DirectX11 With Windows SDK--26 计算着色器:入门
2021-06-05 05:04
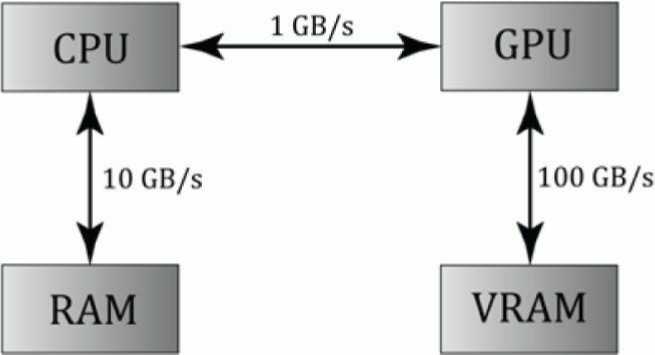
标签:erp 架构 invalid _for sources www. sizeof 针对 直接 现在开始迎来所谓的高级篇了,目前计划是计算着色器部分的内容视项目情况,大概会分3-5章来讲述。 DirectX11 With Windows SDK完整目录 Github项目源码 欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。 这里所使用的计算着色器实际上是属于DirectCompute的一部分,DirectCompute是一种应用程序编程接口(API),最初与DirectX 11 API 一起发布,但如果你的显卡只支持到特性等级10.x,那么你只能使用到计算着色器的有限功能,这里不讨论。 GPU通常被设计为从一个位置或连续的位置读取并处理大量的内存数据(即流操作),而CPU则被设计为专门处理随机内存的访问。 由于顶点数据和像素数据可以分开处理,GPU架构使得它能够高度并行,在处理图像上效率非常高。但是一些非图像应用程序也能够利用GPU强大的并行计算能力以获得效益。GPU用在非图像用途的应用程序可以称之为:通用GPU(GPGPU)编程。 GPU需要数据并行的算法才能从GPU的并行架构中获得优势,并不是所有的算法都适合用GPU来实现。对于大量的数据,我们需要保证它们都进行相似的操作以确保并行处理。比如顶点着色器都是对大量的顶点数据进行处理,而像素着色器也是对大量的像素片元进行处理。 对于GPGPU编程,用户通常需要从显存中获取运算结果,将其传回CPU。这需要从显存将结果复制到内存中,这样虽然速度会慢一些,但起码还是比直接在CPU运算会快很多。如果是用于图形编程的话倒是可以省掉数据传回CPU的时间,比如说我们要对渲染好的场景再通过计算着色器来进行一次模糊处理。 在Direct3D中,计算着色器也是一个可编程着色器,它并不属于渲染管线的一个直接过程。我们可以通过它对GPU资源进行读写操作,运行的结果通常会保存在Direct3D的资源中,我们可以将它作为结果显示到屏幕,可以给别的地方作为输入使用,甚至也可以将它保存到本地。 在GPU编程中,我们编写的着色器程序会同时给大量的线程运行,可以将这些线程按网格来划分成线程组。一个线程组由一个多处理器来执行,如果你的GPU有16个多处理器,你会想要把问题分解成至少16个线程组以保证每个多处理器都工作。为了获取更好的性能,让每个多处理器来处理至少2个线程组是一个比较不错的选择,这样当一个线程组在等待别的资源时就可以先去考虑完成另一个线程组的工作。 每个线程组都会获得共享内存,这样每个线程都可以访问它。但是不同的线程组不能相互访问对方获得的共享内存。 线程同步操作可以在线程组中的线程之间进行,但处于不同线程组的两个线程无法被同步。事实上,我们没有办法控制不同线程组的处理顺序,毕竟线程组可以在不同的多处理器上执行。 一个线程组由N个线程组成。硬件实际上会将这些线程划分成一系列warps(一个warp包含32个线程),并且一个warp由SIMD32中的多处理器进行处理(32个线程同时执行相同的指令)。在Direct3D中,你可以指定一个线程组不同维度下的大小使得它不是32的倍数,但是出于性能考虑,最好还是把线程组的维度大小设为warp的倍数。 将线程组的大小设为256看起来是个比较好的选择,它适用于大量的硬件情况。修改线程组的大小意味着你还需要修改需要调度的线程组数目。 注意:NVIDIA硬件中,每个warp包含32个线程。而ATI则是每个wavefront包含64个线程。warp或者wavefront的大小可能随后续硬件的升级有所修改。 方法如下: 可以看到上面列出了X, Y, Z三个维度,说明线程组本身是可以3维的。当前例子的一个线程组包含了8x8x1个线程,而线程组数目为3x2x1,即我们进行了这样的调用: 现在我们有这两张图片,我想要将它混合并将结果输出到一张图片: 下面的这个着色器负责对两个纹理的像素颜色进行分量乘法运算。 