Java分布式锁,搞懂分布式锁实现看这篇文章就对了
2021-06-18 20:04
标签:失效 cos 还需 cost 数据一致性 选中 cond 开篇 锁定 前言 随着互联网的兴起,越来越多的人使用者互联网产品。一般互联网系统都是分布式部署的,分布式部署确实能带来性能和效率上的提升,提升效率的同事,我们还需要注意,保证一个分布式环境下数据一致性的问题。 在单机时代,虽然不存在分布式锁,但也会面临资源互斥的情况,只不过在单机的情况下,如果有多个线程要同时访问某个共享资源的时候,我们可以采用线程间加锁的机制,即当某个线程获取到这个资源后,就需要对这个资源进行加锁,当使用完资源之后,再解锁,其它线程就可以接着使用了。例如,在JAVA中,甚至专门提供了一些处理锁机制的一些API(synchronize/Lock等)。 但是到了分布式系统的时代,这种线程之间的锁机制,就没作用了,系统可能会有多份并且部署在不同的机器上,这些资源已经不是在线程之间共享了,而是属于进程之间共享的资源。因此,为了解决这个问题,「分布式锁」就强势登场了。 分布式锁是控制分布式系统之间同步访问共享资源的一种方式。在分布式系统中,常常需要协调他们的动作。如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,在这种情况下,便需要使用到分布式锁。 在分布式系统中,常常需要协调他们的动作。如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,这个时候,便需要使用到分布式锁。 分布式锁要满足哪些要求呢? 排他性:在同一时间只会有一个客户端能获取到锁,其它客户端无法同时获取 基于数据库来做分布式锁的话,通常有两种做法: 乐观锁机制其实就是在数据库表中引入一个版本号(version)字段来实现的。当我们要从数据库中读取数据的时候,同时把这个version字段也读出来,如果要对读出来的数据进行更新后写回数据库,则需要将version加1,同时将新的数据与新的version更新到数据表中,且必须在更新的时候同时检查目前数据库里version值是不是之前的那个version,如果是,则正常更新。如果不是,则更新失败,说明在这个过程中有其它的进程去更新过数据了。 看图叙事。模拟实战场景。 如上图,故事男主人公(以下简称男主)打算去ATM机取3000元,故事女主人公(以下简称女主)则要在某宝买买买,买个包需要3000元,账户的余额是5000元。如果没有采用锁的话,在两人同时取款和买买买,可能会出现合计消费了6000,导致账户余额异常。所以需要用到锁的机制,当男主女主甚至更多小主同时消费时,除了读取到6000的账户余额外,还需要读取到当前的版本号version=1,等先行消费成功的主人公(无论谁先消费)去出发修改账户余额的同时,会触发version=version+1,即version=2。那么其他人使用未更新的version(1)去更新账户余额时就会发现版本号不对,就会导致本次更新失败,就得重新去读取最新账户余额以及版本号。 如果大家想学习以下路线内容,在此我向大家推荐一个架构学习交流群。交流学习群号:874811168 里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化、分布式架构等这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多 乐观锁遵循的两点法则: 1.锁服务要有递增的版本号version 通常所说的“一锁二查三更新”即指的是使用悲观锁。通常来讲在数据库上的悲观锁需要数据库本身提供支持,即通过常用的select … for update操作来实现悲观锁。当数据库执行select for update时会获取被select中的数据行的行锁,因此其他并发执行的select for update如果试图选中同一行则会发生排斥(需要等待行锁被释放),因此达到锁的效果。select for update获取的行锁会在当前事务结束时自动释放,因此必须在事务中使用。 示例: 乐观锁的思路一般是表中增加版本字段,更新时where语句中增加版本的判断,算是一种CAS(Compare And Swep)操作,银行消费场景中version起到了版本控制的作用( AND version=#{version})。 悲观锁之所以是悲观,在于他认为本次操作会发生并发冲突,所以一开始就对银行账户加上锁(SELECT … FOR UPDATE),然后就可以安心的做判断和更新,因为这时候不会有别人更新账户余额。 