预测算法之多元线性回归
2021-06-07 06:05
标签:列表 保留 学习 sum 测试 目标 spl cat 删除 在机器学习里面,常见的预测算法有以下几种: 本篇博客,笔者将为大家主要介绍多元线性回归的相关内容。 线性回归是基础且广泛使用的预测分析算法,它允许在数字输入和输出值之间建立关系(不能用于分类数据)。简而言之,我们的目标是将复杂形式显示的实际值显示为如下图中的单线。 具有一个因变量和一个自变量的回归方程的最简单形式由如下公式组成: 误差量是真实值中的点与直线之间的距离。 例如,下面我们通过一个案例,读取一个包含按月销售额的文件,将进行线性回归月销售额的预测,代码如下所示: 执行上述代码,结果显示如下: 多元线性回归是使用最广发的线性回归分析。在一元线性回归中,它使用了一个因变量和一个自变量。在多元线性回归中可以与多个独立变量一起使用。 例如,在线性回归中,我们按月预测销售量。在多元线性回归中,我们可以根据体重、年龄和身高数据估算鞋子的大小。因此,此时体重、年龄和身高是自变量。 f 虚拟变量可以定义为表示变量的另一个变量,比如上面性别列使用OneHotEncoder从类别数据转换为数值数据。如下所示: 转换之后,我们将列数从4列增加到了6列。OneHotEncoder结果包含在m和f列中,但是,如果我们将此数据集直接提供给机器学习算法,则我们的结果可能是错误的,因为这6列中的3列(性别、m、f)本质是相同的,也就是说,其中一个的更改会影响另一个列值。 为了避免这种情况,我们必须减去3列中的两列(性别、m、f),并将数据集提供给机器学习算法。裁剪后的数据列表如下所示: P值即概率,反应某一时间发生的可能性大小。统计学根据显著性检验方法所得到的P值,一般以P小于0.05为显著,P小于0.01为非常显著,其含义是样本间的差异由抽样误差所致的概率小于0.05或者0.01。在线性回归中,P小于0.01(或者0.05)表示两个变量非常显著线性相关。 下面,我们通过执行示例代码,通过获取年龄、国家、性别和体重数据,并尝试预测人的身高。代码如下所示: 执行结果如下: 每个变量都会系统产生影响,有些变量对系统有很大影响,而有些则较少。