上面的代码有如下需要注意的: 如果使用1D纹理,线程修饰符通常为 如果使用2D纹理,线程修饰符通常为 2D纹理X和Y的值会影响你在调度线程组时填充的参数 注意: 留意上面着色器代码中的类型 此外,UAV不支持 其中 从上表可以得知DXGI_FORMAT枚举值的后缀要和HLSL的类型对应(浮点型对应浮点型,整型对应整型,规格化浮点型对应规格化浮点型),否则可能会引发下面的错误(这里举 D3D11 ERROR: ID3D11DeviceContext::Dispatch: The resource return type for component 0 declared in the shader code (FLOAT) is not compatible with the resource type bound to Unordered Access View slot 0 of the Compute Shader unit (UNORM). This mismatch is invalid if the shader actually uses the view (e.g. it is not skipped due to shader code branching). [ EXECUTION ERROR #2097372: DEVICE_UNORDEREDACCESSVIEW_RETURN_TYPE_MISMATCH] 由于 现在我们回到C++代码,现在需要创建一个2D纹理,然后在此基础上再创建无序访问视图作为着色器输出。 观察上面的代码,如果我们想要让纹理绑定到无序访问视图,就需要提供 注意:如果你还为纹理创建了着色器资源视图,那么UAV和SRV不能同时绑定到渲染管线上。 调度过程实现如下: 由于我们的位图是512x512x1大小,一个线程组的线程布局为16x16x1,线程组的数目自然就是32x32x1了。如果调度的线程组宽度或高度不够,输出的位图也不完全。而如果提供了过宽或过高的线程组并不会影响运行结果,只是提供的线程组资源过多有些浪费而已。 最后通过ScreenGrab库将纹理保存到文件,就可以结束程序了。 运行结束后,可以打开 那么问题来了,如果我想要输出 修改后的着色器代码如下: 注意:如果你使用了HLSL Tools For Visual Studio插件,它不认 运行的图片显示结果基本上是一样的,只是输出的纹理格式不太一样: 从上面的例子可以看到,我们能够使用2D索引来指定纹理的某一像素。如果2D索引越界访问,在计算着色器中是拥有良好定义的:读取越界资源将返回0,尝试写入越界资源的操作将不会执行。 但是这种采样只针对mip等级为0的纹理子资源,如果我们想指定其它mip等级的纹理子资源,可以使用 返回值R视纹理数据类型而定。 用法如下: 不过我们的演示程序用到的纹理Mip等级都为1,这里就不在代码端演示了。 纹理的 当LOD为整数时,指定的就是具体某个mip等级的纹理,但如果LOD为浮点数,如3.3f,则会对mip等级为3和4的纹理子资源都进行一次采样,然后根据小数部分进行线性插值求得最终的插值颜色。 用法如下: 粗体字为自定义题目 DirectX11 With Windows SDK完整目录 Github项目源码 欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。 DirectX11 With Windows SDK--26 计算着色器:入门 标签:erp 架构 invalid _for sources www. sizeof 针对 直接 原文地址:https://www.cnblogs.com/lonelyxmas/p/10811453.html前言
概述
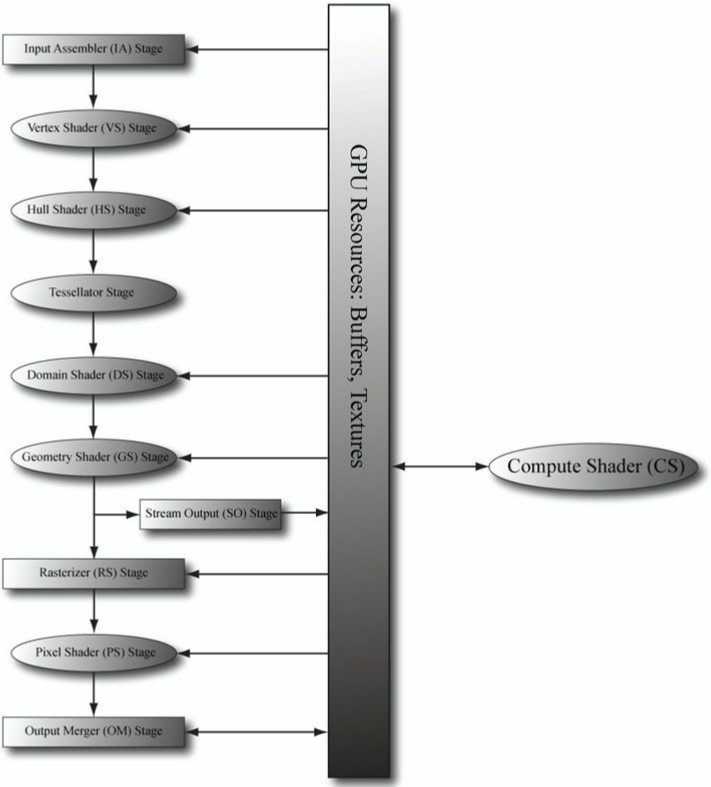
线程和线程组
ID3D11DeviceContext::Dispatch方法--调度线程组执行计算着色器程序
void ID3D11DeviceContext::Dispatch(
