布隆过滤器(Bloom Filters)的原理及实现(Python + Java)
标签:res and 数组 内容 就会 font 评估 dynamic stand
-
布隆过滤器是什么?
| 布隆过滤器是一个高效的数据结构,用于集合成员查询,具有非常低的空间复杂度。 |
-
标准布隆过滤器(Standard Bloom Filters,SBF)
|
基本情况
布隆过滤器是一个含有 m 个元素的位数组(元素为0或1),在刚开始的时候,它的每一位都被设为0。同时还有 k 个独立的哈希函数 h1, h2,..., hk 。需要将集合中的元素加入到布隆过滤器中,然后就可以支持查询了。说明如下:
- 计算h1(x), h2(x),...,hk(x),其计算结果对应数组的位置,并将其全部置1。一个位置可以被多次置1,但只有一次有效。
- 当查询某个元素是否在集合中时,计算这 k 个哈希函数,只有当其计算结果全部为1时,我们就认为该元素在集合内,否则认为不在。
- 布隆过滤器存在假阳性的可能,即当所有哈希值都为1时,该元素也可能不在集合内,但该算法认为在里面。
- 假阳性出现的概率被哈希函数的数量、位数组大小、以及集合元素等因素决定。
|
假阳性率评估
为了评估假阳性率,需要基于一个假设:哈希函数都是完美随机的。约定几个变量:
- k 哈希函数的数量
- n 集合 S 中元素的数量
- m 位数组的大小
- p 位数组中某一位为0的概率
- f 假阳性的概率
最后得出:
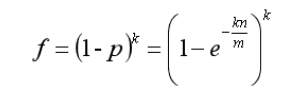
|
|
最佳的哈希函数数量
根据数学推理得(过程就算了):当 p = 1/2, k = ln2 * (m/n)时,f 最小为(1/2)^k
可以看出,当位数组中有一半零一半一时,结果最好。
事实上,m 是 n 的倍数,而且 k 常取最接近但小于理论值的整数值。
|
|
部分布隆过滤器(partial bloom filters)
|
-
计算布隆过滤器(Counting Bloom Filters,CBF)
| 标准的布隆过滤器有一个致命的缺点:不支持删除元素。CBF协议解决的这个问题。 |
- 将标准布隆过滤器中的位数组变成整数数组,即可以用多位表示。
- 标准布隆过滤器每个位置可以被多次置1,但只有一次有效,这样,某一个位置被多个元素哈希映射,当要删除其中一个元素时,该元素哈希映射的位置都应该变为零,那么就会破坏其他元素的映射,会出现假阴性。
- 由于计算布隆过滤器的数组可以表示更大的整数,那么当某个位置被映射到时,该位置的计数值就自增1,而当某个元素被删除时,就将其映射位置的计数值减1。这样就解决了SBF的问题。
- CBF同样存在问题,因为当计数值自增时可能会溢出,当计数值为4比特时,溢出的概率为:1.37 * 10^-15 * m,虽然很低,但对某些应用可能不够。一个简单的解决方法是,当计数值到达最大值时,就不在自增,但这导致假阴性。
|
-
压缩布隆过滤器(Compressed Bloom Filters)
| 在网络应用中,布隆过滤器通常被作为信息在各节点间传送,为了节约资源,自然而然就想能不能压缩布隆过滤器后再传送。 |
- 由前面我们知道,要使得布隆过滤器有最小的假阳性概率,数组中包含的0或1的概率应该是一样的,根据香农编码原理(Shannon coding principle),这样的布隆过滤器不能被压缩。虽然这样的布隆过滤器不能被直接压缩,但我们可以用其他方法达到一样的效果。
- 要使得布隆过滤器 x 与布隆过滤器 y( 包含的0或1的概率应该是一样的)具有相同的假阳性概率,那么,x 的大小要大于 y 的,x 的哈希函数的数量不同于 y 的,这样 x 中包含的0和1的数量就不同,x 就可以被压缩。
- 问题出来了,压缩布隆过滤器的原因是更节省空间,我们找了个更大的布隆过滤器压缩,那么压缩后的布隆过滤器的空间效率比原布隆过滤器更加优秀吗?是的。
- 压缩后,布隆过滤器的本地存储空间会变大,但哈希函数数量会变小(更少的映射操作)、传送的位更少。
|
-
D-left 计算布隆过滤器(D-left Counting Bloom Filters)
上面提到的计算布隆过滤器存在这样的缺点:存储空间是标准布隆过滤器的数倍(取决于计数值的位数)和计数值的不均匀(有些始终为0,有些则可能溢出)。下面看看 D-left Counting Bloom Filters 的特点。D-left Counting Bloom Filters 基于 D-left Hashing。
|
D-left Hashing 基本结构
- 将一个哈希表分成几个不相交的子表(subtable)
- 每个子表里都有数量相同的桶(bucket)
- 每个桶里都有一定数量的单元(cell,单元包括特征值和计数值)
- 每个单元都是固定的位数组成,用来保存元素的特征值(fingerprint)
- 只有一个哈希函数,该哈希函数可以生成和子表数量相同的桶地址和一个特征值
插入操作
假设有 d 个子表,元素为 x,哈希函数为 f
- 计算 f(x),生成桶地址 addr0, addr1, ..., addr(d-1),特征值 p
- 我们检查子表 i 中地址为 addri 的桶中的所有单元(i = 0,1,...,d-1)
