Xapian索引-文档检索过程分析
2021-06-12 12:06
标签:hellip open remove ssi api set 方式 拉取 转换 本文是Xapian检索过程的分析,本文内容中源码比较多。检索过程,总的来说就是拉取倒排链,取得合法doc,然后做打分排序的过程。 1 理论分析 1.1 检索语法 面对不同的检索业务,我们会有多种检索需求,譬如:要求A term和B term都在Doc中出现;要求A term或者B term任意在Doc中出现;要求A term或者B term任意在Doc出现,并且C term不出现…...,用符号表示: A & B A || B (A || B) & ~C ( A & ( B || C ) ) || D … 以上的种种检索需求,复杂繁多,每一个检索需求都单独实现一份代码,是不现实的,需要有一种简单、高效、可扩展的检索语法来支持他们。 1.2 检索过程 首先是根据业务需求,组装检索语句,然后调用检索内核提供的API获取检索结果。 检索内核的实现,以xapian为例:首先根据用户组装的检索语句形成query-tree(query检索树),然后将query-tree转换为postlist-tree(倒排链树),最后获取postlist-tree运算后的结果。在获取postlist-tree和最后的计算过程中,穿插着相关性公式(如:BM25)的运算。 1.3 相关性 计算query跟doc相关性方式有好几种, (1) 布尔模型(Boolean Model) (2)向量空间模型(Vector Space Model) BM25公式,三部分:1、BIM模型,等价于IDF;2、term在文档中的权重(doc-tf);3、term在query中的权重(query-tf); N,表示索引中总的文档数, BM25F 相关性部分资料参考:《这就是搜索引擎》 2 源码分析 2.1 主要类 下面以xapian为例,介绍一般检索过程,因涉及源码众多,部分枝节策略不一一细说。首先,这里列出,涉及到的主要类,从这里也可以一窥xapian在检索上的设计思路。 绿色背景的块是用户看到的,蓝色背景是其底层涉及到的。 Enquire::Internal,Enquire的内部实现,Xapian的设计风格都是包一层壳,功能实际的实现放在Internal中; BM25Weight,Xapian默认使用的相关性打分类; Weight::Internal,打分需要用到的基础信息,譬如:索引库文档量、索引库总的term长度、query里的 term的tf、df数据…; MultiMatch,检索的实现类; LocalSubMatch,本地子索引库操作的封装。 xapian支持远程索引库,也支持一个索引库拆分成多个子索引库; QueryOptimiser ,从Query-Tree构建PostList-Tree时的帮助类,主要记录了一些子索引库相关的信息,譬如:LocalSubMatch的引用、索引库DataBase的引用…; QueryOr、QueryBranch、QueryTerm ,这系列是Query Tree上的一个个类; PostList、LeafPostList,PostList-Tree上的一个个类; InMemoryPostList,内存索引库的PostList封装; OrContext,记录在Query-Tree转PostList-Tree过程中的PostList上下文信息,包括:QueryOptimiser对象指针、临时存放的PostList指针; 2.2 检索过程 2.2.1 用户demo代码 2.2.2 query组装的实现 只有一个类——Query,通过构造函数重载,提供了一切需要的功能。 eg: /* 根据OP,生成对应的Query派生类,譬如:or的生成 QueryOr类,含有两个子query,这个QueryOr类对象作为Query的internal成员存在; ... 检索树的组织没有做特别的设计,譬如:用vector来存储OR的元素。 2.2.3 检索的实现 (1)检索函数入口: (2)检索之前的准备工作,在 MultiMatch 对象构造的时候做,prepare_sub_matches: prepare_sub_matches(): BM25计算之前的准备工作 (3)打开倒排链,构造postlist-tree: 打开倒排链和检索放在一个800行的超大函数里面: 打开倒排链的过程,函数多层嵌套非常深入,这也是检索树解析-->重建过程: ... weight的init: 总的来说,这一阶段: stats设置给LocalSubMatch对象; 这就把BM25公式中,不跟具体doc相关的第一和第三部分计算完成。 