一致性hash算法
2021-06-09 06:04
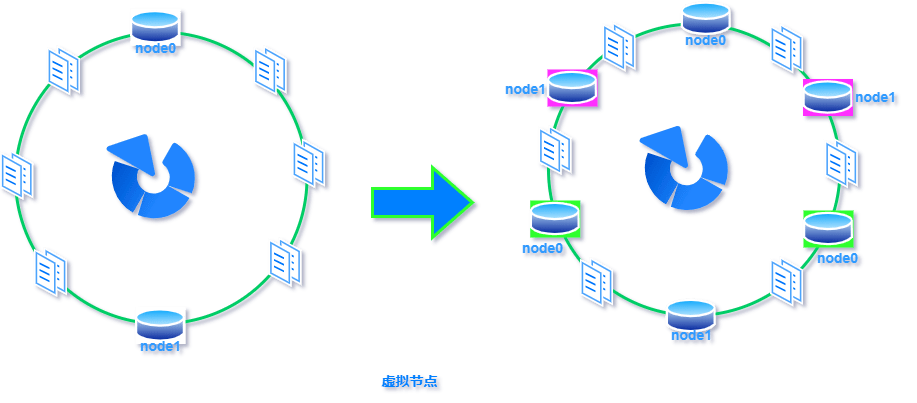
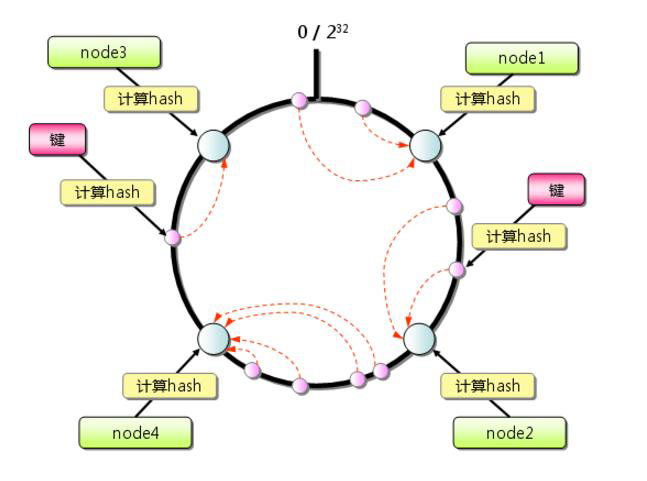
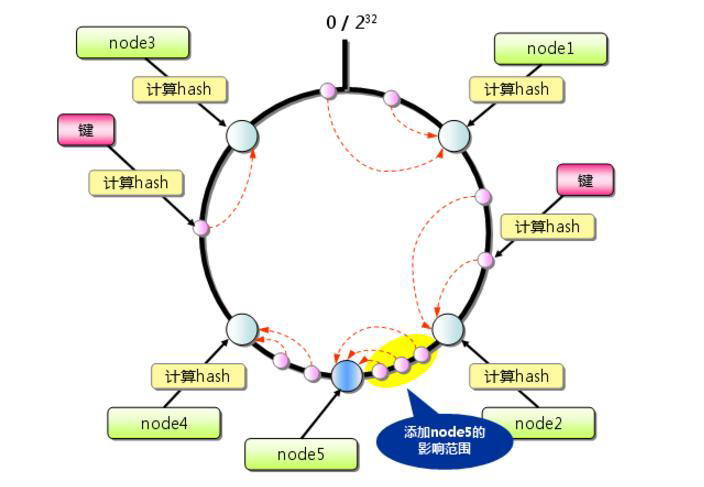
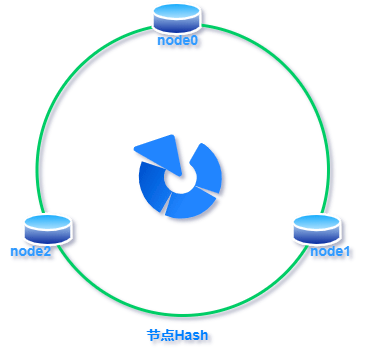
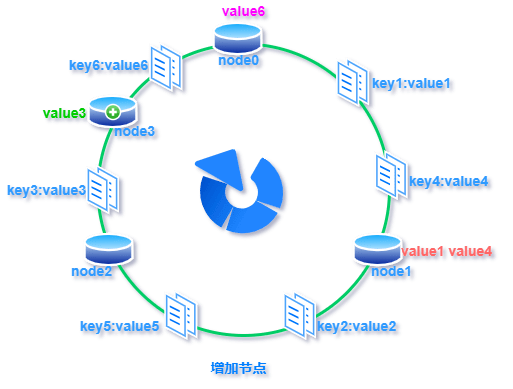
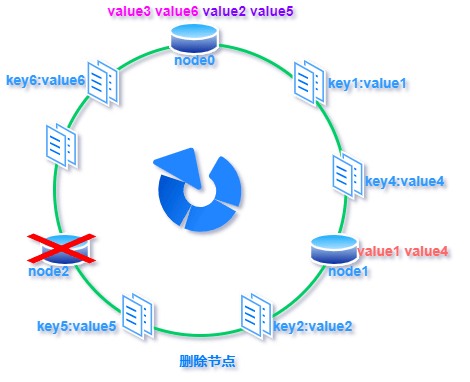
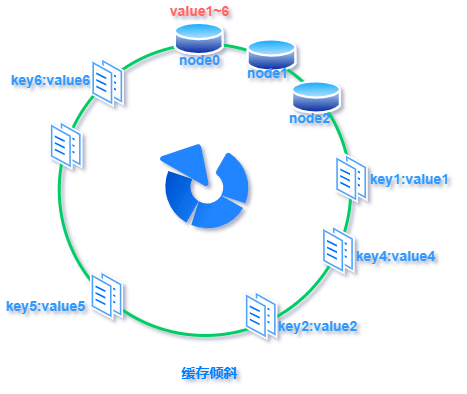
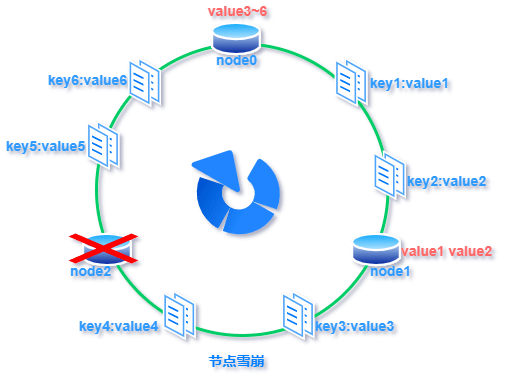
标签:超过 传递 方向 构建 表示 映射 虚拟 com 线性 一致性哈希:就是普通取模哈希算法的改良版,哈希函数计算方法不变,只不过是通过构建环状的 Hash 空间代替普通的线性 Hash 空间。 考虑到分布式系统每个节点都有可能失效,并且新的节点很可能动态的增加进来,如何保证当系统的节点数目发生变化时仍然能够对外提供良好的服务,这是值得考虑的,尤其实在设计分布式缓存系统时,如果某台服务器失效,对于整个系统来说如果不采用合适的算法来保证一致性,那么缓存于系统中的所有数据都可能会失效(即由于系统节点数目变少,客户端在请求某一对象时需要重新计算其hash值(通常与系统中的节点数目有关),由于hash值已经改变,所以很可能找不到保存该对象的服务器节点),因此一致性hash就显得至关重要,良好的分布式cahce系统中的一致性hash算法应该满足以下几个方面: 平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。 单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。简单的哈希算法往往不能满足单调性的要求,如最简单的线性哈希:x = (ax + b) mod (P),在上式中,P表示全部缓冲的大小。不难看出,当缓冲大小发生变化时(从P1到P2),原来所有的哈希结果均会发生变化,从而不满足单调性的要求。