Java容器集合经典面试题集
2021-06-09 12:04
标签:java容器 lis 点的hash 问题 设计 过程 jdk7 二进制 怎样 首先 当使用迭代器遍历集合时,会基于原数组拷贝出一个新的数组( 数组拥有O(1)的查询效率,可以通过下标直接定位元素;链表在查询元素的时候只能通过遍历的方式查询,效率比数组低 数组增删元素的效率比较低,通常要伴随拷贝数组的操作;链表增删元素的效率很高,只需要调整对应位置的指针即可 比如说我们常常用 两者的底层实现相似,关键的不同在于 由于Vector的方法都是同步方法,执行起来会在同步上消耗一定的性能,所以在单线程环境下, 除了线程安全这点本质区别外,还有一个实现上的小细节区别: 由于 ArrayList中重写了序列化和反序列化对应的 首先计算key的hash值,计算过程是:先得到key的hashCode(int类型,4字节),然后把hashCode的高16位与低16位进行异或,得到key的hash值。 接下来用key的hash值与数组长度减一的值进行按位与操作,得到key在数组中对应的下标 追问:为什么计算key的hash时要把hashCode的高16位与低16位进行异或?(变式:为什么不直接用key的hashCode) 计算key在数组中的下标时,是通过hash值与数组长度减一的值进行按位与操作的。由于数组的长度通常不会超过2^16,所以hash值的高16位通常参与不了这个按位与操作 为了让hashCode的高16位能够参与到按位与操作中,所以把hashCode的高16位与低16位进行异或操作,使得高16位的影响能够均匀稀释到低16位中,使得计算key位置的操作能够充分散列均匀 在极端情况下,比如说key的 至于阈值为什么是8,这是HashMap的作者根据概率论的知识得到的。当key的哈希码分布均匀时,数组同一个位置上的元素数量是成泊松分布的,同一个位置上出现8个元素的概率已经接近千分之一了,这侧面说明如果链表的长度达到了8,key的hashCode()肯定是出了大问题,这个时候需要红黑树来保证性能,所以选择8作为阈值 追问:为什么红黑树转换回链表的阈值不是7而是6呢? 如果是7的话,那么链表和红黑树之间的切换范围值就太小了。如果我的链表长度不停地在7和8之间切换,那岂不是得来回变换形态?所以选择6是一种折中的考虑 在 在 如果当前节点后面带有链表,则根据每个节点的hash值与旧数组容量进行按位与的结果进行划分 还有一种情况是当前节点是树节点,那么会调用一个专门的拆分方法进行拆分 追问:为什么HashMap不支持动态缩容? 如果要支持动态缩容,可能就要把缩容安排在remove方法里,这样可能会导致remove方法的时间复杂度从O(1)上升为O(N) 因为这些基础类内部已经重写了hashCode和equals方法,遵守了HashMap内部的规范。 追问:如果要用我们自己实现的类作为key,要注意什么? 一定要重写hashCode()和equals()方法,而且要遵从以下规则: equals()是我们判断两个对象是否相同的依据,如果我们重写了equals方法,用自己的逻辑去判断两个对象是否相同,那么一定要保证:两个equals()返回true的对象,一定要返回相同的hashCode。这样,在HashMap的put方法中才能正确判断key是否相同 追问:两个对象hashCode相同,equals一定返回true吗? 