构建postlist-tree,如果是And的语法,则使用PostList * AndContext::postlist() 生成postlist,然后把子postlist-tree销毁掉; (4)最终召回排序 循环从postlist-tree拉取docid,然后计算BM25打分, 两个有序链表求交: 获取BM25打分: 两个有序链表求并: percent是怎么计算的? double v = wt * percent_factor + 100.0 * DBL_EPSILON; // percent_scale就是percent_factor,v就是percent 从BM25打分的执行过程,可以想到,有部分BM25打分因子(第一部分idf因子、第二部分term-doc相关性因子)是不需要在线计算的,只需要离线计算后并存储在倒排中即可。 当前默认使用的BM25Weight打分策略,没有使用get_maxextra函数和get_sumextra函数。 Xapian索引-文档检索过程分析 标签:hellip open remove ssi api set 方式 拉取 转换 原文地址:https://www.cnblogs.com/cswuyg/p/10508114.html
判断用户的term在不在文档中出现,如果出现了则认为文档跟用户需求相关,否则认为不相关。
优点:简单;
缺点:结果是二元的,只有YES 或者 NO, 多条结果之间没有先后顺序;
将query和doc都向量化,计算query跟doc的余弦值,这个值就是query跟doc的相似性打分。这里将查询跟文档的内容相似性替换相关性。
这个模型对长文本比较抑制。
consine公式:向量点积 / 向量长度相乘。
那么,怎么向量化?每一纬的值,给多少合适?
词频因子(TF):某个单词在文档中出现的次数;一般或取log做平滑,避免直接使用词频导致出现1次和出现10次的term权重差异过大。 常见公式: Wtf = 1 + log(TF). 常量1是为了避免TF=1时,log(TF) = 0,导致W变成0。
变体公式: Wtf = a + (1 - a) * TF/Max(TF),其中a是调节因子,取值0.4或者0.5,TF表示词频,Max(TF)表示文档中出现次数最多的单词对应的词频数目。这个变种有利于抑制长文本,使得不同长度文档的词频因子具有可比性。
逆文档频率因子(IDF):包含有某个词的文档数量的倒数。如果一个词在所有文档中都出现,那么这个词对文档的区分度贡献不高,不是那么重要,反之,则说明这个词很重要。
公式: IDFk = log(N/nk), N代表文档集合总共有多少个文档;nk代表词在多少个文档中出现过。
TF*IDF框架:
Weight = TF * IDF
(3)概率检索模型
BIM模型的公式,由四个部分组成,这四个部分可以理解为:1、某个term在相关集合中出现的次数,正面因素;2、某个term在不相关集合中出现的次数,负面因素;3、某个term在不相关集合中出现的次数,负面因素;4、某个term在不相关集合中不出现的次数,正面因素。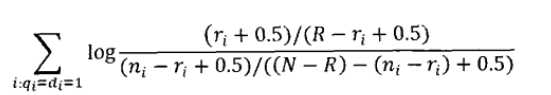
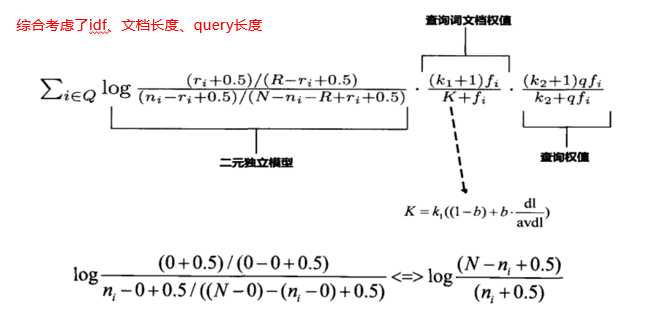
Ni,表示索引中包含有term的文档数,也就是df,
fi,表示term在文档中出现的次数,
qfi,表示term在query中出现的次数,
dl,表示文档长度,
avdl,表示平均文档长度
考虑到不同的域,对第二部分的平均长度、调节因子,需要根据不同的域设置不同的值,并且需要一个跟域相关联的权重值。
Xapian::Query term_one = Xapian::Query("T世界");
Xapian::Query term_two = Xapian::Query("T比赛");
Xapian::Query query = Xapian::Query(Xapian::Query::OP_OR, term_one, term_two); // query组装
std::cout "query=" std::endl;
Xapian::Enquire enquire(db);
enquire.set_query(query);
Xapian::MSet result = enquire.get_mset(0, 10); // 执行检索,获取结果
std::cout "find results count=" std::endl;
for (auto it = result.begin(); it != result.end(); ++it) {
Xapian::Document doc = it.get_document();
std::string data = doc.get_data();
double doc_score_weight = it.get_weight();
int doc_score_percent = it.get_percent();
std::cout "doc=" ",weight=" ",percent=" std::endl;
}
Query::Query(const string & term, Xapian::termcount wqf, Xapian::termpos pos)