哈希结果的变化意味着当缓冲空间发生变化时,所有的映射关系需要在系统内全部更新。而在P2P系统内,缓冲的变化等价于Peer加入或退出系统,这一情况在P2P系统中会频繁发生,因此会带来极大计算和传输负荷。单调性就是要求哈希算法能够应对这种情况。 在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。 负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。 平滑性是指缓存服务器的数目平滑改变和缓存对象的平滑改变是一致的。 首先,选择一个足够大的Hash空间(一般是 0 ~ 2^32)构成一个哈希环。 然后,对于缓存集群内的每个存储服务器节点计算 Hash 值,可以用服务器的 IP 或 主机名计算得到哈希值,计算得到的哈希值就是服务节点在 Hash 环上的位置。 最后,对每个需要存储的数据 key 同样也计算一次哈希值,计算之后的哈希也映射到环上,数据存储的位置是沿顺时针的方向找到的环上的第一个节点。如果超过2^32仍然找不到服务器,就会保存到第一台存储服务器节点上。 当缓存集群的节点有所增加的时候,普通哈希算法会导致原有哈希映射大面积失效。而一致性哈希整个环形空间的映射仍然会保持顺时针规则,只有一小部分key的归属会受到影响。 如下图所示,当缓存服务集群要新增一个节点node3时,受影响的只有 key3 对应的数据 value3,此时只需把 value3 由原来的节点 node0 迁移到新增节点 node3 即可,其余节点存储的数据保持不动。 当缓存集群的节点需要删除的时候(比如节点挂掉),普通哈希算法也会导致原有哈希映射大面积失效。而一致性哈希整个环形空间的映射仍然会保持顺时针规则,同样只有一小部分key的归属会受到影响。 如下图所示,假设 node2 节点宕机下线,则原来存储于 node2 的数据 value2 和 value5 ,只需按顺时针方向选择新的存储节点 node0 存放即可,不会对其他节点数据产生影响。一致性哈希能把节点宕机造成的影响控制在顺时针相邻节点之间,避免对整个集群造成影响。 