《推荐三十六式》工程篇之Netflix的个性化推荐架构
2021-05-28 23:04
标签:学习 机器 消息 重复 点击 内容 工程 nbsp 时间 先看一下Netflix的简单推荐架构图: 主要分为:离线层,近线层和在线层 时至今日,推荐系统已经成为许多产品的核心功能。一个好的推荐系统应该拥有的特质: 1.实时响应请求 2.及时、准确,全面记录用户反馈 3.可以优雅降级 4.快速试验多种策略 针对数据的使用时间进行划分,可分为三部分: 1.离线:使用历史数据,提供历史数据的推理 2.近线:使用实时数据,可提供实时数据的推理 3.在线:使用实时数据,提供实时服务 下面我们不同视角观察推荐系统如何进行工作: 1.数据流 用户在交互界面产生行为事件数据(浏览,点击等),一边进入离线分布式存储,供离线计算,另一边进入近线消息队列,供流计算使用。 离线数据被训练成模型,在线通过调用模型结果进行推荐。 近线数据训练的模型,更新离线模型的结果,再在在线进行推荐。 2.在线层 实时响应用户请求,将推荐的结果返回给用户 在线层一般是restful API的形式,后端则是RPC服务调用。以用户ID等信息去请求,以json的形式返回排序的结果。 一般会放哪些逻辑在在线层呢? 1.模型的结果 2.额外的干预逻辑和权重调节 如果在线层没有从模型中拿到结果,或者拿到的结果被额外的逻辑过滤掉了,那么就要准备一个兜底的结果。 在线层还要实时收集用户使用产品时的事件,送到近线层进行处理,再调用近线层的模型结果。比如,剔除重复的推荐内容。 3.离线层 离线层一般会收集某个周期内所有用户数据,按照业务需求对数据进行ETL,之后再提供给各类机器学习模型进行学习,最终将得到的模型结果供在线层去调用。 4.近线层 近线层一般会延迟提供推荐结果,用户本次使用产品时,产生的事件会存入消息队列中,然后被消费进行模型计算,模型结果再与离线的模型结果进行融合,更推荐的结果更具有时效性。 《推荐三十六式》工程篇之Netflix的个性化推荐架构 标签:学习 机器 消息 重复 点击 内容 工程 nbsp 时间 原文地址:https://www.cnblogs.com/bladerunnerwhd/p/14753408.html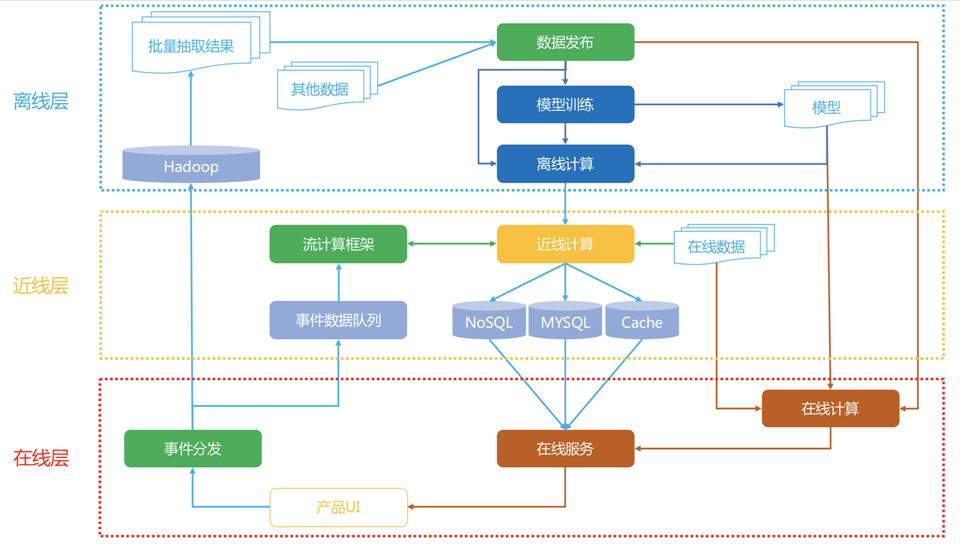
下一篇:js例子和Jquery
文章标题:《推荐三十六式》工程篇之Netflix的个性化推荐架构
文章链接:http://soscw.com/index.php/essay/88851.html