使用Python实现并行运算处理数据
2021-06-04 12:04
标签:pre highlight break 方便 介绍 时间 learn style csdn 解决问题:采用并行运算提升数据处理速度 首先介绍一下并行计算是同时有很多程序一起运行,线程是进程的基本单位,一个进程中包括很多个线程,线程共享同一个进程的资源和空间,而进程之间是独立的,互不干扰,不能共享资源和空间 快速掌握Python写并行程序:https://blog.csdn.net/NNNJ9355/article/details/103774314 其次并行计算要知道自己电脑中CPU核数:https://jingyan.baidu.com/article/4f34706e1c6757e386b56d57.html,方便下面写程序是填写最大使用核数 数据处理描述:一共有4096个.csv文件,每个文件中都有数据,计算两两之间的相关系数 原本计算一个需要8个小时,采用了6核计算后,处理时间变为1个半小时,速度提升很快 数据形式: python提供了multiprocessing并行运算的库 第一个:自发电学习神经元之间的互相关程序 总结一下在编写程序中遇到的错误以及注意事项: 1、编写的函数如果含有几个变量和常数值,则可以使用partial函数,它的作用是将原本函数进行二次封装,变成一个新的函数,(使用格式:新函数名字=partial(初始函数名字,常量名,.......常量名)例如: func=partial(Cal_first2067CrossMartix,csvPathArr,lparr)输入的常量可以是str或者list类型 2、并行函数初始化数值的格式,这里可以是list形式,如:[1,2,3,4],如果是多变量形式可以是list里面嵌套tuple,如:[(1,2),(2,3),(3,4)]以此类推,有几个变量都可以加在tuple里面,切记刚刚使用偏函数封装了一个新的函数,在定义并行函数时,常量命名一定要写在变量之前,否则顺序会颠倒,这里使用pool.map(func,iterable)进行映射所有计算的初始值 func=partial(Cal_first2067CrossMartix,csvPathArr,lparr)#偏函数重新封装 示例2: 参考博客:https://blog.csdn.net/u013421629/article/details/100284962 3、修改核数 第二个:测试一个自发电两个电极之间相关系数的程序(可输出图片) 第三个:所有神经元计算互相关程序 使用Python实现并行运算处理数据 标签:pre highlight break 方便 介绍 时间 learn style csdn 原文地址:https://www.cnblogs.com/smile621sq/p/14640876.html
import pandas as pd
import numpy as np
from sympy import DiracDelta#导入狄拉克函
from matplotlib import pyplot as plt
import os
import math
import multiprocessing # 导入多进程中的进程池
from functools import partial
from time import *
def get_sum(num1,num2,array):
count=0
for n in array:
if num1num2:
break
return count
#遍历该文件夹下所有.csv文件
def get_file(path): # 创建一个空列表
files = os.listdir(path)
list = []
for file in files:
if not os.path.isdir(path + file): # 判断该文件是否是一个文件夹
f_name = str(file)
# print(f_name)
tr = ‘\\‘ # 多增加一个斜杠
filename = path + tr + f_name
#filename = f_name
list.append(filename)#得到所有
return list
def get_csvarr(csvPath):
allFileNames = get_file(csvPath) # 获取4096个.csv
larr = np.array(allFileNames)
csvPathArr = np.reshape(larr, (larr.shape[0])) # 获取.csv路径数组
return csvPathArr
def get_learnArr(lpPath):
pdata = pd.read_csv(lpPath, header=None)
plarr = np.array(pdata[1:]) # 获取学习神经元的标签
plarr = np.reshape(plarr, (plarr.shape[0]))
return plarr
def read_csv(csvfilePath):
data=pd.read_csv(csvfilePath,header=None)
data=np.array(data)
data=np.round(data,3)
rd, cd = data.shape
csvdata = np.reshape(data, cd)
return csvdata
def Cal_first2067CrossMartix(csvPathArr,lparr,threeit):#refName代表参考电极的路径,csvPathArr代表电极csv路径,num代表电极序号,lpLable代表学习标签,lparr代表学习位置数组
refPath=threeit[0]#原始数据路径
lpLable=int(float(threeit[1]))#原始数据的学习标签
num=int(threeit[2])#原始数据的序号
fillzeros=np.zeros(4096)
if lpLable==1:#是学习的计算该电极与对角线之前的所有电极的相关系数
ref=read_csv(refPath)
maxvalueTrain = np.zeros(1)
t=0
for j in lparr[:num+1]:
if j==1 and t!=num:#对角线之前所有为1的目标电极
taget=read_csv(csvPathArr[t])
#参考电极与目标电极做互相关