UINT ThreadGroupCountX, // [In]X维度下线程组数目
UINT ThreadGroupCountY, // [In]Y维度下线程组数目
UINT ThreadGroupCountZ); // [In]Z维度下线程组数目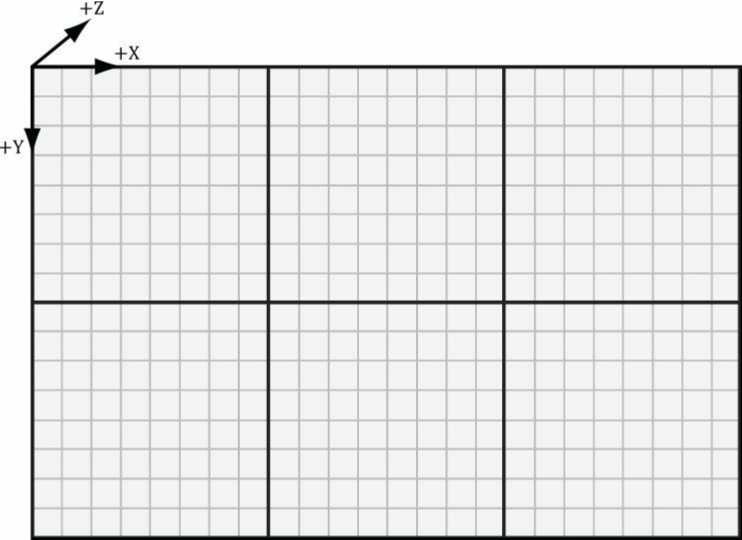
m_pd3dDeviceContext->Dispatch(3, 2, 1);第一份计算着色器程序


Texture2D g_TexA : register(t0);
Texture2D g_TexB : register(t1);
RWTexture2D
Texture2D仅能作为输入,但RWTexture2D类型支持读写,在本样例中主要是用于输出RWTexture2D使用时也需要指定寄存器,u说明使用的是无序访问视图寄存器[numthreads(X, Y, Z)]修饰符指定了一个线程组包含的线程数目,以及在3D网格中的布局SV_DispatchThreadID是当前线程在3D网格中所处的位置,每个线程都有独立的SV_DispatchThreadID
Texture2D除了使用Sample方法来获取像素外,还支持通过索引的方式来指定像素[numthreads(X, 1, 1)]或[numthreads(1, Y, 1)][numthreads(X, Y, 1)],即第三维度为1
cs_4_x下,一个线程组的最大线程数为768,且Z的最大值为1.cs_5_0下,一个线程组的最大线程数为1024,且Z的最大值为64.纹理输出与无序访问视图
RWTexture2D,你可以对他进行像素写入,也可以从中读取像素。不过模板参数类型填写就比较讲究了。我们需要保证纹理的数据格式和RWTexture2D的模板参数类型一致,这里使用下表来描述比较常见的纹理数据类型和HLSL类型的对应关系:
DXGI_FORMAT
HLSL类型
DXGI_FORMAT_R32_FLOAT
float
DXGI_FORMAT_R32G32_FLOAT
float2
DXGI_FORMAT_R32G32B32A32_FLOAT
float4
DXGI_FORMAT_R32_UINT
uint
DXGI_FORMAT_R32G32_UINT
uint2
DXGI_FORMAT_R32G32B32A32_UINT
uint4
DXGI_FORMAT_R32_SINT
int
DXGI_FORMAT_R32G32_SINT
int2
DXGI_FORMAT_R32G32B32A32_SINT
int4
DXGI_FORMAT_R16G16B16A16_FLOAT
float4
DXGI_FORMAT_R8G8B8A8_UNORM
unorm float4
DXGI_FORMAT_R8G8B8A8_SNORM
snorm float4
DXGI_FORMAT_B8G8R8A8_UNORMunorm float表示的是一个32位无符号的,规格化的浮点数,可以表示范围0到1
而与之对应的snorm float表示的是32位有符号的,规格化的浮点数,可以表示范围-1到1DXGI_FORMAT为unorm,HLSL类型为float的例子):
DXGI_FORMAT的部分格式比较紧凑,HLSL中能表示的最小类型通常又比较大。比如DXGI_FORMAT_R16G16B16A16_FLOAT和float4,个人猜测HLSL的类型为了能传递给DXGI_FORMAT,允许做丢失精度的同类型转换。bool GameApp::InitResource()
{
HR(CreateDDSTextureFromFile(m_pd3dDevice.Get(), L"Texture\\flare.dds",
nullptr, m_pTextureInputA.GetAddressOf()));
HR(CreateDDSTextureFromFile(m_pd3dDevice.Get(), L"Texture\\flarealpha.dds",
nullptr, m_pTextureInputB.GetAddressOf()));
// 创建用于UAV的纹理,必须是非压缩格式