消除对系统影响很小的自变量,使我们可以构建更好的模型。我们可以使用向后淘汰方法创建更好的模型。 运行如下代码: 输出结果如下所示: 在图中,P > | t | 这一列是我们的P值,在x5对应的列高于我们确定的P值(0.05),接下来,将删除此列,然后再次运行该程序,这个过程一直持续到 P > | t | 这列中所有值都小于P值为止。 数据有时是非线性的,在这种情况下,将使用多项式回归。 在上图公式中,h是多项式的次数。它被称为h的二次方、三次方、四次方。 代码如下所示: 输出结果如下: 更改不同的度数参数后的结果如下所示: 需要注意的是,在非线性回归中,不可以用P值检验相关显著性,因为在非线性回归中,残差均值平方不再是误差方差的无偏估计,因为不能使用线性模型的检验方法来检验非线性模型,从而并不能用F统计量及其P值进行检验。 这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉! 另外,博主出书了《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。 预测算法之多元线性回归 标签:列表 保留 学习 sum 测试 目标 spl cat 删除 原文地址:https://www.cnblogs.com/smartloli/p/14588788.html1.概述
2.内容
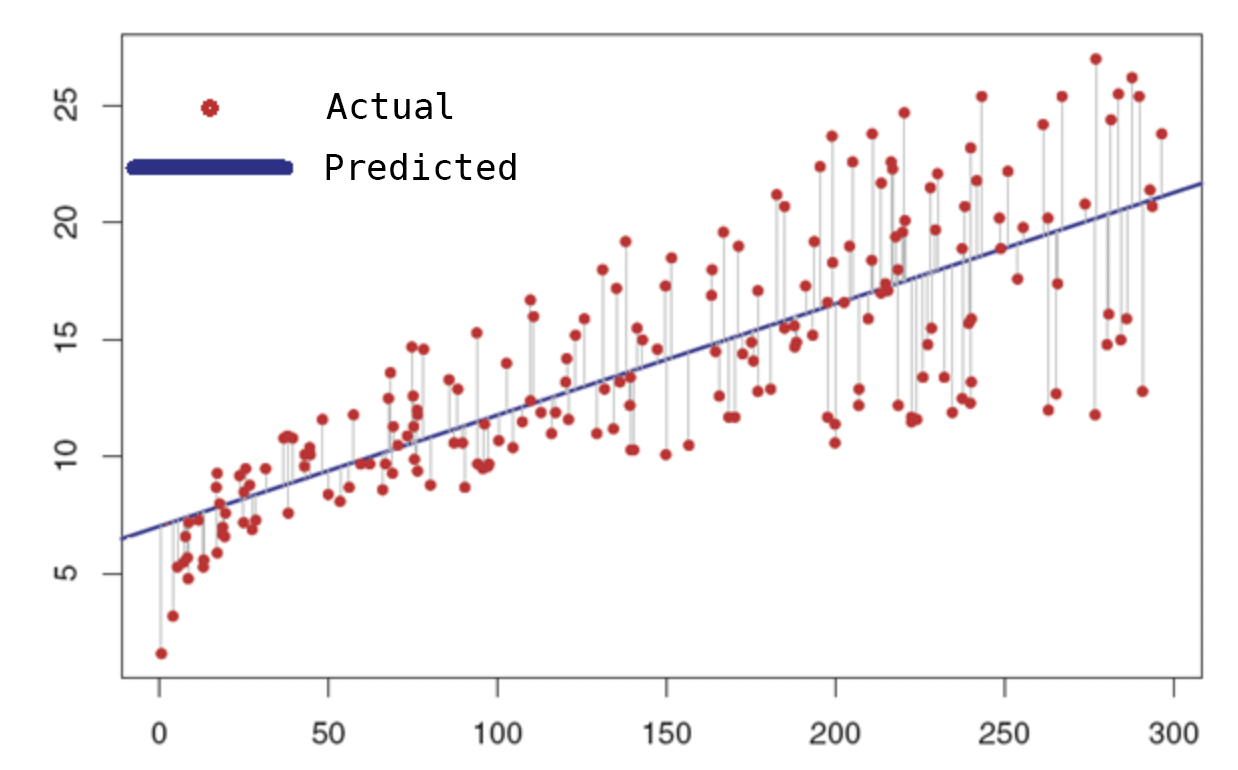
2.1 一元线性回归
y = ax + b
y=因变量,a=系数,x=自变量,c=常数
# 读取csv文件
import pandas as pd
# 创建2D图形
import matplotlib.pyplot as plt
# 已读取csv文件
data = pd.read_csv(‘/Users/dengjie/Desktop/python/predicted/satislar.csv‘)
# 将名为月份的列分配给变量
Aylar = data[[‘Aylar‘]]
# 将名为Sales的列分配给变量
Satislar = data[[‘Satislar‘]]
