基于C#的机器学习--面部和动态检测-图像过滤器
2021-06-15 04:03
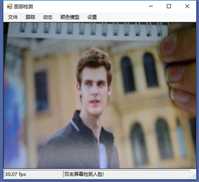
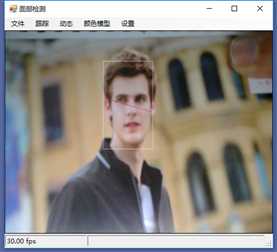
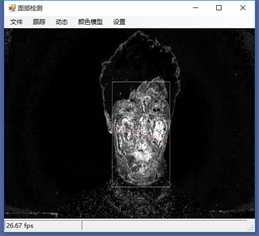
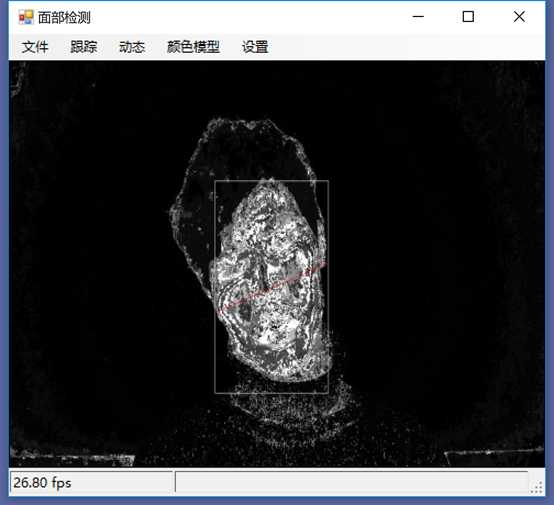
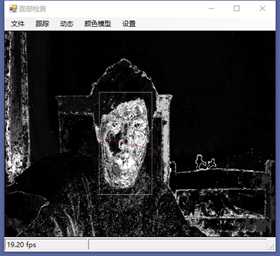
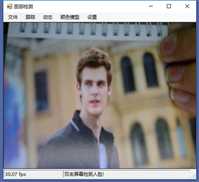
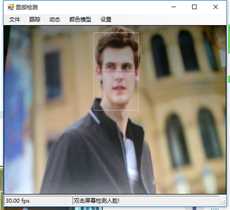
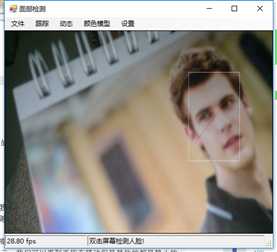
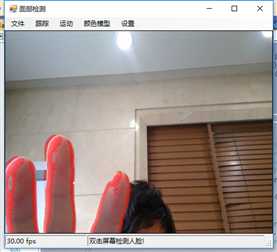
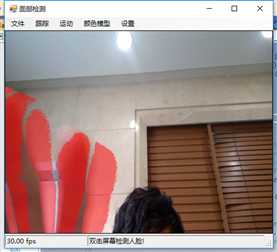
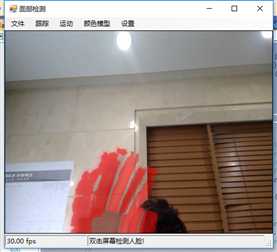
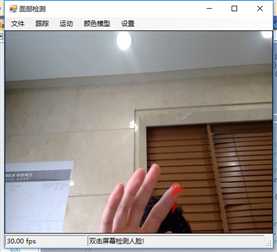
标签:vat 添加 sele color 阈值 evel ram flash 测试 在本章中,我们将展示两个独立的例子,一个用于人脸检测,另一个用于动态检测,以及如何快速地将这些功能添加到应用程序中。 在这一章中,我们将讨论: 人脸检测,是人脸识别的第一部分。如果你不能从屏幕上的所有东西中识别出一个或多个人脸,那么你将永远无法识别那是谁的脸。 首先让我们看一张我们的应用程序截图: 上图中,通过摄像头我们已经捕获到一张图像,接下来启用面部跟踪,看看会发生什么: 物体面部特征正在被追踪。我们在物体周围看到的是面部追踪器(白色线框),它告诉我们我们这里有一张脸;以及我们的角度探测器(红线),它提供了一些关于我们脸所处水平方向的参考。 当我们移动物体时,面部追踪器和角度探测器会追踪他。这一切都很好,但是如果我们在真实的人脸上启用面部跟踪会发生什么呢? 如下图,面部追踪器和角度探测器正在追踪人的面部。 当我们把头从一边移到另一边时,面部追踪器会跟踪这个动作,可以看到角度探测器会根据它所识别的面部水平角度进行调整。 可以看到,在这里我们的颜色是黑白的,而不是彩色的。因为这是一个直方图的反向投影,而且它是一个可以更改的选项。 即使我们远离摄像机,让其他物体也进入视野中,面部追踪器也能在诸多噪音中跟踪我们的脸,如下图所示。这正是我们在电影中看到的面部识别系统的工作原理,尽管它更为先进。 现在让我们深入程序内部,看看它到底是如何工作的。 首先,我们需要问自己一个问题,我们想要解决的问题到底是什么。到底是人脸识别还是人脸检测。这里不得不提到Viola-Jones算法,因为,首先它有很高的检出率和很低的误报率,然后它非常擅长对数据的实时处理,最终要的一点是,它非常善于从非人脸中分别出人脸。 要永远记住,人脸检测只是人脸识别的第一步! 这个算法要求输入一个完整的正面,垂直的脸。脸部需要直接指向采集设备,头部尽量不要歪,不要昂头或低头。 这里有必要在强调一次,我们要做的只是在图像中检测出人脸即可。 我们的算法需要经过四个步骤来完成这件事: 在正式开始之前,让我们先捋一捋面部检测到底是如果工作的。所有的脸,无论是人的,动物的还是其他的,都有一些相似的特征。例如,都有一个鼻子,两个鼻孔,一张嘴巴,两个眼睛,两个耳朵等等。我们的算法通过Haar特征来匹配这些内容,我们可以通过其中任一项找到其他的特征。 但是,我们这里会遇到一个问题。在一个24x24像素的窗口中,一共有162336个可能的特征。如果这个计算结果是正确的,那么计算他们的时间和成本将非常之高。因此,我们将会使用一种被称为adaptive boosting(自适应提升法)的算法,或者更为常见的AdaBoost算法。如果你研究过机器学习,我相信你听说过一种叫做boosting(提升)的技术。我们的学习算法将使用AdaBoost来选择最好的特征并训练分类器来使用它们。 AdaBoost可以与许多类型的学习算法一起使用,并且被业界认为是许多需要增强的任务的最佳开箱即用算法。通常在切换到另一种算法并对其进行基准测试之前,您不会注意到它有多好和多快。实际上这种区别是非常明显的。 在继续之前,我们先来了解一下什么是boosting(提升)技术。 Boosting从其他弱学习算法中获取输出,并将其与weighted sum(加权和)结合,加权和是boost分类器的最终输出。AdaBoost的自适应部分来自于这样一个事实,即后续的学习者被调整,以支持那些被以前的分类器错误分类的实例。 