D3D11_TEXTURE2D_DESC texDesc;
texDesc.Width = 512;
texDesc.Height = 512;
texDesc.MipLevels = 1;
texDesc.ArraySize = 1;
texDesc.Format = DXGI_FORMAT_R32G32B32A32_FLOAT;
texDesc.SampleDesc.Count = 1;
texDesc.SampleDesc.Quality = 0;
texDesc.Usage = D3D11_USAGE_DEFAULT;
texDesc.BindFlags = D3D11_BIND_SHADER_RESOURCE |
D3D11_BIND_UNORDERED_ACCESS;
texDesc.CPUAccessFlags = 0;
texDesc.MiscFlags = 0;
HR(m_pd3dDevice->CreateTexture2D(&texDesc, nullptr, m_pTextureOutputA.GetAddressOf()));
texDesc.Format = DXGI_FORMAT_R8G8B8A8_UNORM;
HR(m_pd3dDevice->CreateTexture2D(&texDesc, nullptr, m_pTextureOutputB.GetAddressOf()));
// 创建无序访问视图
D3D11_UNORDERED_ACCESS_VIEW_DESC uavDesc;
uavDesc.Format = DXGI_FORMAT_R32G32B32A32_FLOAT;
uavDesc.ViewDimension = D3D11_UAV_DIMENSION_TEXTURE2D;
uavDesc.Texture2D.MipSlice = 0;
HR(m_pd3dDevice->CreateUnorderedAccessView(m_pTextureOutputA.Get(), &uavDesc,
m_pTextureOutputA_UAV.GetAddressOf()));
uavDesc.Format = DXGI_FORMAT_R8G8B8A8_UNORM;
HR(m_pd3dDevice->CreateUnorderedAccessView(m_pTextureOutputB.Get(), &uavDesc,
m_pTextureOutputB_UAV.GetAddressOf()));
// 创建计算着色器
ComPtrD3D11_BIND_UNORDERED_ACCESS绑定标签。
ID3D11DeviceContext::CSSetUnorderedAccessViews--计算着色阶段设置无序访问视图
void ID3D11DeviceContext::CSSetUnorderedAccessViews(
UINT StartSlot, // [In]起始槽,值与寄存器对应
UINT NumUAVs, // [In]UAV数目
ID3D11UnorderedAccessView * const *ppUnorderedAccessViews, // [In]UAV数组
const UINT *pUAVInitialCounts // [In]忽略
);
void GameApp::Compute()
{
assert(m_pd3dImmediateContext);
m_pd3dImmediateContext->CSSetShaderResources(0, 1, m_pTextureInputA.GetAddressOf());
m_pd3dImmediateContext->CSSetShaderResources(1, 1, m_pTextureInputB.GetAddressOf());
// DXGI Format: DXGI_FORMAT_R32G32B32A32_FLOAT
// Pixel Format: A32B32G32R32