若缓存集群内的服务节点比较少,就像我们例子中的三个节点,而哈希环的空间又有很大(一般是 0 ~ 2^32),可能导致较少的服务节点哈希值聚集在一起。 比如下图所示这种情况 node0 、node1、node2 聚集在一起,缓存数据的 key 哈希都映射到 node2 的顺时针方向,数据按顺时针寻找存储节点就导致全都存储到 node0 上去,给单个节点很大的压力!这种情况称为数据倾斜。 数据倾斜和节点宕机都可能会导致缓存雪崩。 数据倾斜导致所有缓存数据都打到 node0 上面,有可能会导致 node0 不堪重负被压垮了,node0 宕机,数据又都打到 node1 上面把 node1 也打垮了,node1 也被打趴传递给 node2,这时候故障就像像雪崩时滚雪球一样越滚越大。 节点宕机比如下图所示的节点 node2 下线导致原本在node2 的数据压到 node0 , 在数据量特别大的情况下也可能导致节点雪崩,具体过程就像刚才的分析一样。 总之,连锁反应导致的整个缓存集群不可用,就称为节点雪崩。 可以通过「虚拟节点」的方式解决上述两个问题。 所谓虚拟节点,就是对原来单一的物理节点在哈希环上虚拟出几个它的分身节点,这些分身节点称为「虚拟节点」。打到分身节点上的数据实际上也是映射到分身对应的物理节点上,这样一个物理节点可以通过虚拟节点的方式均匀分散在哈希环的各个部分,解决了数据倾斜问题。 由于虚拟节点分散在哈希环各个部分,当某个节点宕机下线,他所存储的数据会被均匀分配给其他各个节点,避免对单一节点突发压力导致的节点雪崩问题。 下图左边是没做虚拟节点情况下的节点分布,右边背景色绿色两个的 node0 节点是 node0 节点的虚拟节点;背景色红色的 node1 节点是 node1 的虚拟节点。 一致性hash算法 标签:超过 传递 方向 构建 表示 映射 虚拟 com 线性 原文地址:https://www.cnblogs.com/strugger-0316/p/14497291.html一致性hash算法
一致性Hash性质
构建方法

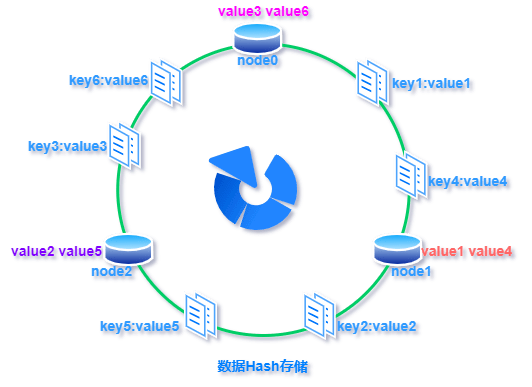
一致性哈希的优势
1.增加节点
2.删除节点
一致性哈希的问题和解决
数据倾斜
节点雪崩
虚拟节点