与其他算法相比,该算法更倾向于对数据进行过拟合,所以AdaBoost对噪声数据和异常值很敏感。因此我们在准备数据的时候,需要格外注意这一点。 现在,让我们来看看示例中的程序到底是如何工作的。对于这个示例,我们将再次使用Accord框架。 首先创建一个FaceHaarCascade对象。该对象包含一系列 Haarlike 的特征的弱分类阶段的集合。每个阶段都包含一组分类器树, 这些分类器树将在决策过程中使用。FaceHaarCascade自动为我们创建了所有这些阶段和树,而不需要我们去关心具体实现的细节。 首先,需要在底层构建一个决策树,它将为每个阶段提供节点,并为每个特性提供数值。以下是Accord的部分源码。 一旦构建完成,我们就可以使用cascade对象来创建HaarObjectDetector,这就是我们将用于检测的对象。 接下来我们需要提供: 现在,我们需要准备数据,在本示例中,我们将使用笔记本电脑上的摄像头捕获所有图像。然而,Accord.NET framework 使得使用其他源进行数据采集变得很容易。例如 avi文件,jpg文件等等。 接下来,连接摄像头,选择分辨率: 在这个演示中,你会注意到检测物体正对着摄像机,在背景中,还有一些其他的东西,那就是所谓的随机噪声。这样做是为了展示人脸检测算法是如何区分出脸的。如果我们的探测器不能处理这些,它就会在噪声中消失,从而无法检测到脸。 随着视频源的加入,我们需要在接收到新的视频帧时得到通知,以便处理它、应用标记,等等。我们通过频源播放器的NewFrameReceived事件来实现这一点。\ 在我们已经有了一个视频源和一个视频,让我们看看每当我们被通知有一个新的视频帧可用时发生了什么。 我们需要做的第一件事是对图像进行采样,以使它更容易工作: 如果我们没有找到一张脸,我们将保持跟踪模式,等待一个具有可检测面部的帧。一旦我们找到了面部区域,我们需要重置跟踪器,定位脸部,减小它的大小,以尽可能的剔除背景噪声,然后初始化跟踪器,并将在图像上进行标记。代码如下: 一旦检测到脸,我们的图像帧是这样的: 如果把头偏向一边,我们现在的形象应该是这样的: 可以看到,在上一个例子中,我们不仅实现了面部检测,还实现了动态检测。现在,让我们把目光转向更大的范围,检测任何物体的运动,而不仅仅是面部。我们将继续使用Accord.NET来实现。 在动态检测中,我们会用红色高亮显示屏幕上的任何运动。移动的数量由任何一个区域的红色浓度表示。所以,如下图所示,我们可以看到手指在移动但是其他的都是静止的。 如下图所示,可以看到整个手的移动范围在增加。 如下图所示,一旦整只手开始移动,你不仅可以看到更多的红色,而且红色的总量是在增加的: 如果不希望对整个屏幕区域进行运动处理,可以自定义运动区域;运动检测只会发生在这些区域。如下图,可以看到我们已经定义了一个运动区域,这是唯一的一个区域。 现在,如果我们在摄像头前面做一些运动,可以看到程序只检测到了来自我们定义区域发生的运动。 现在,我们来做这样一个测试,在我们自定义的检测区域范围内,放置一个物体,然后我们把手放在这个物体后面进行运动,当然手也是在这个自定义的检测区域范围内进行运动的。如下图,可以看到,手的运动被检测出来了。 现在我们使用另一个选项,网格运动突出显示。它会使得检测到的运动区域基于定义的网格在红色方块中突出显示,如下图所示。 以下是处理接收到新的帧的代码: 这里的关键是检测视频帧中发生的动量,这是通过以下代码完成的。对于本例,我们使用的是两级的运动报警级别,但是你也可以使用任何你喜欢的级别定义。一旦超过这个阈值,就可以实现所需的逻辑,例如发送电子邮件、开始视频捕获等等。 在这一章中,我们学习了面部和动态检测,还展示了一些简单易用的代码。我们可以轻松的将这些功能添加到自己的程序中。 基于C#的机器学习--面部和动态检测-图像过滤器 标签:vat 添加 sele color 阈值 evel ram flash 测试 原文地址:https://www.cnblogs.com/wangzhenyao1994/p/10386907.html
面部检测
List
HaarCascade cascade = new FaceHaarCascade();
detector = new HaarObjectDetector(
cascade,
25,
ObjectDetectorSearchMode.Single,
1.2f,
ObjectDetectorScalingMode.GreaterToSmaller
);// 创建视频源
VideoCaptureDevice videoSource = new VideoCaptureDevice(form.VideoDevice);