# 使用#sklearn库,我们导入了将数据分为测试和训练的函数
from sklearn.model_selection import train_test_split
# 我们将数据集分为测试和训练
# test_size = 0.33 数据
# x_train,y_train = 月和销售的训练集
# x_test, y_test = 月和Satislar的测试集
# test_size = 训练的数据集的2/3 1/3将保留用于测试(0.33)
x_train, x_test, y_train, y_test = train_test_split(Aylar,Satislar,test_size=0.33,random_state=0)
# 我们使用#sklearn库包含LinearRegression类
from sklearn.linear_model import LinearRegression
# 我们从类中创建一个对象
lr = LinearRegression()
# 我们通过提供训练数据集来训练机器
lr.fit(x_train,y_train)
# 通过提供测试集,我们使Aylar可以预测Satislar
tahmin = lr.predict(x_test)
# 我们按索引号对数据进行排序,以在图表上定期显示它们
x_train = x_train.sort_index()
y_train = y_train.sort_index()
# 我们以图形形式打印屏幕
plt.plot(x_train,y_train)
plt.plot(x_test,tahmin)
plt.show()
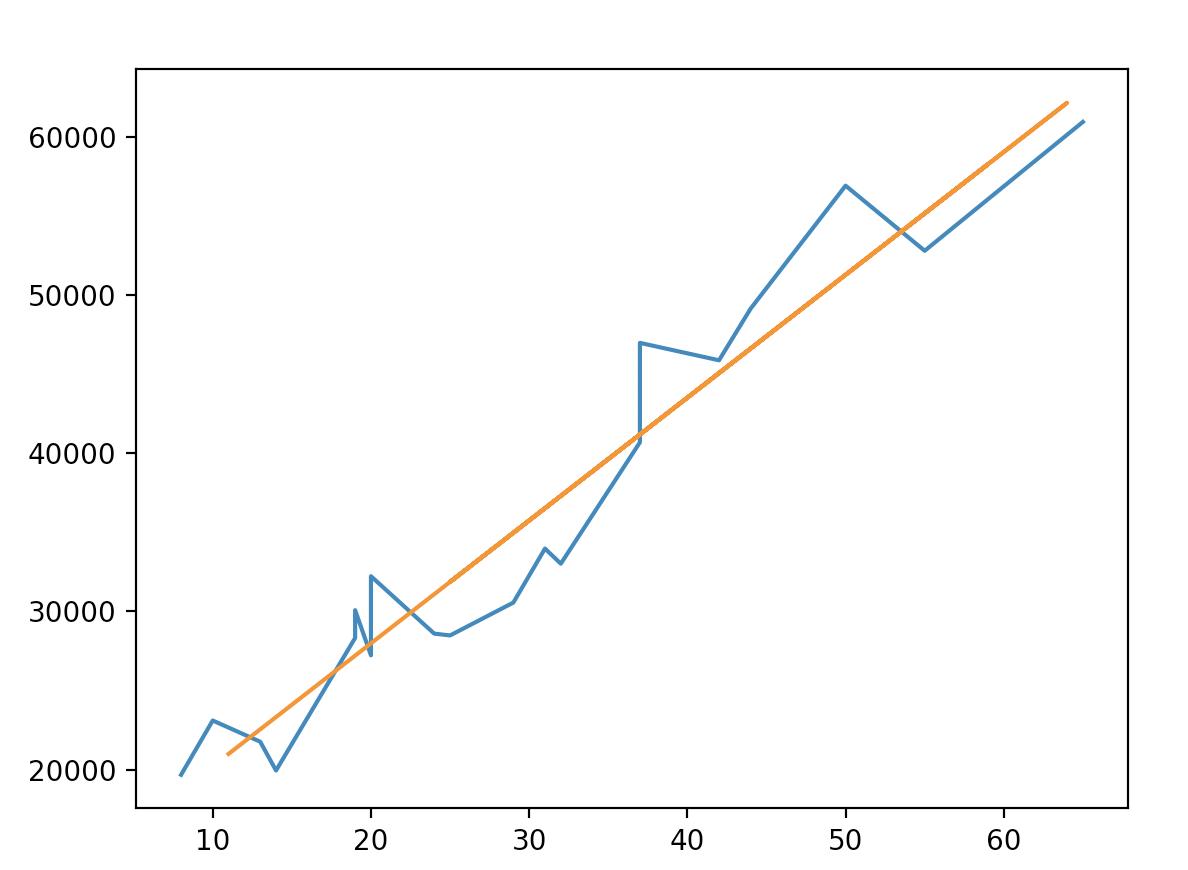
2.2 多元线性回归
y = b0 + ax1 +bx2 + cax3 + d
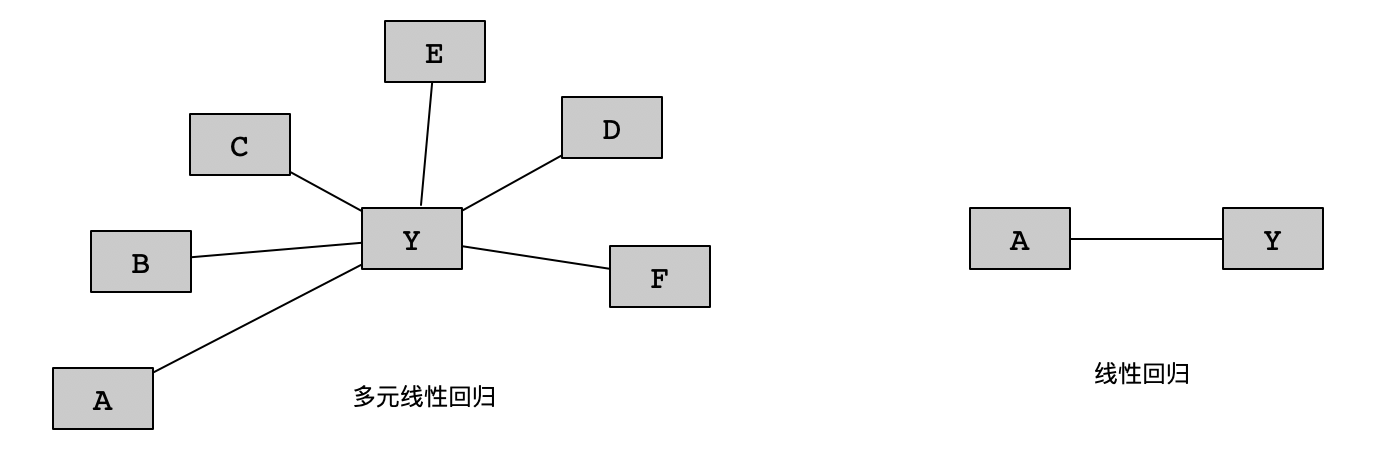
2.2.1 虚拟变量
年龄
身高
体重
性别
20
175
82
m
35
182
65
45
168
73
f
32
176
42
m