# 进行循环目标电极的每个点
refspiketrain = np.zeros(50)
for r in ref:
rbegin = r - 0.05 # spike左边点
refspikeevery = []
for b in range(50):
bleft = rbegin + b * 0.002 # 每个小窗的时间
bright = rbegin + (b + 1) * 0.002
# bl=list(filter(lambda x: bleft
def Cal_first2067CrossMartix(csvPathArr,lparr,threeit):#并行计算函数
everowCoeff= pool.map(func,iterable)#初始数值映射
示例1:
# -*- coding:utf-8 -*-
import time
import multiprocessing
def job(x ,y):
"""
:param x:
:param y:
:return:
"""
return x * y
def job1(z):
"""
:param z:
:return:
"""
return job(z[0], z[1])
if __name__ == "__main__":
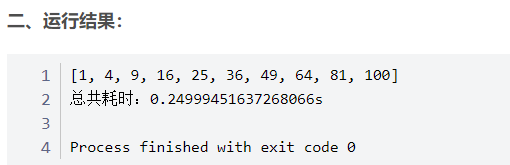
time1=time.time()
pool = multiprocessing.Pool(2)
data_list=[(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10)]
res = pool.map(job1,data_list)
time2=time.time()
print(res)
pool.close()
pool.join()
print(‘总共耗时:‘ + str(time2 - time1) + ‘s‘)
pool = multiprocessing.Pool(6)#核数(根据自己电脑核数进行修改)
import pandas as pd
import numpy as np
from sympy import DiracDelta#导入狄拉克函
from matplotlib import pyplot as plt
import os
import math
from time import *
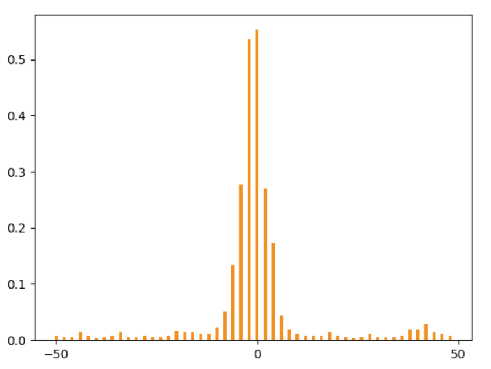
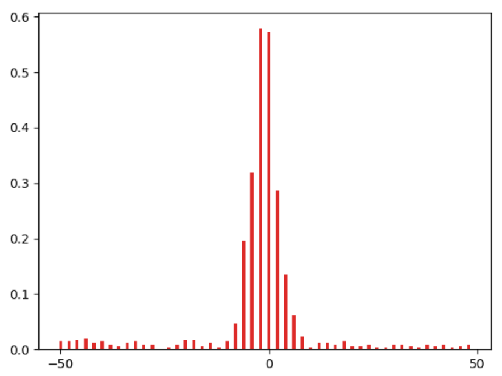
#测验某个spon中的多个电极
‘‘‘
#遍历该文件夹下所有.csv文件
def get_file(path): # 创建一个空列表
files = os.listdir(path)
list = []
for file in files:
if not os.path.isdir(path + file): # 判断该文件是否是一个文件夹
f_name = str(file)
# print(f_name)
tr = ‘\\‘ # 多增加一个斜杠
filename = path + tr + f_name
#filename = f_name
list.append(filename)#得到所有
return list
def get_sum(num1,num2,array):
count=0
for n in array:
if num1num2:
break
return count
def read_csv(csvfilePath):
data=pd.read_csv(csvfilePath,header=None)
data=np.array(data)
#data=np.round(data,3)
rd, cd = data.shape
csvdata = np.reshape(data, cd)
return csvdata
#测验两个电极
begin_time=time()
pcsv1=r‘E:\\数据文件\3-23Data(20211126)\CIRCLE\spon22-10\cont_Row_01_Col_05_nr.csv‘
pcsv2=r‘E:\\数据文件\3-23Data(20211126)\CIRCLE\spon22-10\cont_Row_01_Col_12_nr.csv‘
ref=read_csv(pcsv1)
maxvalueTrain = np.zeros(1)
taget=read_csv(pcsv2)
refspiketrain = np.zeros(50)
for r in ref:
rbegin = r - 0.05 # spike左边点
#rbegin = np.round(rbegin, 3)
refspikeevery = []
for b in range(50):
bleft = rbegin + b * 0.002 # 每个小窗的时间
bright = rbegin + (b + 1) * 0.002
# bl=list(filter(lambda x: bleft
import pandas as pd
import numpy as np
from sympy import DiracDelta#导入狄拉克函
from matplotlib import pyplot as plt
import os
import math
import multiprocessing # 导入多进程中的进程池
from functools import partial
from time import *
def get_sum(num1,num2,array):
count=0
for n in array:
if num1num2:
break
return count
#遍历该文件夹下所有.csv文件
def get_file(path): # 创建一个空列表
files = os.listdir(path)
list = []
for file in files:
if not os.path.isdir(path + file): # 判断该文件是否是一个文件夹
f_name = str(file)
# print(f_name)
tr = ‘\\‘ # 多增加一个斜杠
filename = path + tr + f_name
#filename = f_name
list.append(filename)#得到所有
return list