: internal(new Xapian::Internal::QueryTerm(term, wqf, pos)) {
LOGCALL_CTOR(API, "Query", term | wqf | pos);
}
Query(op op_, const Xapian::Query & a, const Xapian::Query & b) {
init(op_, 2);
bool positional = (op_ == OP_NEAR || op_ == OP_PHRASE);
add_subquery(positional, a);
add_subquery(positional, b);
done();
}
在组合多个query时,直接添加到vector中;
如果最后发现vector是空的则将internal设置为NULL,或者=1,则将internal设置为子query的internal,这样子可以避免不必要的vector嵌套,如:[xxquery],单个元素没必要放在vector中。*/MSet Enquire::Internal::get_mset(Xapian::doccount first, Xapian::doccount maxitems, Xapian::doccount check_at_least, const RSet *rset, const MatchDecider *mdecider) const {
LOGCALL(MATCH, MSet, "Enquire::Internal::get_mset", first | maxitems | check_at_least | rset | mdecider);
if (percent_cutoff && (sort_by == VAL || sort_by == VAL_REL)) {
throw Xapian::UnimplementedError("Use of a percentage cutoff while sorting primary by value isn‘t currently supported");
}
if (weight == 0) {
weight = new BM25Weight; // 如果外界没有指定打分策略,采用BM25Weight
}
Xapian::doccount first_orig = first;
{
Xapian::doccount docs = db.get_doccount();
first = min(first, docs);
maxitems = min(maxitems, docs - first);
check_at_least = min(check_at_least, docs);
check_at_least = max(check_at_least, first + maxitems);
}
AutoPtr<:weight::internal> stats(new Xapian::Weight::Internal); // 用于记录打分用的全局信息
// MultiMatch对象的初始化,会执行检索的初始化工作,譬如:填充stats对象,
::MultiMatch match(db, query, qlen, rset,
collapse_max, collapse_key,
percent_cutoff, weight_cutoff,
order, sort_key, sort_by, sort_value_forward,
time_limit, *(stats.get()), weight, spies,
(sorter.get() != NULL),
(mdecider != NULL));
// Run query and put results into supplied Xapian::MSet object.
MSet retval;
match.get_mset(first, maxitems, check_at_least, retval, *(stats.get()), mdecider, sorter.get()); // 检索
if (first_orig != first && retval.internal.get()) {
retval.internal->firstitem = first_orig;
}
Assert(weight->name() != "bool" || retval.get_max_possible() == 0);
// The Xapian::MSet needs to have a pointer to ourselves, so that it can
// retrieve the documents. This is set here explicitly to avoid having
// to pass it into the matcher, which gets messy particularly in the
// networked case.