m
f
1
0
0
1
0
1
1
0
年龄
身高
体重
体重
m
f
20
175
82
m
1
0
35
182
65
f
0
1
45
168
73
f
0
1
32
176
42
m
1
0
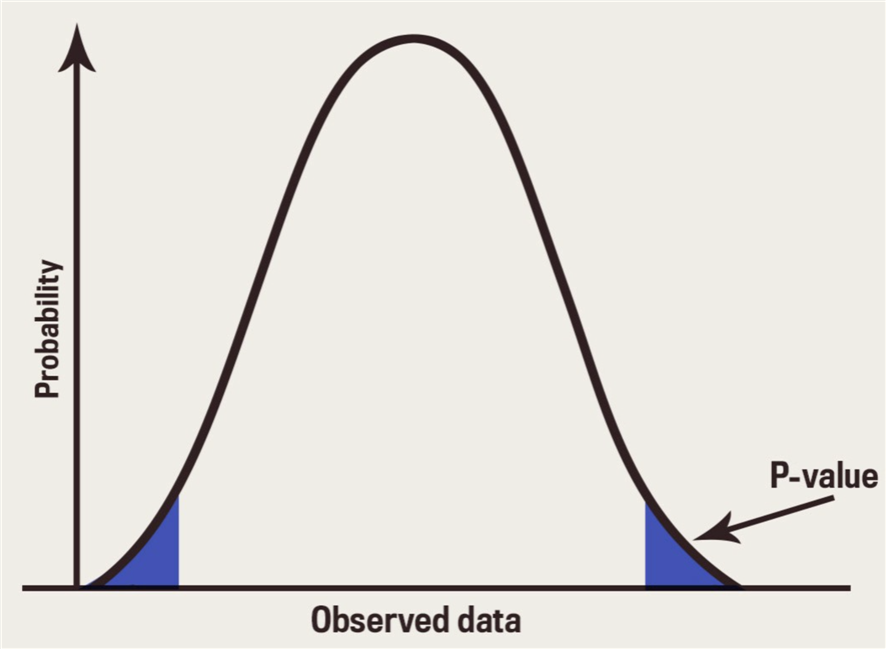
2.2.2 P值
# 读取csv文件
import pandas as pd
# 已读取csv文件数据
data = pd.read_csv(‘/Users/dengjie/Desktop/python/predicted/veriler.csv‘)
# 要应用多元线性回归,我们将列分配给变量,以将分类数据转换为数值
cinsiyet = data.iloc[:,-1:].values
# 要应用多元线性回归,我们将列分配给变量,以将分类数据转换为数值
ulkeler = data.iloc[:,0:1].values
# 我们将要猜测的列的值分配给一个变量
boy = data.iloc[:,1:2].values
# 导入LabelEncoder类
from sklearn.preprocessing import LabelEncoder
# 我们从LabelEncoder类派生了一个对象
lb = LabelEncoder()
# 我们执行了编码过程。现在,性别和国家/地区列为数字值
cinsiyet[:,0] = lb.fit_transform(cinsiyet[:,0])
ulkeler[:,0] = lb.fit_transform(ulkeler[:,0])
# 我们导入了OneHotEncoder类
from sklearn.preprocessing import OneHotEncoder
# 我们从#OneHotEncoder类派生了一个对象
ohe = OneHotEncoder()
# 使用#OneHotEncoder,我们将数字列分为1和0组成的列
cinsiyet = ohe.fit_transform(cinsiyet.reshape(-1,1)).toarray()
