大数据【八】Flume部署
2021-06-10 07:01
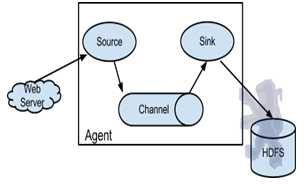
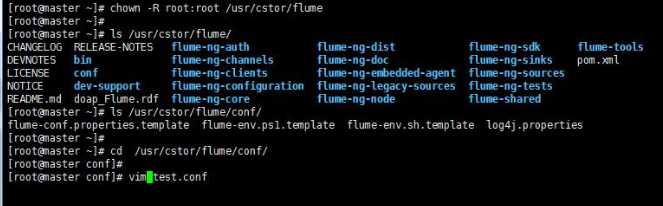
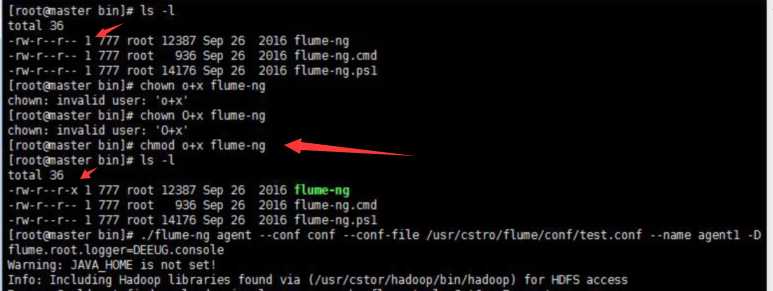
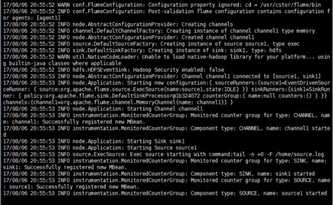
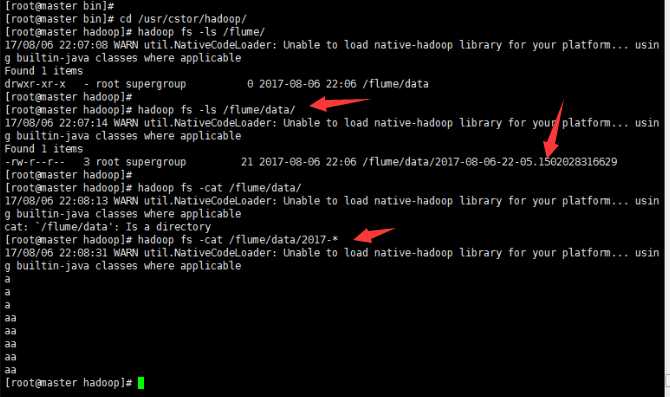
标签:channels lang 安装 action 文件 服务器 显示 runner zookeeper 如果说大数据中分布式收集日志用的是什么,你完全可以回答Flume!(面试小心问到哦) 首先说一个复制本服务器文件到目标服务器上,需要目标服务器的ip和密码: 命令: scp filename ip:目标路径 一 概述 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。 Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力 Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。 当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分。 Flume-og采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据,ZooKeeper本身可保证配置数据的一致性和高可用,另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。Flume Master间使用gossip协议同步数据。 Flume-ng最明显的改动就是取消了集中管理配置的 Master 和 Zookeeper,变为一个纯粹的传输工具。Flume-ng另一个主要的不同点是读入数据和写出数据现在由不同的工作线程处理(称为 Runner)。 在 Flume-og 中,读入线程同样做写出工作(除了故障重试)。如果写出慢的话(不是完全失败),它将阻塞 Flume 接收数据的能力。这种异步的设计使读入线程可以顺畅的工作而无需关注下游的任何问题。 Flume以agent为最小的独立运行单位。一个agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成。 二 启动Flume集群 1‘ 首先,启动Hadoop集群(详情见前博客)。 2’ 其次,(剩下的所有步骤只需要在master上操作就可以了)安装并配置Flume任务,内容如下: 将Flume 安装包解压到/usr/cstor目录,并将flume目录所属用户改成root:root。 tar -zxvf flume-1.5.2.tar.gz -c /usr/cstor chown -R root:root /usr/cstor/flume 3‘ 进入解压目录下,在conf目录下新建test.conf文件并添加以下配置内容: 4‘ 然后,在HDFS上创建/flume/data目录: cd /usr/cstor/hadoop/bin ./hdfs dfs -mkdir /flume ./hdfs dfs -mkdir /flume/data 5‘ 最后,进入Flume安装的bin目录下 cd /usr/cstor/flume/bin 6‘ 启动Flume,开始收集日志信息。 ./flume-ng agent --conf conf --conf-file /usr/cstor/flume/conf/test.conf --name agent1 -Dflume.root.logger=DEBUG,console !!!