Python网络爬虫部分
2021-06-11 04:04
标签:一个 uil 爬虫 ip代理 接口 lib 淘宝 operator 描述 CSDN博客的爬取(链接的爬取) 前面已经学会如何构建用户代理,那么用户代理池如何构建呢?所谓的用户代理池,即将不同的用户代理组建成为一个池子,随后随机调用。 IP代理概述 IP代理池构建 淘宝商品图片爬虫实战 Python网络爬虫部分 标签:一个 uil 爬虫 ip代理 接口 lib 淘宝 operator 描述 原文地址:https://www.cnblogs.com/LWK5100/p/14231454.html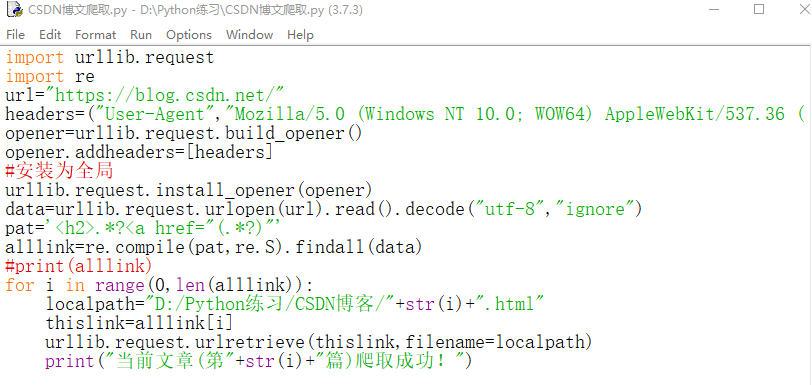
糗事百科段子爬取(内容的爬取)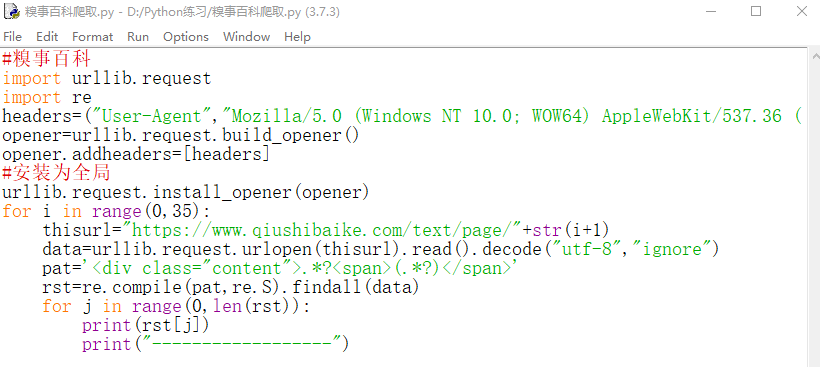
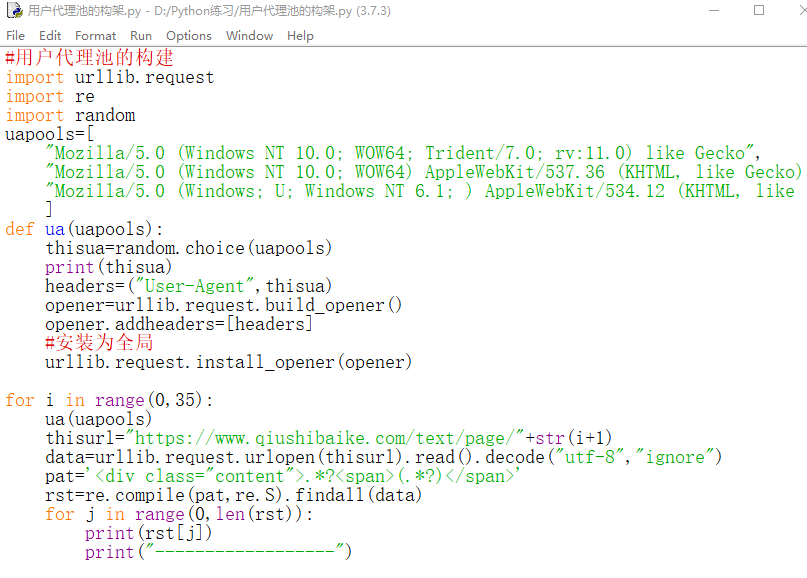
用户代理池构建实战
IP代理与IP代理池的构建的两种方案
IP代理是指让爬虫使用代理IP去爬取对方的网站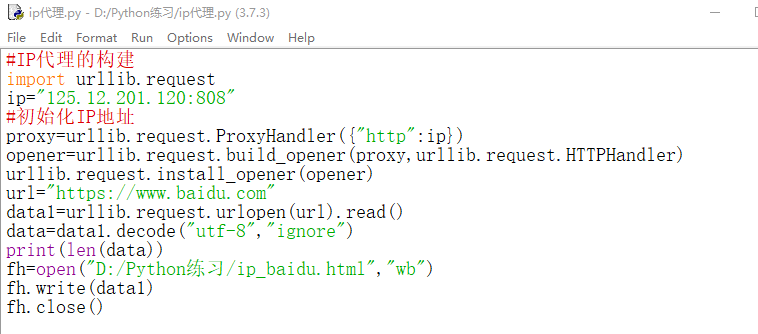
使用urllib.request.ProxyHandler()来设置对应的代理服务器信息,设置格式为:urllib.request.ProxyHandler({“http”:代理服务器地址})
上面设置完后,要进行初始化,使用urllib.request.build_opener(代理信息,urllib.request.HTTPHandler)创建一个自定义的opener对象,第一个参数代理信息,第二个参数为urllib.request.HTTPHandler类
为了方便,使用urllib.request.install_opener()创建全局默认的opener对象,那么在使用urlopen()时,会使用安装的opener对象
若打开使用wb形式,则不需要转码,因为是wb是使用二进制形式写入;若打开用w形式,则需要转码decode