ulkeler = ohe.fit_transform(ulkeler.reshape(-1,1)).toarray()
# 我们创建了DataFrame来重组数据
dfCinsiyet = pd.DataFrame(data=cinsiyet[:,:1],index=range(len(cinsiyet)),columns=[‘cinsiyet‘,])
dfUlkeler = pd.DataFrame(data=ulkeler,index=range(len(ulkeler)),columns=[‘fr‘,‘tr‘,‘us‘])
# 我们合并了数据
preData = pd.concat([dfUlkeler,data.iloc[:,2:4],dfCinsiyet],axis=1)
# 我们将数据集分为测试和训练
# x_train,y_train = 训练集
# x_test, y_test = 测试集
# test_size = 训练的数据集的2/3 1/3将保留用于测试(0.33)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(preData,boy,test_size=0.33,random_state=0)
# 我们使用#sklearn库包含LinearRegression类
from sklearn.linear_model import LinearRegression
# 我们从#LinearRegression类创建一个对象
lr = LinearRegression()
# 我们通过提供训练数据集来训练机器
lr.fit(x_train,y_train)
# 通过提供#测试集,我们使我们训练的机器能够生成估计值
result = lr.predict(x_test)
print(result)
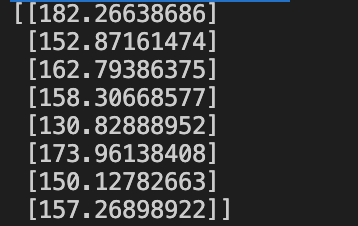
2.2.3 向后淘汰
# 读取csv文件
import pandas as pd
# 已读取csv文件数据
data = pd.read_csv(‘/Users/dengjie/Desktop/python/predicted/veriler.csv‘)