retval.internal->enquire = this;
if (!retval.internal->stats) {
retval.internal->stats = stats.release();
}
RETURN(retval);
}static void prepare_sub_matches(vector


bool LocalSubMatch::prepare_match(bool nowait, Xapian::Weight::Internal & total_stats) {
LOGCALL(MATCH, bool, "LocalSubMatch::prepare_match", nowait | total_stats);
(void)nowait;
Assert(db);
total_stats.accumulate_stats(*db, rset);
RETURN(true);
}
void Weight::Internal::accumulate_stats(const Xapian::Database::Internal &subdb, const Xapian::RSet &rset) {
#ifdef XAPIAN_ASSERTIONS
Assert(!finalised);
++subdbs;
#endif
total_length += subdb.get_total_length();
collection_size += subdb.get_doccount();
rset_size += rset.size();
total_term_count += subdb.get_doccount() * subdb.get_total_length();
Xapian::TermIterator t;
for (t = query.get_unique_terms_begin(); t != Xapian::TermIterator(); ++t) {
const string & term = *t;
Xapian::doccount sub_tf;
Xapian::termcount sub_cf;
subdb.get_freqs(term, &sub_tf, &sub_cf);
TermFreqs & tf = termfreqs[term];
tf.termfreq += sub_tf;
tf.collfreq += sub_cf;
}
const set<:docid> & items(rset.internal->get_items());
set<:docid>::const_iterator d;
for (d = items.begin(); d != items.end(); ++d) {
Xapian::docid did = *d;
Assert(did);
// The query is likely to contain far fewer terms than the documents,
// and we can skip the document‘s termlist, so look for each query term
// in the document.
AutoPtr
Weight::Internal::accumulate_stats:
total_length:db的总文档长度加和;
collection_size:db的总文档数量;
total_term_count: 存疑,变量名是term计数,实际上是总文档长度加和 * 总文档数量;
termfreqs: term的tf信息(term在多少个doc中出现)和cf信息(term在索引集合中出现的次数);
query中涉及到的所有term,都获取到它们的TF、IDF信息;
极致的压缩:VectorTermList,把几个string存储的term压缩存储到一个块内存中。如果使用vector来存储,则会增加30Byte每一个term。void MultiMatch::get_mset(Xapian::doccount first, Xapian::doccount maxitems,
Xapian::doccount check_at_least,
Xapian::MSet & mset,
Xapian::Weight::Internal & stats,
const Xapian::MatchDecider *mdecider,
const Xapian::KeyMaker *sorter) {
........
}
PostList * LocalSubMatch::get_postlist(MultiMatch * matcher, Xapian::termcount * total_subqs_ptr) {
LOGCALL(MATCH, PostList *, "LocalSubMatch::get_postlist", matcher | total_subqs_ptr);
if (query.empty()) {
RETURN(new EmptyPostList); // MatchNothing
}
// Build the postlist tree for the query. This calls
// LocalSubMatch::open_post_list() for each term in the query.
PostList * pl;
{
QueryOptimiser opt(*db, *this, matcher);
pl = query.internal->postlist(&opt, 1.0);
*total_subqs_ptr = opt.get_total_subqs();
}
AutoPtr<:weight> extra_wt(wt_factory->clone());
// Only uses term-independent stats.
extra_wt->init_(*stats, qlen);
if (extra_wt->get_maxextra() != 0.0) {
// There‘s a term-independent weight contribution, so we combine the
// postlist tree with an ExtraWeightPostList which adds in this
// contribution.
pl = new ExtraWeightPostList(pl, extra_wt.release(), matcher);
}
RETURN(pl);
}
PostingIterator::Internal * QueryOr::postlist(QueryOptimiser * qopt, double factor) const {
LOGCALL(QUERY, PostingIterator::Internal *, "QueryOr::postlist", qopt | factor);
OrContext ctx(qopt, subqueries.size());
do_or_like(ctx, qopt, factor);
RETURN(ctx.postlist());
}
void QueryBranch::do_or_like(OrContext& ctx, QueryOptimiser * qopt, double factor, Xapian::termcount elite_set_size, size_t first) const {
LOGCALL_VOID(MATCH, "QueryBranch::do_or_like", ctx | qopt | factor | elite_set_size);
// FIXME: we could optimise by merging OP_ELITE_SET and OP_OR like we do
// for AND-like operations.
// OP_SYNONYM with a single subquery is only simplified by
// QuerySynonym::done() if the single subquery is a term or MatchAll.
