Lucene
标签:apache alt 搜索 结构 索引 系统 取出 分词 bsp
1 什么是全文检索?
1.1 数据分类
- 我们生活中的数据总体分为两类:结构化数据和非结构化数据。
- 结构化数据:指的是具有固定格式和有限长度的数据。比如数据库的数据等。
- 非结构化数据:指的是不具有固定格式或非有限长度的数据,比如邮件、Word文档等磁盘上的文件。
1.2 结构化数据搜索
- 常见的结构化数据也就是数据库中的数据。在数据库中搜索很容易实现,通常都是使用SQL语句进行查询,而且能很快的得到查询结果。
- 为什么数据库搜索很容易?
- 因为数据库中的数据存储是由规律的,有行有列而且数据格式、长度都是固定的。
1.3 非结构化数据查询方法
1.3.1 顺序扫描法
- 所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的查询,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档是我们要找的文件,接着看下一个文件,直到扫描完所有的文件。例如利用windows的搜索也可以搜索文件内容,只是相当的慢。
1.3.2 全文检索
- 将非结构化数据的一部分信息提取出来,重新组织,使其变得具有一定的结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的母的。这部分从非结构化数据中提取的然后重新组织的信息,我们称之为索引。
- 例如:字典。字典的拼音表和部首检查字表就相当于字典的索引,对于每一个字的解释是非结构化的,如果字典没有拼音表或部首查字表,在茫茫辞海中找一个字只能顺序扫描。然而字的某些信息可以提取出来进行结构化处理,比如读音,就比较结构化,分声母和韵母,分别只有几种可以一一列举,于是将读音拿出来按一定的顺序排列,每一项读音都指向此字的详细解释的页数。我们搜索时按结构化的拼音搜到读音,然后按其指向的页数,便可找到我们非结构化的数据--对字的解释。
- 上面这种先建立索引,再对索引进行搜索的过程叫全文检索。
- 虽然创建索引的过程也是非常耗时的,但是索引一旦创建就可以多次使用,全文检索主要处理的是查询,所以耗时间创建索引是值得的。
1.4 如何实现全文检索
1.5 全文检索的应用场景
- 对于数据量大、数据结构不固定的数据可采用全文检索的方式进行搜索,比如百度、Google等搜索引擎、论坛站内搜索、电商网站等等。
2 使用Lucene实现全文检索的流程
2.1 Lucene简介
- Lucene是Apache下的一个开源的全文检索引擎工具包。提供了完整的查询引擎和索引引擎,部分文本分析引擎。
- Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便在目标系统中实现全文检索的功能。
2.2 索引和搜索的流程图
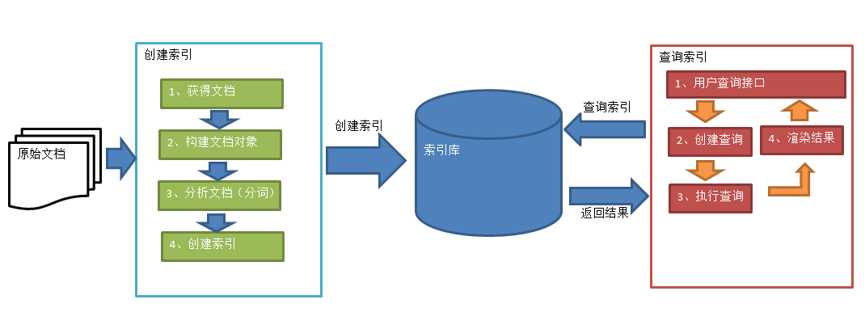
- 绿色表示创建索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:获取文档-->构建文档对象-->分析文档(对内容分词)-->创建索引。
- 红色表示查询索引过程,从索引库中搜索内容,搜索过程包括:
Lucene
标签:apache alt 搜索 结构 索引 系统 取出 分词 bsp
原文地址:https://www.cnblogs.com/xuweiweiwoaini/p/12336135.html
文章来自:
搜素材网的
编程语言模块,转载请注明文章出处。
文章标题:
Lucene
文章链接:http://soscw.com/index.php/essay/90648.html
评论