# 要应用多元线性回归,我们将列分配给变量,以将分类数据转换为数值
cinsiyet = data.iloc[:,-1:].values
# 要应用多元线性回归,我们将列分配给变量,以将分类数据转换为数值
ulkeler = data.iloc[:,0:1].values
# 我们将要猜测的列的值分配给一个变量
boy = data.iloc[:,1:2].values
# 导入LabelEncoder类
from sklearn.preprocessing import LabelEncoder
# 我们从LabelEncoder类派生了一个对象
lb = LabelEncoder()
# 我们执行了编码过程。现在,性别和国家/地区列为数字值
cinsiyet[:,0] = lb.fit_transform(cinsiyet[:,0])
ulkeler[:,0] = lb.fit_transform(ulkeler[:,0])
# 我们导入了OneHotEncoder类
from sklearn.preprocessing import OneHotEncoder
# 我们从#OneHotEncoder类派生了一个对象
ohe = OneHotEncoder()
# 使用#OneHotEncoder,我们将数字列分为1和0组成的列
cinsiyet = ohe.fit_transform(cinsiyet.reshape(-1,1)).toarray()
ulkeler = ohe.fit_transform(ulkeler.reshape(-1,1)).toarray()
# 我们创建了DataFrame来重组数据
dfCinsiyet = pd.DataFrame(data=cinsiyet[:,:1],index=range(len(cinsiyet)),columns=[‘cinsiyet‘,])
dfUlkeler = pd.DataFrame(data=ulkeler,index=range(len(ulkeler)),columns=[‘fr‘,‘tr‘,‘us‘])