Assert(subqueries.size() >= 2 || get_op() == Query::OP_SYNONYM);
vector
LeafPostList * LocalSubMatch::open_post_list(const string& term,
Xapian::termcount wqf,
double factor,
bool need_positions,
bool in_synonym,
QueryOptimiser * qopt,
bool lazy_weight) {
LOGCALL(MATCH, LeafPostList *, "LocalSubMatch::open_post_list", term | wqf | factor | need_positions | qopt | lazy_weight);
bool weighted = (factor != 0.0 && !term.empty());
LeafPostList * pl = NULL;
if (!term.empty() && !need_positions) {
if ((!weighted && !in_synonym) ||
!wt_factory->get_sumpart_needs_wdf_()) {
Xapian::doccount sub_tf;
db->get_freqs(term, &sub_tf, NULL);
if (sub_tf == db->get_doccount()) {
// If we‘re not going to use the wdf or term positions, and the
// term indexes all documents, we can replace it with the
// MatchAll postlist, which is especially efficient if there
// are no gaps in the docids.
pl = db->open_post_list(string());
// Set the term name so the postlist looks up the correct term
// frequencies - this is necessary if the weighting scheme
// needs collection frequency or reltermfreq (termfreq would be
// correct anyway since it‘s just the collection size in this
// case).
pl->set_term(term);
}
}
}
if (!pl) {
const LeafPostList * hint = qopt->get_hint_postlist();
if (hint)
pl = hint->open_nearby_postlist(term);
if (!pl)
pl = db->open_post_list(term);
qopt->set_hint_postlist(pl);
}
if (lazy_weight) {
// Term came from a wildcard, but we may already have that term in the
// query anyway, so check before accumulating its TermFreqs.
mapstring, TermFreqs>::iterator i = stats->termfreqs.find(term);
if (i == stats->termfreqs.end()) {
Xapian::doccount sub_tf;
Xapian::termcount sub_cf;
db->get_freqs(term, &sub_tf, &sub_cf);
stats->termfreqs.insert(make_pair(term, TermFreqs(sub_tf, 0, sub_cf)));
}
}
if (weighted) {
Xapian::Weight * wt = wt_factory->clone();
if (!lazy_weight) {
wt->init_(*stats, qlen, term, wqf, factor); // BM25Weight::init()计算不涉及query跟doc相关性部分的打分(只跟term和query相关)
stats->set_max_part(term, wt->get_maxpart());
} else {
// Delay initialising the actual weight object, so that we can
// gather stats for the terms lazily expanded from a wildcard
// (needed for the remote database case).
wt = new LazyWeight(pl, wt, stats, qlen, wqf, factor);
}
pl->set_termweight(wt);
}
RETURN(pl);
}
void BM25Weight::init(double factor) {
Xapian::doccount tf = get_termfreq();
double tw = 0;
if (get_rset_size() != 0) {
Xapian::doccount reltermfreq = get_reltermfreq();
// There can‘t be more relevant documents indexed by a term than there
// are documents indexed by that term.
AssertRel(reltermfreq,,tf);
// There can‘t be more relevant documents indexed by a term than there
// are relevant documents.
AssertRel(reltermfreq,,get_rset_size());
Xapian::doccount reldocs_not_indexed = get_rset_size() - reltermfreq;
// There can‘t be more relevant documents not indexed by a term than
// there are documents not indexed by that term.
AssertRel(reldocs_not_indexed, tf);
Xapian::doccount Q = get_collection_size() - reldocs_not_indexed;
Xapian::doccount nonreldocs_indexed = tf - reltermfreq;
double numerator = (reltermfreq + 0.5) * (Q - tf + 0.5);
double denom = (reldocs_not_indexed + 0.5) * (nonreldocs_indexed + 0.5);
tw = numerator / denom;
} else {
tw = (get_collection_size() - tf + 0.5) / (tf + 0.5);
}
AssertRel(tw,>,0);
// The "official" formula can give a negative termweight in unusual cases
// (without an RSet, when a term indexes more than half the documents in
// the database). These negative weights aren‘t actually helpful, and it
// is common for implementations to replace them with a small positive
// weight or similar.
//
// Truncating to zero doesn‘t seem a great approach in practice as it
// means that some terms in the query can have no effect at all on the
// ranking, and that some results can have zero weight, both of which
// are seem surprising.