def get_csvarr(csvPath):
allFileNames = get_file(csvPath) # 获取4096个.csv
larr = np.array(allFileNames)
csvPathArr = np.reshape(larr, (larr.shape[0])) # 获取.csv路径数组
return csvPathArr
def get_learnArr(lpPath):
pdata = pd.read_csv(lpPath, header=None)
plarr = np.array(pdata[1:]) # 获取学习神经元的标签
plarr = np.reshape(plarr, (plarr.shape[0]))
return plarr
def read_csv(csvfilePath):
data=pd.read_csv(csvfilePath,header=None)
data=np.array(data)
data=np.round(data,3)
rd, cd = data.shape
csvdata = np.reshape(data, cd)
return csvdata
def Cal_allNeuronCrossMartix(csvPathArr,threeit):#refName代表参考电极的路径,csvPathArr代表电极csv路径,num代表电极序号,lpLable代表学习标签,lparr代表学习位置数组
refPath=threeit[0]#原始数据路径
num=int(threeit[1])#原始数据的序号
ref=read_csv(refPath)
maxvalueTrain = np.zeros(1)
t=0
for j in csvPathArr[:num+1]:
if t!=num:#对角线之前所有为1的目标电极
taget=read_csv(j)
#参考电极与目标电极做互相关
# 进行循环目标电极的每个点
refspiketrain = np.zeros(50)
for r in ref:
rbegin = r - 0.05 # spike左边点
refspikeevery = []
for b in range(50):
bleft = rbegin + b * 0.002 # 每个小窗的时间
bright = rbegin + (b + 1) * 0.002
bl = get_sum(bleft, bright, taget) # 每个窗内有几个符合的
if bl == 0:
refspikeevery.append(0) # 添加窗内的数字没有符合的
else:
refspikeevery.append(bl) # 有符合的添加符合的长度
refspiketrain = np.row_stack((refspiketrain, refspikeevery))
refspiketrain = np.delete(refspiketrain, 0, axis=0) # 删除第一行
a = []
for b in range(50):
p = refspiketrain[:, b] # 取出每一列进行相加
a.append(sum(p))
a = np.array(a)
c = math.sqrt(len(ref) * len(taget))
a = a / c
maxvalue = max(a)
maxvalueTrain = np.column_stack((maxvalueTrain, maxvalue))
else:
maxvalueTrain = np.column_stack((maxvalueTrain, 0))
t=t+1
row,col=maxvalueTrain.shape
lenzero=4096-col
fillminones=[]
for fillmum in range(lenzero):
fillminones.append(-1)
fillminones=np.array(fillminones)
fillminones= np.reshape(fillminones, (1, lenzero))
maxvalueTrain=np.column_stack((maxvalueTrain,fillminones))
print(num)
return maxvalueTrain
def main():
dataPath = r‘E:\\数据文件\3-23Data(20211126)\CIRCLE\SPON\spon22‘
csvPathArr = get_csvarr(dataPath)
coeffMatrix=np.zeros(4096)
num=np.array(range(4095))
itArr=np.row_stack((csvPathArr,num))#格式:(.csv路径,序号)
itArr=np.transpose(itArr)
iterable=[]
for row in itArr:
iterable.append(tuple(row))
#iterable=iterable[:13]
pool = multiprocessing.Pool(6)#核数
func=partial(Cal_allNeuronCrossMartix,csvPathArr)
everowCoeff= pool.map(func,iterable)#获得每一行的系数
for i in range(4095):
coeffMatrix=np.row_stack((coeffMatrix,everowCoeff[i]))
return coeffMatrix
if __name__ == "__main__":
begin_time=time()
coeffMatrix=main()
coeffMatrix=pd.DataFrame(data=coeffMatrix)
coeffMatrix.to_csv(r‘E:\\数据文件\3-23Data(20211126)\CIRCLE\spon22coeffmatrix\allnew221coeffmatrix.csv‘,index=False,header=None)
end_time=time()
run_time=end_time-begin_time
print(‘此程序运行时间:‘,run_time)
文章标题:使用Python实现并行运算处理数据
文章链接:http://soscw.com/index.php/essay/90391.html