第一种方式:使用随机代理池调用IP代理池的构建(适合于代理IP稳定的情况)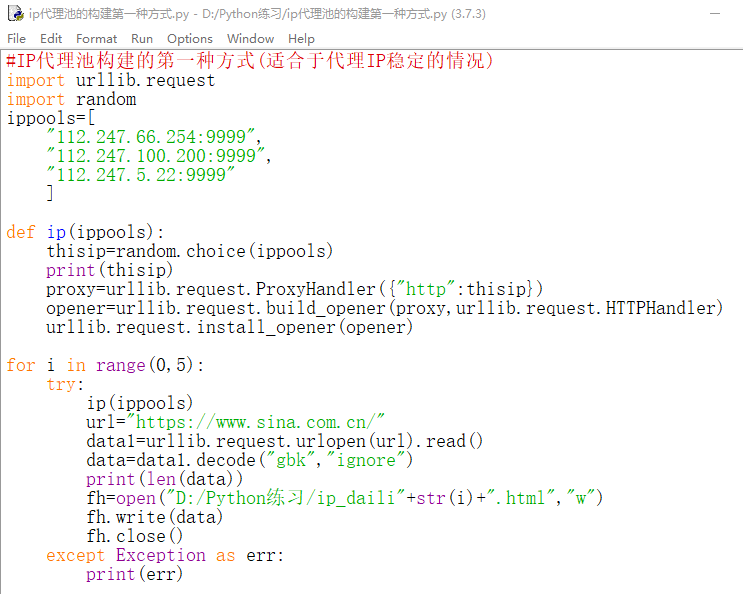
第二种方式:通过接口调用法实现IP代理池的构建
???待研究#淘宝商品图片爬虫
import urllib.request
import re
import random
keyname="连衣裙"
key=urllib.request.quote(keyname)
uapools=[
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12"
]
def ua(uapools):
thisua=random.choice(uapools)
print(thisua)
headers=("User-Agent",thisua)
opener=urllib.request.build_opener()
opener.addheaders=[headers]
#安装为全局
urllib.request.install_opener(opener)
for i in range(1,101):
url="https://s.taobao.com/search?q="+key+"&s="+str((i-1)*44)
ua(uapools)
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
pat=‘pic_url":"//(.*?)"‘
imglist=re.compile(pat).findall(data)
print(imglist)
for j in range(0,len(imglist)):
thisimg=imglist[j]
thisimgurl="http://"+thisimg
lockfile="D:/Python练习/淘宝图片/"+str(i)+str(j)+".jpg"
urllib.request.urlretrieve(thisimgurl,filename=localfile)
上一篇:Python初识与安装
下一篇:java实现并查集