO, THREE, FOUR;
}public static void main(String[] args) {
// 测试数据
List所有学生的年龄列表: [10, 9, 8, 13, 7, 13, 13, 9, 6, 6, 14, 13]
年龄汇总信息: IntSummaryStatistics{count=12, sum=121, min=6, average=10.083333, max=14}
男女学生列表: =
{
false = [Student(name=小白, age=8, gender=FEMALE, grade=TWO), Student(name=小黑, age=13, gender=FEMALE, grade=FOUR), Student(name=小红, age=7, gender=FEMALE, grade=THREE), Student(name=小青, age=13, gender=FEMALE, grade=THREE), Student(name=小紫, age=9, gender=FEMALE, grade=TWO), Student(name=小马, age=14, gender=FEMALE, grade=FOUR)]
true = [Student(name=小明, age=10, gender=MALE, grade=ONE), Student(name=大明, age=9, gender=MALE, grade=THREE), Student(name=小黄, age=13, gender=MALE, grade=ONE), Student(name=小王, age=6, gender=MALE, grade=ONE), Student(name=小李, age=6, gender=MALE, grade=ONE), Student(name=小刘, age=13, gender=MALE, grade=FOUR)]
}
学生班级列表: =
{
TWO = [Student(name=小白, age=8, gender=FEMALE, grade=TWO), Student(name=小紫, age=9, gender=FEMALE, grade=TWO)]
FOUR = [Student(name=小黑, age=13, gender=FEMALE, grade=FOUR), Student(name=小马, age=14, gender=FEMALE, grade=FOUR), Student(name=小刘, age=13, gender=MALE, grade=FOUR)]
ONE = [Student(name=小明, age=10, gender=MALE, grade=ONE), Student(name=小黄, age=13, gender=MALE, grade=ONE), Student(name=小王, age=6, gender=MALE, grade=ONE), Student(name=小李, age=6, gender=MALE, grade=ONE)]
THREE = [Student(name=大明, age=9, gender=MALE, grade=THREE), Student(name=小红, age=7, gender=FEMALE, grade=THREE), Student(name=小青, age=13, gender=FEMALE, grade=THREE)]
}
所有班级学生人数列表: =
{
TWO = 2
FOUR = 3
ONE = 4
THREE = 3
}
Stream运行机制
public static void main(String[] args) {
Random random = new Random();
// 随机产生数据
Stream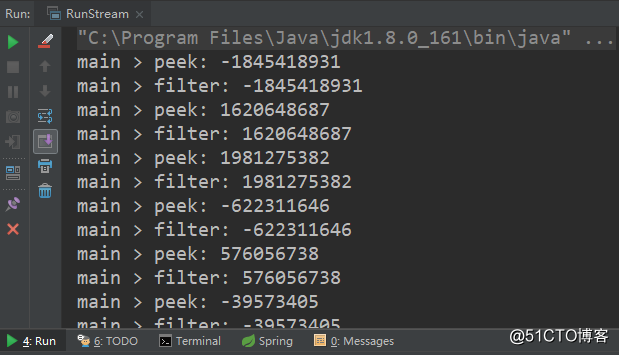
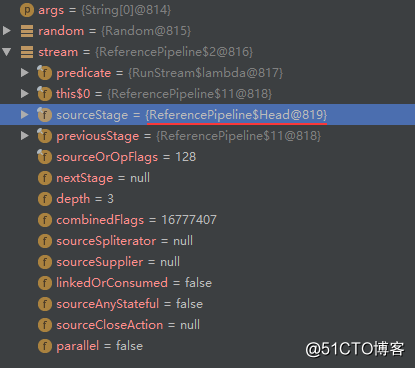
Head -> nextStage -> nextStage -> ... -> null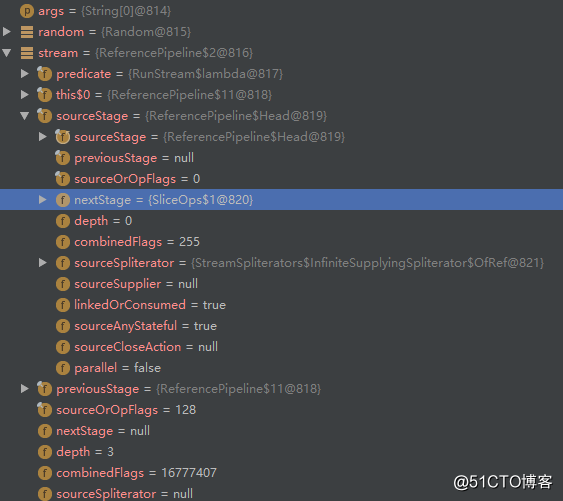
public static void main(String[] args) {
Random random = new Random();
// 随机产生数据
Streammain > peek: -1564323985
main > filter: -1564323985
main > peek: -779802182
main > filter: -779802182
main > peek: -498652682
main > filter: -498652682
main > 排序: 78555310, 50589406
main > 排序: 74439402, 50589406
main > 排序: 56492454, 50589406
main > 排序: 39808935, 50589406
main > 排序: 39808935, 39002482
main > peek2: 25284397
main > peek2: 29672249
main > peek2: 29800626
main > peek2: 32299397ForkJoinPool.commonPool-worker-3 > peek: -332079048
ForkJoinPool.commonPool-worker-3 > filter: -332079048
ForkJoinPool.commonPool-worker-1 > filter: 1974510987
ForkJoinPool.commonPool-worker-4 > peek: -1727742841
ForkJoinPool.commonPool-worker-4 > filter: -1727742841
main > 排序: 58979900, 74247464
main > 排序: 58979900, 57671811
main > 排序: 53543451, 57671811
main > 排序: 53543451, 42862261
main > 排序: 43624983, 42862261
ForkJoinPool.commonPool-worker-0 > peek2: 1152454167
ForkJoinPool.commonPool-worker-2 > peek2: 1468420859
ForkJoinPool.commonPool-worker-5 > peek2: 736525554
ForkJoinPool.commonPool-worker-6 > peek2: 1×××50615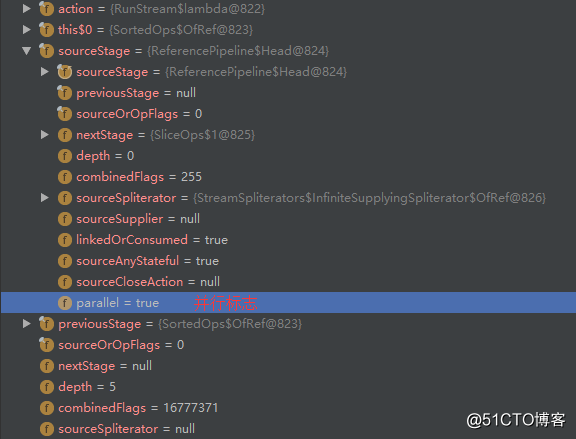
下一篇:css学习
文章标题:Java函数式编程之Stream流编程
文章链接:http://soscw.com/index.php/essay/87775.html