Hadoop-Flume日志采集系统
2021-05-23 02:28
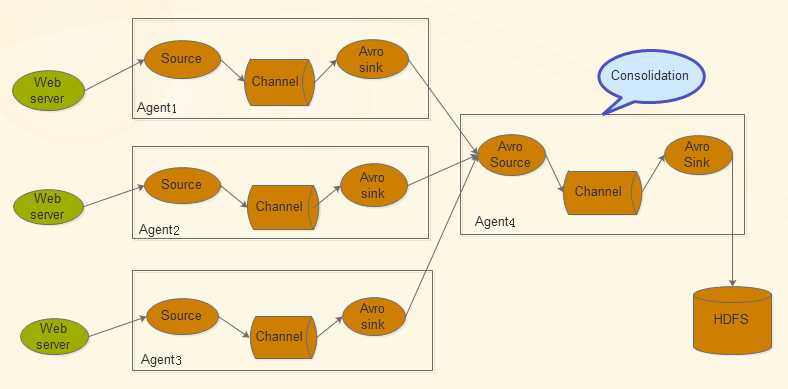
标签:data 通过 example 数据库 高可用性 val 系统 发送 stream Flume是Cloudera提供的日志收集系统,具有分布式、高可靠、高可用性等特点,对海量日志采集、聚合和传输,Flume支持在日志系统中制定各类数据发送,同时,Flume提供对数据进行简单处理,并写到各种数接受方的能力。其设计的原理也是基于将数据流,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中。 Flume的特征:可靠性,可扩展性,可管理性 接下来我们说的是Flume NG架构的优势: 1、NG 在核心组件上进行了大规模的调整 2、大大降低了对用户的要求,如用户无需搭建ZooKeeper集群 3、有利于 Flume 和其他技术、hadoop 周边组件的整合 4、在功能上更加强大、可扩展性更高 Flume的核心是把数据从数据源收集过来,在送到目的地,为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据 Source可以接收外部源发送过来的数据,不同的source可以接受不同的数据格式。比如有目录池(spooling directory)数据源,可以监控指定文件夹中的新文件变化,如果目录中有文件产生,就会立刻读取其内容 Channel是一个存储地,接收source的输出,直到sink消费掉channel中的数据。channel中的数据直到进入到下一个channel中或者进入终端才会被删除。当sink写入失败后,可以自动重启,不会造成数据丢失,因此很可靠 Sink会消费channel中的数据,然后送给外部源或者其他source。如数据可以写入到HDFS或者HBase中。 Flume允许多个agent连在一起,形成前后相连的多级跳: Flume架构核心组件: source:source负责接收event或通过特殊机制产生event,并将events批量的放到一个或多个channel,source必须至少和一个channel关联 不同类型的source:与系统集成的source: Syslog, Netcat;直接读取文件的 source: ExecSource、SpoolSource;用于Agent和Agent之间通信的IPC Source: Avro、Thrift channel:channel位于source和sink之间,用于缓存进来的event。当Sink成功的将event发送到下一跳的channel或最终目的时候,event从Channel移除。 几种channel类型:MemoryChannel 可以实现高速的吞吐,但是无法保证数据的完整性;FileChannel(磁盘channel)保证数据的完整性与一致性。在具体配置FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率 sink:Sink负责将event传输到下一跳或最终目的;sink在设置存储数据时,可以向文件系统、数据库、Hadoop存数据,在日志数据较少时,可以将数据存储在文件系统中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到hadoop中,便于日后进行相应的数据分析。必须作用于一个确切的channel 下载源码包:http://mirror.bit.edu.cn/apache/flume/1.6.0/ 1、安装软件包: [lan@master ~]$ tar -xvf apache-flume-1.6.0-bin.tar.gz 2、将源码合并至安装目录apache-flume-1.6.0-bin下 配置环境变量: [lan@master ~]$ vim ~/.bash_profile export FLUME_HOME=/home/lan/apache-flume-1.6.0-bin/ 测试flume-ng是否安装成功: flume-ng version 3、 新建一个flume代理agent1的配置文件example.conf #agent1 #source1 #sink1 #channel1 新建agent1log: [lan@master ~]$ mkdir agent1log [lan@master ~]$ cd apache-flume-1.6.0-bin [lan@master apache-flume-1.6.0-bin]$ flume-ng agent -n agent1 -c conf -f /home/lan/apache-flume-1.6.0-bin/conf/example.conf -Dflume.root.logger=DEBUG,console 另启一个terminal,在监测目录下创建新的文件test2.txt 查看sink1的输出,发现目标路径下有一个以FlumeData开始,产生文件的时间戳为后缀的文件,说明flume能监测到目标目录变化,将产生变化的部分实时地收集到sink的输出中。 Hadoop-Flume日志采集系统 标签:data 通过 example 数据库 高可用性 val 系统 发送 stream 原文地址:http://www.cnblogs.com/LBJFF/p/7686879.html
Flume传输的数据基本单位是Event,如果是文本文件,通常是一行记录,这也是事务的基本单位。Event从Source,流向Channel,再到Sink,本身为一个byte数组,并可携带headers信息。Event代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去
Flume运行的核心是Agent。它是一个完整的数据收集工具,含有三个核心组件,分别是source、channel、sink。通过这些组件,Event可以从一个地方流向另外一个地方。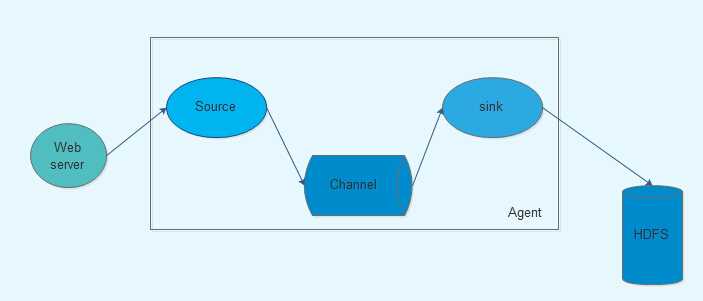
[lan@master ~]$ tar -xvf apache-flume-1.6.0-src.tar.gz
export PATH=$PATH:$FLUME_HOME/bin
[lan@master ~]$ cd apache-flume-1.6.0-bin/conf/
[lan@master conf]$ vim example.conf
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = c1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /home/lan/agent1log
agent1.sources.source1.channels = c1
agent1.sources.source1.fileHeader = false
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = hdfs://master:9000/agentlog
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat = TEXT
agent1.sinks.sink1.hdfs.rollInteval = 4
agent1.sinks.sink1.channel = c1
agent1.channels.c1.type = file
agent1.channels.c1.checkpointDir = /home/lan/agent1_tmp1
agent1.channels.c1.dataDirs = /home/lan/agent1_tmpdata
#agent1.channels.channel1.capacity = 10000
#agent1.channels.channel.transactionCapacity = 1000
cd ~/agent1log
vim test2.txt
上一篇:fastjson生成JSON字符串的时候出现$ref
下一篇:js库写法
文章标题:Hadoop-Flume日志采集系统
文章链接:http://soscw.com/index.php/essay/88079.html