【论文笔记】Leveraging Datasets with Varying Annotations for Face Alignment via Deep Regression Network
2021-06-07 16:05
參考文献:
Zhang J, Kan M, Shan S, et al. Leveraging Datasets With Varying Annotations for Face Alignment via Deep Regression Network[C]//Proceedings of the IEEE International Conference on Computer Vision. 2015: 3801-3809.
简单介绍
眼下网上发布的人脸关键点的数据集非常多,但标注标准却往往不统一、标定点数也不尽同样。将这些数据合并起来非常重要,可是训练一个统一的模型却比較困难。ICCV 2015的这篇文章提出了一种基于深度回归网络(deep regression network)和稀疏形状回归方法,可以在不同点数的数据集上训练一个统一的关键点检測模型。同一时候可以取得比单个训练集更好的结果。
算法介绍
1. 算法总流程
算法流程如图所看到的:
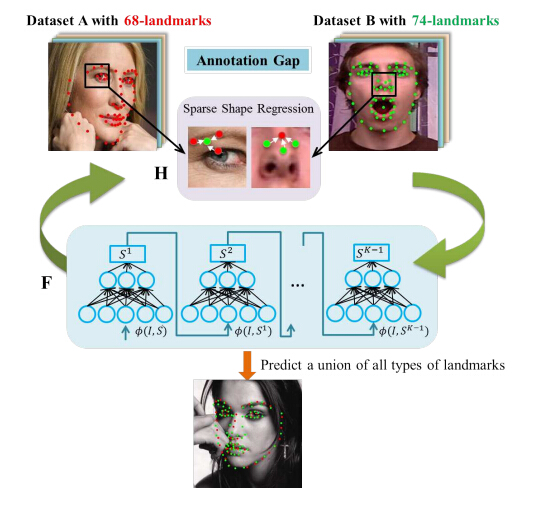
如果有若干不同点数、不同图片的人脸关键点数据集。(1)
通过这种一个训练过程,就能训练一个可以合并全部不同数据集的人脸关键点检測模型。
如果有
当中
数据集
作者使用了稀疏表达模型
当
2. 方法流程细节
2.1 深度回归模型
与 SDM/LBF相似,作者也使用了回归方法训练和測试图像特征到关键点位置的映射。差别是使用深度回归网络从初始形状開始回归 (深度学习已经占据各领域,不能被落下呀):
当中
2.2 稀疏回归模型
尽管各个数据集
当中
这样总流程的公式,可以写为还有一种形式:
2.3 训练模型
上述公式有两个模型參数须要训练,作者採用了固定一个參数,训练还有一个的迭代循环直到收敛的方法来求最优解。
每次迭代过程,作者採用了 L-BFGS 方法 (On optimization methods for deep learning,这个以后细看)解决。
与以往算法的不同
(1)“Collaborative facial landmark localization for transferring annotations across datasets”论文中提到的算法。须要依据训练集和測试集全部图片的关系预计映射关系。再对測试集全部图片进行关键点检測,并且训练过程中,也是针对各个数据集分别训练不同的模型。
而本论文算法是将全部的数据集整合进行统一关键点数模型的训练,终于得到一个检測模型,可以方便地对一张图片进行单独检測。
(2)“Transferring landmark annotations for cross-dataset face alignment”论文中的算法 transductive alignment method (TCR)须要不同数据集的关键点的交集作为相互关联,并且在预计未标记的关键点之后,不会再有更新。而本文则不须要关键点的交集作为关联,并且在模型參数训练的过程中。预计的关键点在每次迭代过程中都会随着模型的变化而更新,因而也更加准确。
实验结果
1、作者将不同的数据集相整合进行模型训练。比基于不同的训练集单独训练的模型的精度有所提高,但比真实的数据略差些(这也在情理之中): 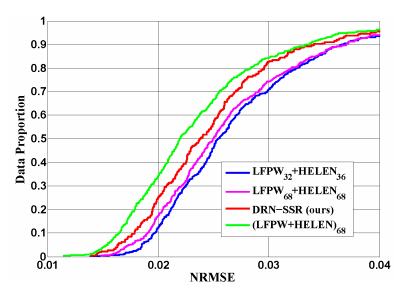
2、作者将DRN和SSR方法相结合,进一步提高了DRN的准确率: 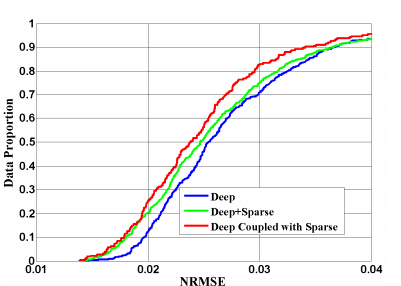
3、作者又将DRN-SSR与之前的SDM、RCPR进行了比較。实验结果均优于这些算法: 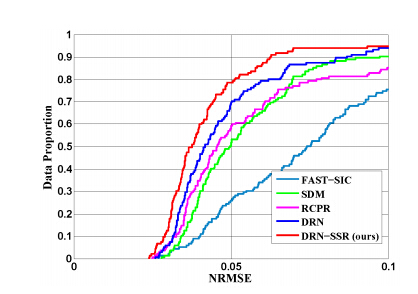
总结
作者通过 DRN和SSR将多类人脸关键点数据融合。取得了比单个数据集训练模型更好的结果。终于的模型也较为有用(可为我所用。毕竟手头数据多。如何整合一直比較头疼)。
PS
前一段时间因为操作失误,将这篇博客不小心删除(同一时候小吐槽下csdn的博客设置)。我这里没有备份,准备重写时无意发现网络上有人转载了我这篇文章(当然没有写明出处,公式也是乱码),我就拿过来回笼了一篇。
这也算是盗版给原作者的贡献了,哈哈。
文章标题:【论文笔记】Leveraging Datasets with Varying Annotations for Face Alignment via Deep Regression Network
文章链接:http://soscw.com/index.php/essay/91821.html