答案肯定是否的,这和你的设计密切相关:如果在你的编程思路中这两个对象是不同的,那么就算恰巧两个对象的hashCode相同,equals也应该返回false 因为这样能够提高根据key计算所在数组位置的效率 HashMap根据key计算数组位置的算法是:用 因为hashMap 的数组长度都是2的n次幂 ,那么对于这个数再减去1,转换成二进制的话,就肯定是最高位为0,其他位全是1 的数 eg: 这样得到的数,就会完整的得到原hashcode 值的低位值,不会受到与运算对数据的变化影响 如果数组长度不是2的n次幂 以7为例: 通过上边可以看到,当数组长度不为2的n次幂 的时候,hashCode 值与数组长度减一做与运算的时候,会出现重复的数据, 因为不为2的n次幂的话,对应的二进制数肯定有一位为0 , 这样不管hashCode 值对应的该位,是0还是1 , 最终得到的该位上的数肯定是0,这带来的问题就是HashMap上的数组元素分布不均匀,而数组上的某些位置,永远也用不到 在JDK1.8中,官方甚至没有对 在 当对 在 在新实现中,在put方法里使用了CAS + synchronized进行同步。如果插入元素的位置为空,则使用CAS进行插入。如果插入的位置不为空,则对当前位置的对象进行加锁,也就链表或红黑树的头节点,加锁后再进行后续的插入操作 这样设计的好处是: Java容器集合经典面试题集 标签:java容器 lis 点的hash 问题 设计 过程 jdk7 二进制 怎样 原文地址:https://www.cnblogs.com/erhuoweirdo/p/14491117.html概述类面试题
1. 请说一下Java容器集合的分类,各自的继承结构
Java集合分为两大类:Collection 和 MapCollection集合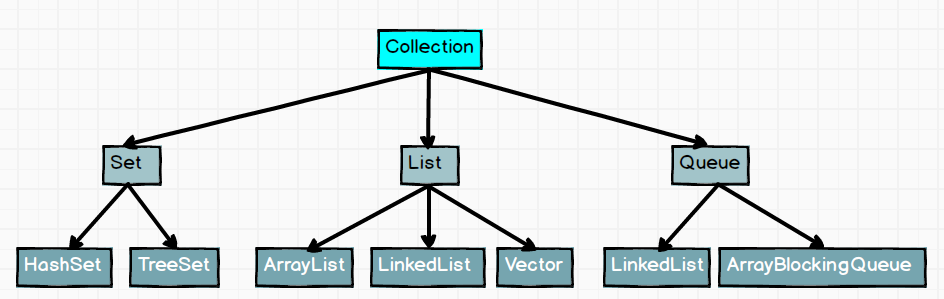
Map集合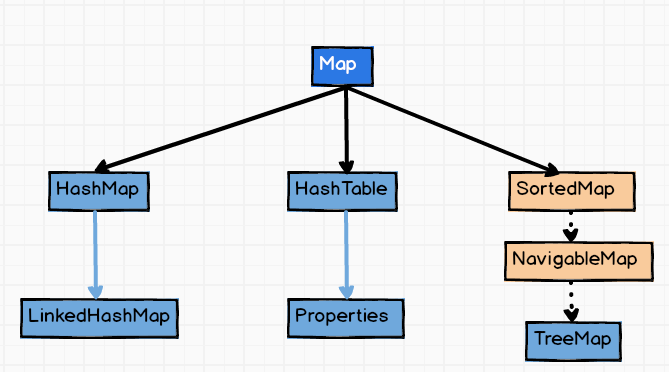
2. 请谈一谈Java集合中的fail-fast和fail-safe机制
fail-fast
fail-fast也就是 “快速失败”,它是Java集合的一种错误检测机制。当多个线程对集合进行结构上的改变的操作时,有可能会产生fail-fast机制。假设存在两个线程(线程1、线程2),线程1通过Iterator在遍历集合A中的元素,在某个时候线程2修改了集合A的结构(是结构上面的修改,而不是简单的修改集合元素的内容),那么这个时候程序就会抛出 ConcurrentModificationException 异常,从而产生了fail-fast机制ArrayList产生fail-fast的原理:ArrayList自身会维护一个modCount变量,每当进行增删元素等操作时,modCount变量都会进行自增。当使用迭代器遍历ArrayList时,迭代器会新维护一个初始值等于modCount的expectedModCount变量,每次获取下一个元素的时候都会去检查expectModCount和modCount是否相等。在上面举的例子中,由于B线程增删元素会导致modCount自增,当A线程遍历元素时就会发现两个变量不等,从而抛出ConcurrentModificationException异常fail-fast解决办法
fail-safe
fail-safe机制更像是一种对fail-fast机制的补充,它被广泛地实现在各种并发容器集合中。回头看上面的例子,如果线程A遍历的不是一个ArrayList,而是一个CopyOnWriteArrayList,则符合fail-safe机制,线程B可以同时对该集合的元素进行增删操作,线程A不会抛出任何异常CopyOnWriteArrayList产生fail-safe的原理:CopyOnWriteArrayList的底层是数组),后续的遍历行为在新数组上进行。因此线程B同时进行增删操作不会影响到线程A的遍历行为3. 如何一边遍历一边删除Collection中的元素?
