java内存模型详解
2021-06-17 04:04
标签:执行顺序 并且 语言 并行 处理器 一个 设计 body http 对于本篇文章,将从四个概念来介绍:内存模型基础,重排序,顺序一致性和happens-before 1.内存模型基础 在并发编程中,有两个关键问题:线程之间如何通信和如何同步。由此而引出了两种并发模型:共享内存的并发模型和消息传递的并发模型。 1.1 消息传递的并发模型 该模型是指两个线程之间通过发送消息来进行显式的通信,而同步则是隐式进行的,因为发送消息的动作要先于接收消息。go语言采用的就是这种并发模型。 1.2 共享内存的并发模型 该模型是两个线程之间通过共享内存中的公共状态,然后读写公共状态来进行隐式通信的,而同步则需要显式的进行控制。java语言采用的就是共享内存的并发模型。 java线程之间的通信是由java内存模型(JMM)控制,它定义了主内存和线程之间的抽象关系:线程之间的共享变量存储在主内存中,每个线程都有一个私有的本地内存,本地内存存储了该线程读/写共享变量的副本,如下图: 如图,如果线程A和线程B想要通信,需要经过以下步骤: 如此一来,线程A和线程B就通过主内存进行间接的通信了。这就是java内存模型的概念。 2.重排序 2.1 重排序概念 重排序是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种手段。通过下面一个例子来说明: a = 1; //A1 x = b; //A2 b = 2; //B1 y = a; //B2 初始状态:a = b = 0 处理器执行后可能得到的结果:x = y = 0 假设处理器A和处理器B按程序的顺序并行执行代码,可能得到的结果是x = y = 0;为什么呢?这就涉及到了重排序。我们知道处理器使用了写缓冲区临时保存了向内存中写入的数据,比如在步骤A1中,准确的说是分为了两个步骤 A1-1:把a = 1 保存到写缓冲区中,A1-2:把 a = 1 从缓冲区刷新到主内存中,只有这两个步骤都完成了,才可以说A1步骤完成了。考虑一下这种情况:A1-1 ===》A2 ===》A1-2,也就是说内存实际发生顺序变为了 A2 ===》A1,如果处理器B也是如此,此时得到的结果就是x = y = 0;因为处理器执行内存操作的顺序和内存操作实际发生的顺序不一致,这就是重排序。 2.2 重排序遵循的原则 2.2.1 数据依赖性 数据依赖性定义:如果同一个处理器和同一个线程的两个操作访问同一个变量,并且这两个操作中有一个是写操作,此时这两个操作之间就存在数据依赖性。数据依赖性有三种类型: a = 1; b = a; a = 1; b = 2; a = b; b = 1; 编译器和处理器可能会对操作做重排序,但是会遵守数据依赖性,不会改变存在数据依赖关系的两个操作的执行顺序。这里的数据依赖性是指单个处理器和单个线程中执行的操作。 2.2.2 遵守as-if-serial语义 as-if-serial的语义是:无论怎么重排序,单线程程序的执行结果是不能改变的。为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序。 3. 顺序一致性内存模型 顺序一致性内存模型,是一个理想化的理论参考模型,它提供了极强的内存可见性。它有两大特征: 4.happens-before happens-before是JMM的核心概念,JMM的设计者,在设计JMM时考虑两个因素:从程序员的角度,使用JMM时希望是一个强内存模型,易于使用;从编译器和处理器的角度,希望JMM是一个弱内存模型,对它的束缚越少越好,这样它能最大程度的优化来提高性能。 最终,JMM遵循了一个原则:在不改变程序执行结果(单线程程序和正确同步的多线程程序)的前提下,处理器和编译器怎么优化都可以。 4.1 happens-before的定义 4.2 happens-before规则 参考《java并发编程的艺术》 java内存模型详解 标签:执行顺序 并且 语言 并行 处理器 一个 设计 body http 原文地址:https://www.cnblogs.com/51life/p/9687081.html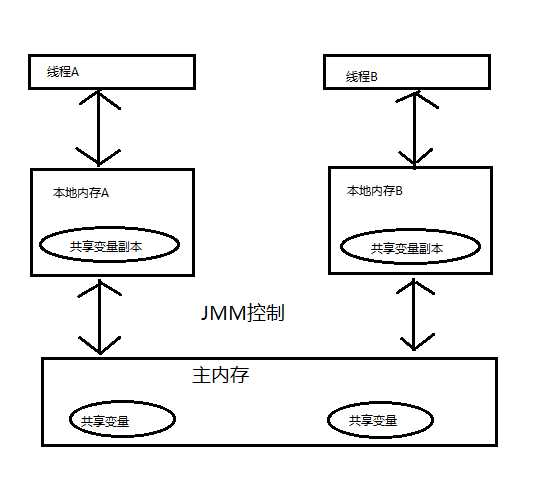
处理器A
处理器B
代码
运行结果
名称
代码示例
说明
写后读
写一个变量之后,再读这个变量
写后写
写这个变量之后,再写这个变量
读后写
读一个变量之后,再写这个变量
下一篇:【转】Python分布式进程