ForkJoinPool线程池
标签:ast reduce join tee 维护 out exe pos 数列
介绍
分而治之是一个有效的处理大数据的方法,著名的MapReduce就是采用这种分而治之的思路。简单的说,如果要处理1000个数据,但是我们不具备处理1000个数据的能力,只可以处理10个数据。我们可以将这个任务分成100份,每份处理10个,并将最后的结果进行合成,形成1000个数据的处理结果。
把一个大任务调用fork()方法分解为若干小的任务,把小的任务处理结果进行join()合并为大任务的结果。
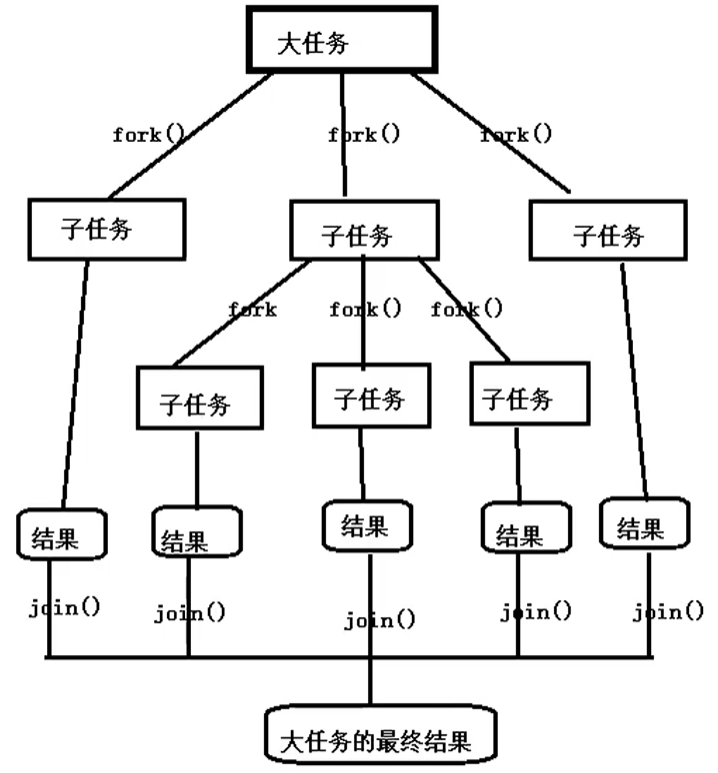
ForkJoinPool线程池最常用的方法:
//向线程池提交一个ForkJoinTask任务,
public ForkJoinTask submit(ForkJoinTask task)
ForkJoinTask支持fork()分解与join()等待的任务。
它有两个重要子类:RecursiveAction和RecursiveTask。它们区别在于RecursiveAction任务没有返回值,RecursiveTask任务带有返回值。
ForkJoinPool 的工作特点 是“工作窃取”,何为工作窃取,ForkJoinPool底层维护着一个双端队列,当一个线程的任务队列执行完毕后,其他线程的任务队列还没有执行完毕,这时,已经执行完毕的线程就会到另一个线程的双端任务队列的尾部去偷取任务执行。
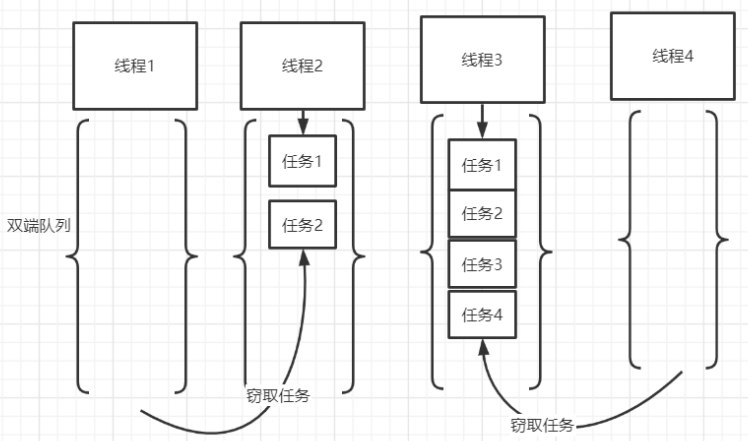
基本使用
以等查数列求和为例:
public class PoolDemo {
private static class CountTask extends RecursiveTask {
//定义数据规模的阈值,允许计算10000个数内的和,超过该阈值需要分解
//如果阈值太小,1.会导致系统内线程数量会越积越多,导致性能下降
//2.分解次数过多,方法调用过多,可能会导致栈溢出
private static final int THRESHOLD = 10000;
//每次把大任务分解为100个小任务
private static final int TASKNUM = 100;
private long start;
private long end;
public CountTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long sum = 0;
if(end - start subList = new ArrayList();
long pos = start;
for(long i =0; i end){
lastOne = end;
}
//创建子任务
CountTask task = new CountTask(pos, lastOne);
subList.add(task);
//提交子任务
task.fork();
//调整下个任务的起始位置
pos += step + 1;
}
//合并计算结果
for (CountTask countTask : subList) {
sum += countTask.join();
}
}
return sum;
}
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
long end = 200000;
CountTask task = new CountTask(0, end);
ForkJoinTask result = forkJoinPool.submit(task);
try {
Long aLong = result.get();
System.out.println(aLong);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
}
ForkJoinPool线程池
标签:ast reduce join tee 维护 out exe pos 数列
原文地址:https://www.cnblogs.com/wwjj4811/p/14506798.html
评论