m_pd3dImmediateContext->CSSetShader(m_pTextureMul_R32G32B32A32_CS.Get(), nullptr, 0);
m_pd3dImmediateContext->CSSetUnorderedAccessViews(0, 1, m_pTextureOutputA_UAV.GetAddressOf(), nullptr);
m_pd3dImmediateContext->Dispatch(32, 32, 1);
// DXGI Format: DXGI_FORMAT_R8G8B8A8_SNORM
// Pixel Format: A8B8G8R8
m_pd3dImmediateContext->CSSetShader(m_pTextureMul_R8G8B8A8_CS.Get(), nullptr, 0);
m_pd3dImmediateContext->CSSetUnorderedAccessViews(0, 1, m_pTextureOutputB_UAV.GetAddressOf(), nullptr);
m_pd3dImmediateContext->Dispatch(32, 32, 1);
HR(SaveDDSTextureToFile(m_pd3dImmediateContext.Get(), m_pTextureOutputA.Get(), L"Texture\\flareoutputA.dds"));
HR(SaveDDSTextureToFile(m_pd3dImmediateContext.Get(), m_pTextureOutputB.Get(), L"Texture\\flareoutputB.dds"));
MessageBox(nullptr, L"请打开Texture文件夹观察输出文件flareoutputA.dds和flareoutputB.dds", L"运行结束", MB_OK);
}flareoutputA.dds查看结果(建议使用DxTex打开):
DXGI_FORMAT_R8G8B8A8_UNORM的纹理,那应该怎么做呢?
DXGI_FORMAT换成DXGI_FORMAT_R8G8B8A8_UNORM,连同UAV的Format也要替换RWTexture2D类型替换成RWTexture2D类型Texture2D gTexA : register(t0);
Texture2D gTexB : register(t1);
RWTexture2D
unorm类型,从而引发所谓的语法错误提示。你可以直接无视去编译项目,它还是能成功编译出着色器的。
纹理子资源的采样和索引
mip.operator[][]方法:R mips.Operator[][](
in uint mipSlice, // [In]mip切片值
in uint2 pos // [In]2D索引
);gOutput.mip[gMipSlice][DTid.xy] =
(unorm float4)(gTexA.mip[gMipSlice][DTid.xy] * gTexB.mip[gMipSlice][DTid.xy]);Sample方法通常情况下你是不知道它具体选择的是哪些Mip等级的纹理子资源来进行采样,具体的行为交给采样器状态来决定。但是我们可以使用SampleLevel方法来指定要对纹理的哪个mip等级的子资源进行采样:R SampleLevel(
in SamplerState S, // [In]采样器状态
in float2 Location, // [In]纹理坐标
in float LOD // [In]mip等级
);float4 texColor = gTex.SampleLevel(gSam, pIn.Tex, 0.0f); // 使用第一个mip等级的纹理子资源练习题
ID3D11DeviceContext::Dispatch的参数,观察运行结果
上一篇:C# 修改配置文件
文章标题:DirectX11 With Windows SDK--26 计算着色器:入门
文章链接:http://soscw.com/index.php/essay/90727.html