- 如果某个单元中的特征值和 p 相等,那么元素 x 就在该哈希表中
- 若没有找到这样的单元,那么需要找到存储特征值最少的桶(在上面生成的桶地址中找),然后将该特征值 p 随机放入该桶的一个空单元中,该单元的计数值变为1,这考虑了装载平衡
|
D-left Counting Bloom Filters
由上可知,d-left Hashing 的计数值最大为零,不支持删除操作,为了将它变成可 Counting,可以让它的计数值变成由多位组成。但这样依然会出现问题,如下:
- 假设 d-left counting bloom filter 包含 4 个子表,每个子表又包含 4 个桶,初始为空。
- 现在有两个元素 x 和 y 需要映射到过滤器中,f(x) = (1, 1, 1, 1,r), f(y) = (1, 2, 3, 4, r)
- 已知插如 x 时,第四个子表的第一个桶最空,x 的特征值 r 被插入该桶的某一个单元中,该单元计数值变为1,而插入 y 时,第一个子表的第一个桶最空,y 的特征值 r 被插入该桶的某一个单元中,该单元计计数值变为1
- 现在要删除 x,那么就会寻找每个子表的第一个桶中的单元,这时,在第一个子表的第一个桶中找到了特征值 r,接下来就会将该单元的计数值减 1 变为 0,同时,存储的特征值被删除,变为空。
- 现在查找 x 是否在表中,结果返回真,而查询 y 是否在表中,结果返回假,导致错误。
|
为什么会出现上面的情况?由三个因素促成
- x 和 y 有相同的特征值 r
- f(x) 和 f(y) 生成的地址有相同的
- x 和 y 特征值存储的地方还不一样(存一样就不会出错)
|
如何解决?
说实话,没看懂英文描述的内容。。。。大致是做了排列置换等操作
性能分析
比普通的计算布隆过滤器空间少了一半甚至更多,而且效率也有提升(假阳性更低)
|
-
Spectral Bloom Filters
| Counting Bloom Filters 可以进行元素的删除操作,然而却不能记录一个元素被映射的频率,而且很多应用中元素出现的频率相差很大,也就是说,CBF中每个计数值的位数一样,那么有些计数值很快就会溢出,而另一些则一直都很小。这些问题可以被 Spectral Bloom Filters 解决。 |
| 在SBF中,每一个计数值的位数都是动态改变的。它的构造我没看懂,先留着吧 |
-
Dynamic Counting Filters
| Spectral bloom filter 被提出来解决元素频率查询问题,但是,它构造了一个复杂的索引数据结构去解决动态计算器的存储问题。Dynamic counting bloom filter(比SBF好理解多了) 是一个空间时间都很高效的数据结构,支持元素频率查询。相比于SBF,在实际应用中(计数器不是很大,改变不是很频繁时)它有更快的访问时间和更小的内存消耗。 |
构成部分
- DCBF由两部分组成,第一部分是基础的计算布隆过滤器
- 第二部分是一个同样大小的向量,用于记录第一部分中计算器溢出的次数
- 第一部分中的计算器位数固定,第二部分中每个溢出计算器位数动态改变
|
特点
- 当第二部分溢出计算器也面临溢出时,会重新申请一个向量,给要溢出部分增加位数,其他溢出计算器直接拷贝到新的向量中的对应位置,旧的向量会被释放
|
-
学习案例
Summary Cache
在网络中有极大的资源请求,如果所有的请求都由服务器来处理,网络就会出现拥堵,性能就会下降。所以网络中有大量的中间代理节点。这些代理会把一部分资源放在自己的本地缓存,当用户向服务器请求资源时,该代理先会检查该资源是否在自己的缓存中,如果在就直接发送给用户,否则再向服务器请求。一个代理能够存储的资源是非常有限的,为了进一步减轻服务器的负载,网络中相邻的代理都可以共享自己的缓存。这样,当代理 A 本地缓存没有时,就会向相邻代理广播请求,查询他们是否有该缓存。
然而,这样依旧有很大问题,假设,这里有 N 个代理,每个代理的命中率为 H,一个代理平均请求 R 次,那么广播中,一个代理收到的查询信息共有 (N-1) * (1-H) * R 条,总共的请求也就是
N * (N-1) * (1-H) * R。这是非常低效的。
再次改进,各个代理之间交换自己缓存的摘要信息。这样,当代理 A 失败后,会先查询各个代理的摘要信息,然后决定是定向向某个代理请求,还是向服务器请求资源。这就大大的减少了网络通信量。为了满足快速查询、更新摘要信息,一个非常好的选择就是计算布隆过滤器(Counting bloom filters)。
|
IP Traceback
网络中存在许多攻击,有时候需要根据一些数据包去还原IP路径,找到攻击者。一个可行的办法是在路由器中存储数据包信息。然而,有些网络中通信量巨大,存储所有的包是不现实的,因此可以存储这些包的摘要信息。这时,选用布隆过滤器可以极大的节省空间,而且具有非常快的查询。
|
布隆过滤器(Bloom Filters)的原理及实现(Python + Java)
标签:res and 数组 内容 就会 font 评估 dynamic stand
原文地址:https://www.cnblogs.com/Gouhongshen/p/13519717.html
评论