# 我们合并了数据
preData = pd.concat([dfUlkeler,data.iloc[:,2:4],dfCinsiyet],axis=1)
# 我们将数据集分为测试和训练
# x_train,y_train = 训练集
# x_test, y_test = 测试集
# test_size = 训练的数据集的2/3 1/3将保留用于测试(0.33)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(preData,boy,test_size=0.33,random_state=0)
# 我们使用#sklearn库包含LinearRegression类
from sklearn.linear_model import LinearRegression
# 我们从#LinearRegression类创建一个对象
lr = LinearRegression()
# 我们通过提供训练数据集来训练机器
lr.fit(x_train,y_train)
# 通过提供#测试集,我们使我们训练的机器能够生成估计值
result = lr.predict(x_test)
print(result)
# 我们导入了必要的库
import statsmodels.api as sm
import numpy as np
# 我们在预处理数据中创建了一个列,并将1分配给所有值
X = np.append(arr=np.ones((len(preData),1)).astype(int),values=preData,axis=1)
# 我们处理了每一列。通过玩这部分,我们可以开发出最佳模型
X_l = preData.iloc[:,[0,1,2,3,4,5]].values
# endog = 预测的部分
# exog = 因变量
r = sm.OLS(endog=boy,exog=X_l).fit()
# 输出
print(r.summary())
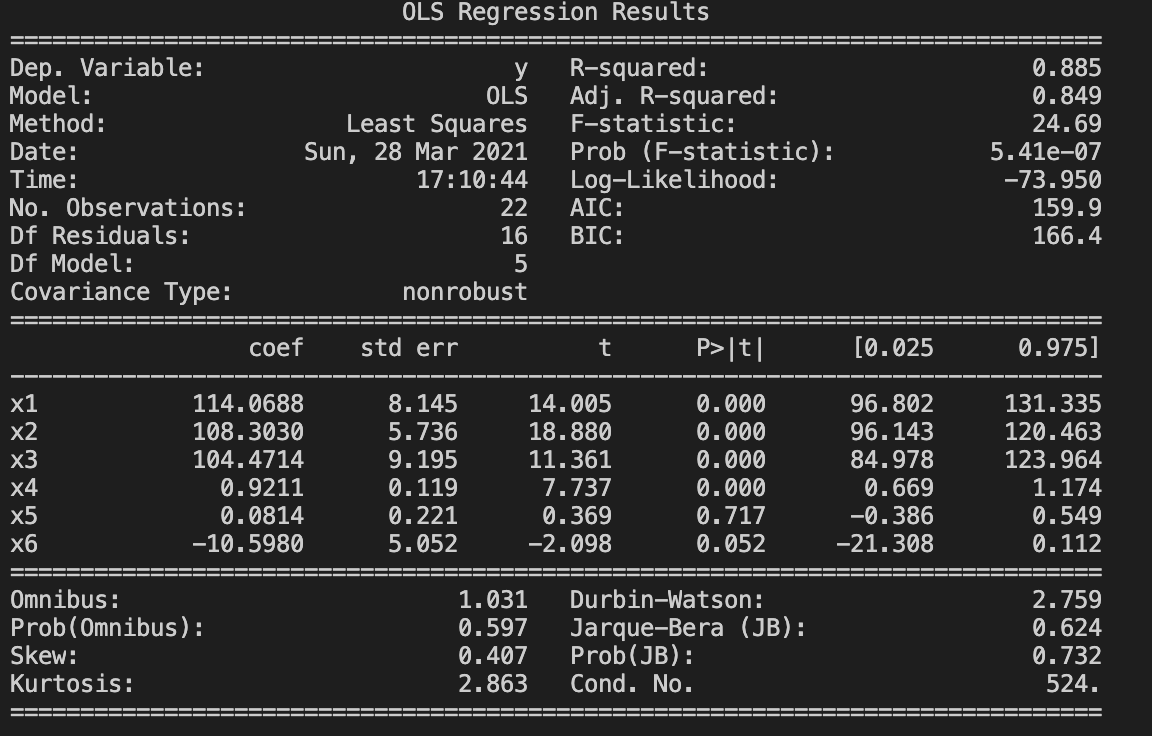