ArrayListList类面试题
1. 谈谈ArrayList和LinkedList的区别
ArrayList的底层是数组,LinkedList的底层是双向链表ArrayList代替数组,因为封装了许多易用的api,而且它内部实现了自动扩容机制,由于它内部维护了一个当前容量的指针size,直接往ArrayList中添加元素的时间复杂度是O(1)的,使用非常方便LinkedList常常被用作Queue队列的实现类,由于底层是双向链表,能够轻松地提供先入先出的操作2. 谈谈ArrayList和Vector的区别
Vector的对外提供操作的方法都是用synchronized修饰的,也就是说Vector在并发环境下是线程安全的,而ArrayList在并发环境下可能会出现线程安全问题。Vector的性能是不如ArrayListArrayList每次扩容的大小为原来的1.5倍;Vector可以指定扩容的大小,默认是原来大小的两倍3. 为什么ArrayList的elementData数组要加上transient修饰
ArrayList有自动扩容机制,所以ArrayList的elementData数组大小往往比现有的元素数量大,如果不加transient直接序列化的话会把数组中空余的位置也序列化了,浪费不少的空间writeObject和readObject方法,在遍历数组元素时,以size作为结束标志,只序列化ArrayList中已经存在的元素Map类面试题
1. 请介绍一下HashMap的实现原理
JDK7底层是数组+ 链表实现的,JDK8底层是数据+链表+红黑树实现的put操作时,会调用hash方法对key进行计算,并与HashMap长度进行与运算,得出其在数组的下标索引
JDK8中,如果同一索引的元素个数超过8且数组的长度超过64,则将该索引的元素转换成红黑树存储2. HashMap是怎样确定key存放在数组的哪个位置的?
3. 为什么要把链表转为红黑树,阈值为什么是8?
hashCode()返回的值不合理,或者多个密钥共享一个hashCode,很有可能会在同一个数组位置产生严重的哈希冲突。这种情况下,如果我们仍然使用使用链表把多个冲突的元素串起来,这些元素的查询效率就会从O(1)下降为O(N)。为了能够在这种极端情况下仍保证较为高效的查询效率,HashMap选择把链表转换为红黑树,红黑树是一种常用的平衡二叉搜索树,添加,删除,查找元素等操作的时间复杂度均为O(logN)4. 请说一下HashMap的扩容原理
JDK1.7中,迁移数据的时候所有元素都重新计算了hash,并根据新的hash重新计算数组中的位置。JDK1.8中,这个过程进行了优化:如果当前节点是单独节点(后面没有接着链表),则根据该节点的hash值与新容量减一的值按位与得到新的地址
5. 为什么HashMap中适合用Integer、String这样的基础类型作为key?
6. 为什么HashMap数组的长度是2的幂次方?
key的hash值与(数组长度 - 1)的值进行按位与操作 第一个key: hashcode值:10101001
& 0111
0001 (十进制为1)
-------------------------------------------
第二个key: hashcode值:11101000
& 0111
0000 (十进制为0)
--------------------------------------------
第三个key: hashcode值:11101110
& 0111
0110 (十进制为6)
第一个key: hashcode值:10101001
& 0110
0000 (十进制为0)
------------------------------------------
第二个key: hashcode值:11101000
& 0110
0000 (十进制为0)
--------------------------------------------
第三个key: hashcode值:11101110
& 0111
0110 (十进制为6)
7. HashMap与HashTable有什么区别?
JDK1.7之前,两者的实现极为相似,最大的区别在于HashTable的方法都用synchronized关键字修饰起来了,表明它是线程安全的,由于直接在方法上加synchronized关键字的同步效率较低,在并发情况下,官方推荐我们使用ConcurrentHashMap
HashTable进行链表转树这样的优化,HashTable已经不被推荐使用了8. 请说一下ConcurrentHashMap的实现原理
JDK1.7中ConcurrentHashMap采用了一种分段锁的机制,它的底层实现是一个segment数组,每个segment的底层结构和HashMap相似,也是数组加链表segment里面的元素进行操作之前,需要获得该segment独有的一把ReentrantLock,ConcurrentHashMap如果不进行手动设置的话,默认有16个segment,可以支持16个线程对16个不同的segment进行并发写操作JDK1.8之后摒弃了segment这种臃肿的设计,新的实现和HashMap非常相似,底层用的也是数组加链表加红黑树。
上一篇:JavaWeb—文件的上传和下载
下一篇:JAVA第一章