// 设置帧的大小
videoSource.VideoResolution = selectResolution(videoSource);
///
ResizeNearestNeighbor resize = new ResizeNearestNeighbor(160, 120);
UnmanagedImage downsample = resize.Apply(im);
Rectangle[] regions = detector?.ProcessFrame(downsample);
if (regions != null && regions.Length > 0)
{
tracker?.Reset();
// 跟踪第一张脸
Rectangle face = regions[0];
// 减小人脸检测的大小,避免跟踪背景上的其他内容
Rectangle window = new Rectangle(
(int)((regions[0].X + regions[0].Width / 2f) * xscale),
(int)((regions[0].Y + regions[0].Height / 2f) * yscale),
1,
1
);
window.Inflate((int)(0.2f * regions[0].Width * xscale), (int)(0.4f * regions[0].Height * yscale));
if (tracker != null)
{
tracker.SearchWindow = window;
tracker.ProcessFrame(im);
}
marker = new RectanglesMarker(window);
marker.ApplyInPlace(im);
eventArgs.Frame = im.ToManagedImage();
tracking = true;
}
else
{
detecting = true;
} 
动态检测

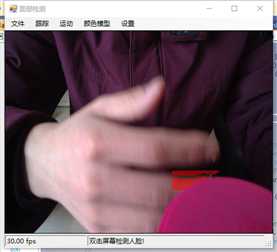
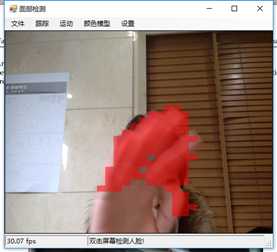
将检测添加到应用程序中
private void videoSourcePlayer_NewFrame(object sender, NewFrameEventArgs args)
{
lock (this)
{
if (motionDetector != null)
{
float motionLevel = motionDetector.ProcessFrame(args.Frame);
if (motionLevel > motionAlarmLevel)
{
//快门速度2秒
flash = (int)(2 * (1000 / timer.Interval));
}
//检查对象的数
if (motionDetector.MotionProcessingAlgorithm is BlobCountingObjectsProcessing)
{
BlobCountingObjectsProcessing countingDetector = (BlobCountingObjectsProcessing)motionDetector.MotionProcessingAlgorithm;
detectedObjectsCount = countingDetector.ObjectsCount;
}
else
{
detectedObjectsCount = -1;
}
// 积累的历史
motionHistory.Add(motionLevel);
if (motionHistory.Count > 300)
{
motionHistory.RemoveAt(0);
}
if (显示运动历史ToolStripMenuItem.Checked)
DrawMotionHistory(args.Frame);
}
}
}float motionLevel = motionDetector.ProcessFrame(args.Frame);
if (motionLevel > motionAlarmLevel)
{
//快门速度2秒
flash = (int)(2 * (1000 / timer.Interval));
}
总结
文章标题:基于C#的机器学习--面部和动态检测-图像过滤器
文章链接:http://soscw.com/index.php/essay/94058.html