2.3 非线性下的多项式回归

# 读取csv文件
import pandas as pd
# 绘制图形
import matplotlib.pyplot as plt
# 加载数据
data = pd.read_csv(‘/Users/dengjie/Desktop/python/predicted/maaslar.csv‘)
# 将训练列的值分配给一个变量
egitim = data.iloc[:, 1:2].values
# 将maas列的值分配给一个变量
maas = data.iloc[:, -1:].values
# 导入了LinearRegression和PolynomialFeatures类
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
# 从LinearRegression类生成了一个对象
lr = LinearRegression()
# 我们从#PolynomialFeatures类创建了一个对象
# 这里的度数参数是多项式的度数
# 如果我们给#度部分加1,将会画一条直线
# 度增加得越多,我们得到的结果就越准确
poly = PolynomialFeatures(degree=4)
# 在训练机器之前,我们使用PolynomialFeatures转换训练列中的值
egitim_poly = poly.fit_transform(egitim)
# 开始训练
lr.fit(egitim_poly, maas)
# 在训练机器后做出预测
predict = lr.predict(egitim_poly)
# 以图形形式打印屏幕
plt.scatter(egitim, maas, color=‘red‘)
plt.plot(egitim, predict, color=‘blue‘)
plt.show()
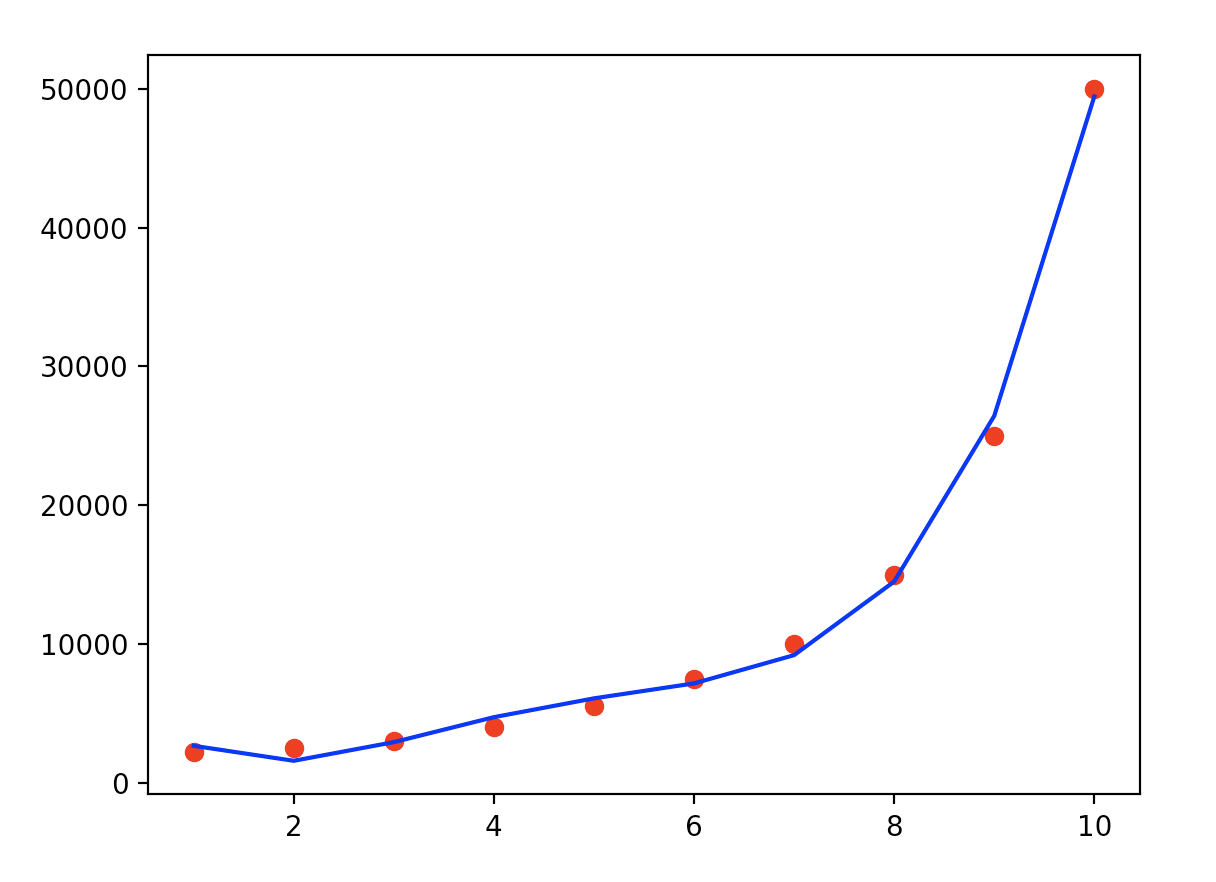
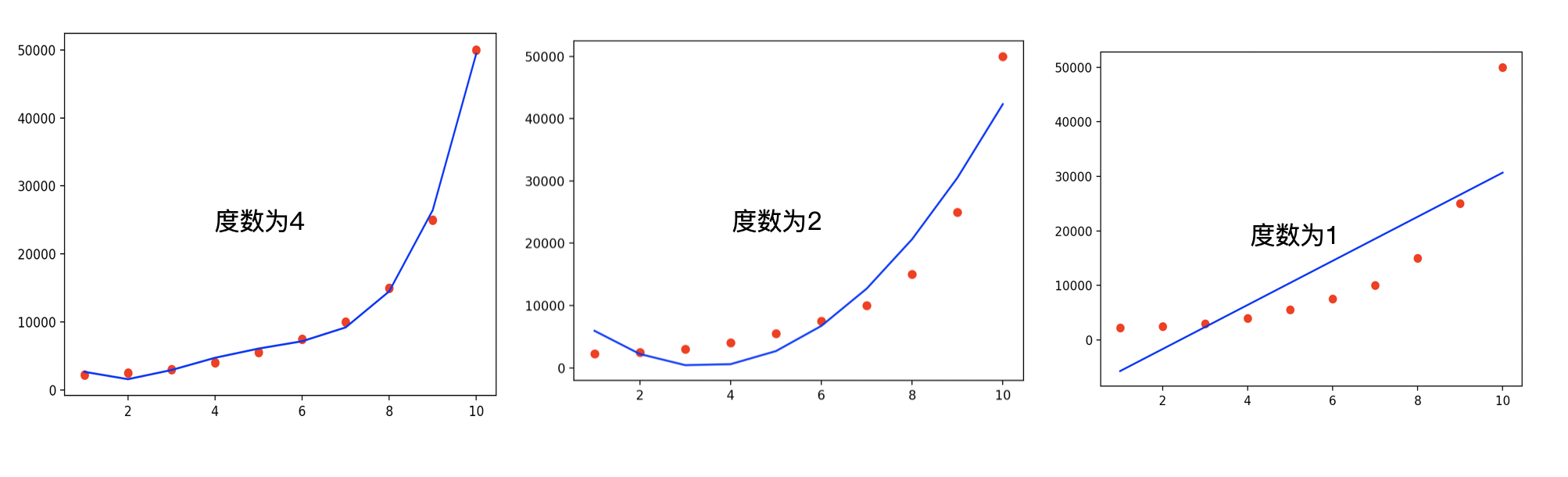
3.总结
4.结束语
上一篇:Java入门
下一篇:c++之一个方便的日志库