>>运行此命令有时候会出现一个权限问题,此时需要用命令 chmod o+x flume-ng 如果正常运行,最后悔显示 started,如图: 三 收集日志 1’ 启动成功之后需要手动生成消息源即配置文件中的/home/source.log,使用如下命令去不断的写入文字到/home/source.log中: 2‘ 到此就可以去查看生成结果: 小结: 这只是配置Flume,然后简单的读写日志。想要深入下去,还要收集更复杂,更庞大的日志。 大数据【八】Flume部署 标签:channels lang 安装 action 文件 服务器 显示 runner zookeeper 原文地址:http://www.cnblogs.com/1996swg/p/7294667.html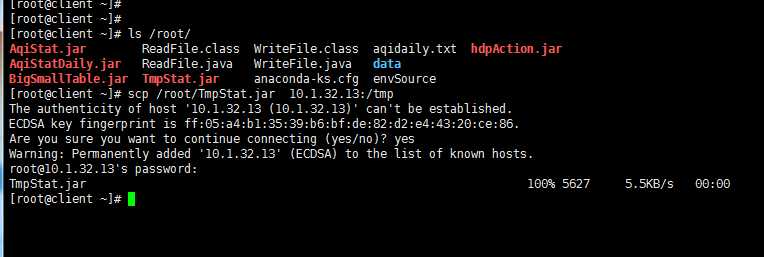
1 #定义agent中各组件名称
2 agent1.sources=source1
3 agent1.sinks=sink1
4 agent1.channels=channel1
5 # source1组件的配置参数
6 agent1.sources.source1.type=exec
7 #此处的文件/home/source.log需要手动生成,见后续说明
8 agent1.sources.source1.command=tail -n +0 -F /home/source.log
9 # channel1的配置参数
10 agent1.channels.channel1.type=memory
11 agent1.channels.channel1.capacity=1000
12 agent1.channels.channel1.transactionCapactiy=100
13 # sink1的配置参数
14 agent1.sinks.sink1.type=hdfs
15 agent1.sinks.sink1.hdfs.path=hdfs://master:8020/flume/data
16 agent1.sinks.sink1.hdfs.fileType=DataStream
17 #时间类型
18 agent1.sinks.sink1.hdfs.useLocalTimeStamp=true
19 agent1.sinks.sink1.hdfs.writeFormat=TEXT
20 #文件前缀
21 agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d-%H-%M
22 #60秒滚动生成一个文件
23 agent1.sinks.sink1.hdfs.rollInterval=60
24 #HDFS块副本数
25 agent1.sinks.sink1.hdfs.minBlockReplicas=1
26 #不根据文件大小滚动文件
27 agent1.sinks.sink1.hdfs.rollSize=0
28 #不根据消息条数滚动文件
29 agent1.sinks.sink1.hdfs.rollCount=0
30 #不根据多长时间未收到消息滚动文件
31 agent1.sinks.sink1.hdfs.idleTimeout=0
32 # 将source和sink 绑定到channel
33 agent1.sources.source1.channels=channel1
34 agent1.sinks.sink1.channel=channel1

上一篇:HTML基础
下一篇:css实现高度动态变化的布局