//
// Xapian 1.0.x and earlier adjusted the termweight for any term indexing
// more than a third of documents, which seems rather "intrusive". That‘s
// what the code currently enabled does, but perhaps it would be better to
// do something else. (FIXME)
#if 0
if (rare(tw 1.0)) {
termweight = 0;
} else {
termweight = log(tw) * factor;
if (param_k3 != 0) {
double wqf_double = get_wqf();
termweight *= (param_k3 + 1) * wqf_double / (param_k3 + wqf_double);
}
}
#else
if (tw 2) tw = tw * 0.5 + 1;
termweight = log(tw) * factor;
if (param_k3 != 0) {
double wqf_double = get_wqf();
termweight *= (param_k3 + 1) * wqf_double / (param_k3 + wqf_double);
}
#endif
termweight *= (param_k1 + 1);
LOGVALUE(WTCALC, termweight);
if (param_k2 == 0 && (param_b == 0 || param_k1 == 0)) {
// If k2 is 0, and either param_b or param_k1 is 0 then the document
// length doesn‘t affect the weight.
len_factor = 0;
} else {
len_factor = get_average_length();
// len_factor can be zero if all documents are empty (or the database
// is empty!)
if (len_factor != 0) len_factor = 1 / len_factor;
}
LOGVALUE(WTCALC, len_factor);
}
获取倒排列表,根据query-tree构建postlist-tree;同时,clone一个Weight对象,计算BM25所需要的计算因子;平均文档长度,文档的最短长度,term最大的wdf(term在某doc中出现的次数);
计算BM25公式的idf部分:tw = (get_collection_size() - tf + 0.5) / (tf + 0.5); termweight = log(tw) * factor;
计算BM25公式的term在query中的权重部分:double wqf_double = get_wqf(); termweight *= (param_k3 + 1) * wqf_double / (param_k3 + wqf_double);
计算BM25公式的term跟doc相关程度的一部分参数: termweight *= (param_k1 + 1);
计算BM25公式的平均长度分之一:len_factor = 1 / len_factor;
计算maxpart() ,BM25算法,没有地方用这个值;
倒排与链求交过程:
PostList * MultiAndPostList::find_next_match(double w_min)
0、第一个链表pos往前走一步;
1、取出第一个链表的元素;
2、find_next_match() --> check_helper() 将第二链表的pos往前走,保证第二链表当前位置大于等于第一链表;
3、取出来第二链表的当前元素,跟第一链表原始做比较;
4、如果不匹配则让第一链表往前走;PostList * MultiAndPostList::find_next_match(double w_min) {
advanced_plist0:
if (plist[0]->at_end()) {
did = 0;
return NULL;
}
did = plist[0]->get_docid();
for (size_t i = 1; i i) {
bool valid;
check_helper(i, did, w_min, valid);
if (!valid) {
next_helper(0, w_min);
goto advanced_plist0;
}
if (plist[i]->at_end()) {
did = 0;
return NULL;
}
Xapian::docid new_did = plist[i]->get_docid();
if (new_did != did) {
skip_to_helper(0, new_did, w_min);
goto advanced_plist0;
}
}
return NULL;
}
double LeafPostList::get_weight() const {
if (!weight) return 0;
Xapian::termcount doclen = 0, unique_terms = 0;
// Fetching the document length and number of unique terms is work we can
// avoid if the weighting scheme doesn‘t use them.
if (need_doclength)
doclen = get_doclength();
if (need_unique_terms)
unique_terms = get_unique_terms();
double sumpart = weight->get_sumpart(get_wdf(), doclen, unique_terms);
AssertRel(sumpart, get_maxpart());
return sumpart;
}
PostList * OrPostList::next(double w_min)
两个链表都取,每次取最小did;
percent_scale = greatest_wt_subqs_matched / double(total_subqs);
percent_scale /= greatest_wt;
首先跟命中词个数占总搜索term个数有关系,然后,跟最大的匹配得分有关系,percent_scale会作为percent的因子: