C#采用vony.Html.AIO插件批量爬MM网站图片
2021-06-12 12:06
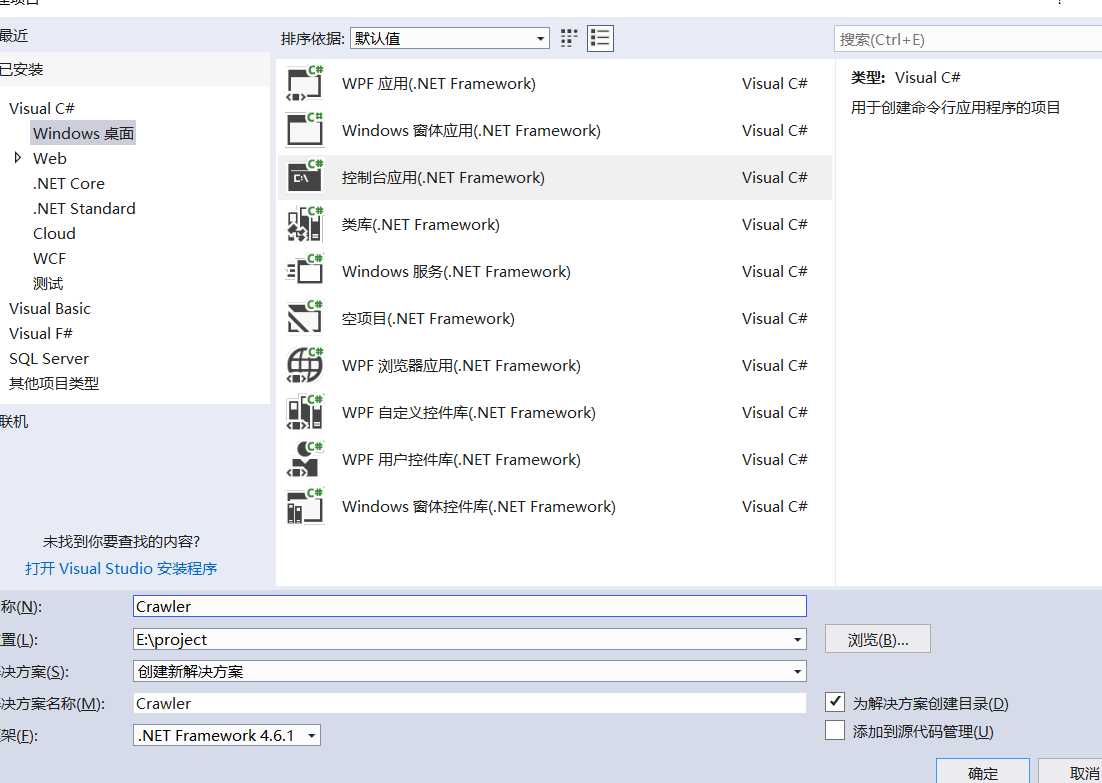
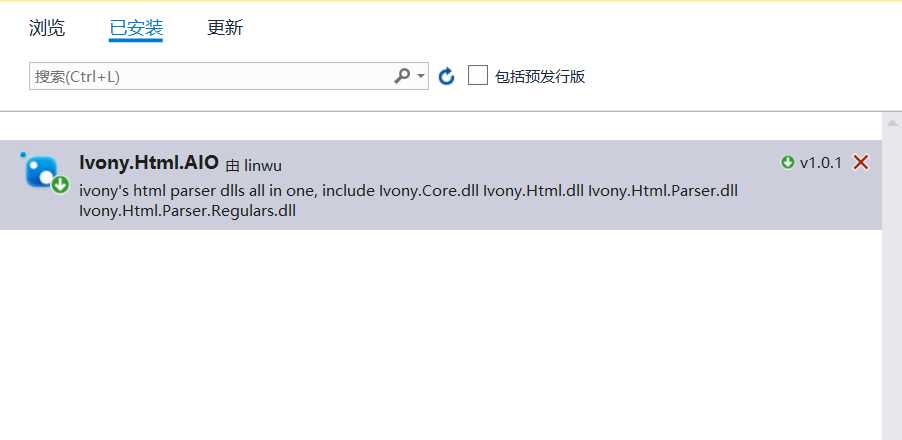
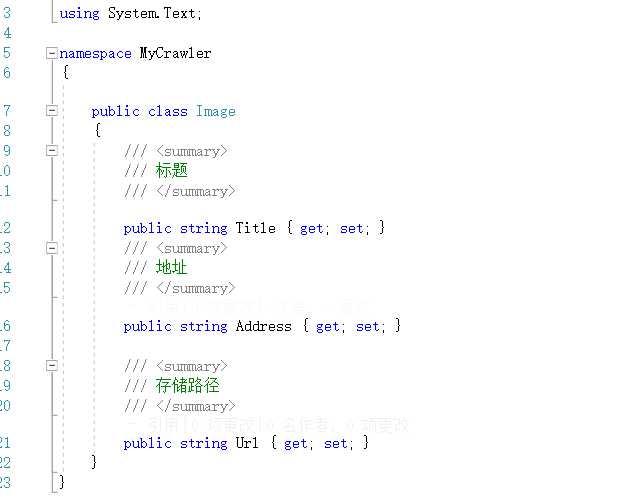
标签:控制 超链接 har file 取图 .net tar 网站 int 1.创建一个.netframework的控制台项目命名为Crawler 2.安装nuget包搜索名称Ivony.Html.AIO,使用该类库什么方便类似jqury的选择器可以根据类名或者元素类型来匹配元素,无需要写正则表达式。 3.创建一个图片类Image 1.拿到所有图片页面的地址 本次爬取的网站为https://www.mntup.com/,打开页面进入二级目录https://www.mntup.com/SiWa.html,并查页面看源代码,如下图: 图片页都在class=“dana”的div下面,我们要拿去div中超链接的href,如下格式: 首先考虑要拿到所有图片页面的超链接,c#代码下: 2.打开图片页,发现是带有分页的,那就要获取所有的分页的链接了。分页的地址都在页面当中,所以我们直接匹配就好。 由于每个图片页都有分页地址,所以直接匹配分页地址,C#代码如下: 3.所有分页都获取到了,接下来就是要获取页面中的每张图片了,打开页面查看源代码: 观察发现,所有的图片都在class=img的div下面,那就可以从每个分页中直接下载所有的图片了,代码如下: 图片下载方法如下,为防止下载的时候阻塞主进程,下载采用异步: 由于编码格式的问题,无法获取到中文标题,所有就采取了页面链接作为目录名称,下面是一张我抓取图片的截图: 最后的战果: 最后奉上代码如下:https://github.com/peijianmin/MyCrawler.git C#采用vony.Html.AIO插件批量爬MM网站图片 标签:控制 超链接 har file 取图 .net tar 网站 int 原文地址:https://www.cnblogs.com/taxue/p/10504874.html一、创建项目
一、抓取页面图片

[Rosi写真]NO.2637_红色吊带高叉连体衣妹子床上狗爬式秀浑圆翘臀撩人诱惑写真38P 2019-02-26
//需要定义一个list用来存放所有的页面链接
static List
foreach (var url in categoryUrl)
{
//获取图片也的的文档
IHtmlDocument html = new JumonyParser().LoadDocument($"{address}{url}", System.Text.Encoding.GetEncoding("utf-8"));
//获取每个分页面并下载
var pageLink = html.Find(".page a");
foreach (var alingk in pageLink)
{
string href = alingk.Attribute("href").Value();
Console.WriteLine($"获取分页地址{href}");
}
}

//获取每一个分页的文档模型
IHtmlDocument htm2 = new JumonyParser().LoadDocument($"{address}{href}", System.Text.Encoding.GetEncoding("utf-8"));
//获取class=img的div下的img标签
var aLink = htm2.Find(".img img");
foreach (var link in aLink)
{
var imgsrc = link.Attribute("src").Value();
Console.WriteLine("获取到图片路径" + imgsrc);
Console.WriteLine($"开始下载图片{imgsrc}>>>>>>>");
DownLoadImg(new Image { Address = address + imgsrc, Title = url });
}
}
///
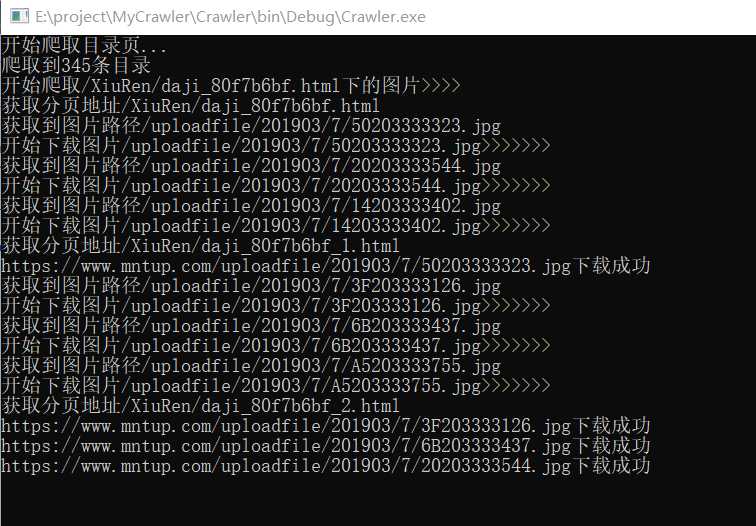
三、抓取图片
文章标题:C#采用vony.Html.AIO插件批量爬MM网站图片
文章链接:http://soscw.com/index.php/essay/93875.html