基于Redis实现的锁机制,主要是依赖redis自身的原子操作,例如: SET user_key user_value NX PX 100 redis从2.6.12版本开始,SET命令才支持这些参数: NX:只在在键不存在时,才对键进行设置操作,SET key value NX 效果等同于 SETNX key value PX millisecond:设置键的过期时间为millisecond毫秒,当超过这个时间后,设置的键会自动失效 上述代码示例是指,当redis中不存在user_key这个键的时候,才会去设置一个user_key键,并且给这个键的值设置为 user_value,且这个键的存活时间为100ms 为什么这个命令可以帮我们实现锁机制呢? 因为这个命令是只有在某个key不存在的时候,才会执行成功。那么当多个进程同时并发的去设置同一个key的时候,就永远只会有一个进程成功。当某个进程设置成功之后,就可以去执行业务逻辑了,等业务逻辑执行完毕之后,再去进行解锁。 解锁很简单,只需要删除这个key就可以了,不过删除之前需要判断,这个key对应的value是当初自己设置的那个。 另外,针对redis集群模式的分布式锁,可以采用redis的Redlock(可能会被墙)机制。 其实基于ZooKeeper,就是使用它的临时有序节点来实现的分布式锁。 原理 当某客户端要进行逻辑的加锁时,就在zookeeper上的某个指定节点的目录下,去生成一个唯一的临时有序节点, 然后判断自己是否是这些有序节点中序号最小的一个,如果是,则算是获取了锁。如果不是,则说明没有获取到锁,那么就需要在序列中找到比自己小的那个节点,并对其调用exist()方法,对其注册事件监听,当监听到这个节点被删除了,那就再去判断一次自己当初创建的节点是否变成了序列中最小的。如果是,则获取锁,如果不是,则重复上述步骤。 当释放锁的时候,只需将这个临时节点删除即可。 如上图,locker是一个持久节点,node_1/node_2/…/node_n 就是上面说的临时节点,由客户端client去创建的。 client_1/client_2/…/clien_n 都是想去获取锁的客户端。以client_1为例,它想去获取分布式锁,则需要跑到locker下面去创建临时节点(假如是node_1)创建完毕后,看一下自己的节点序号是否是locker下面最小的,如果是,则获取了锁。如果不是,则去找到比自己小的那个节点(假如是node_2),找到后,就监听node_2,直到node_2被删除,那么就开始再次判断自己的node_1是不是序列中最小的,如果是,则获取锁,如果还不是,则继续找一下一个节点。 博客总结 其他参考资料: 出 处:http://www.cnblogs.com/toutou/ Java分布式锁,搞懂分布式锁实现看这篇文章就对了 标签:失效 cos 还需 cost 数据一致性 选中 cond 开篇 锁定 原文地址:https://www.cnblogs.com/wxy666/p/9706725.html
随着微处理机技术的发展,人们只需花几百美元就能买到一个CPU芯片,这个芯片每秒钟执行的指令比80年代最大的大型机的处理机每秒钟所执行的指令还多。如果你愿意付出两倍的价钱,将得到同样的CPU,但它却以更高的时钟速率运行。因此,最节约成本的办法通常是在一个系统中使用集中在一起的大量的廉价CPU。所以,倾向于分布式系统的主要原因是它可以潜在地得到比单个的大型集中式系统好得多的性价比。实际上,分布式系统是通过较低廉的价格来实现相似的性能的。分布式锁简述
避免死锁:这把锁在一段有限的时间之后,一定会被释放(正常释放或异常释放)
高可用:获取或释放锁的机制必须高可用且性能佳
…
目前相对主流的有三种,从实现的复杂度上来看,从上往下难度依次增加:
数据库(MySQL)
Redis
ZooKeeper基于数据库实现
1.基于数据库的乐观锁
2.基于数据库的悲观锁
乐观锁
乐观锁的特点先进行业务操作,不到万不得已不去拿锁。即“乐观”的认为拿锁多半是会成功的,因此在进行完业务操作需要实际更新数据的最后一步再去拿一下锁就好。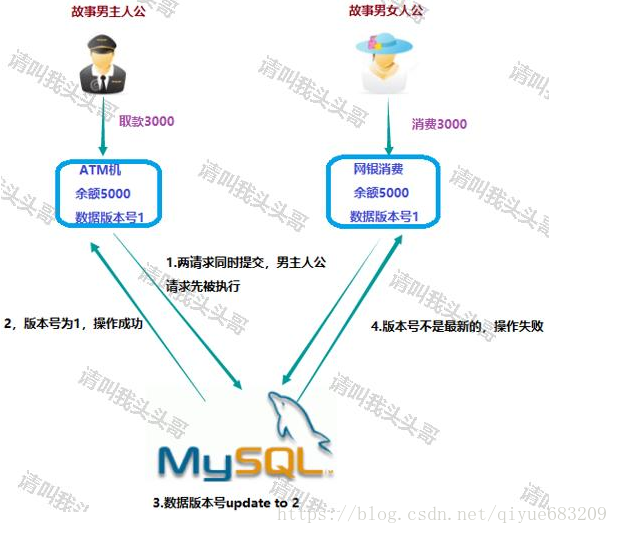
2.每次更新数据的时候都必须先判断版本号对不对,然后再写入新的版本号
悲观锁
悲观锁的特点是先获取锁,再进行业务操作,即“悲观”的认为获取锁是非常有可能失败的,因此要先确保获取锁成功再进行业务操作。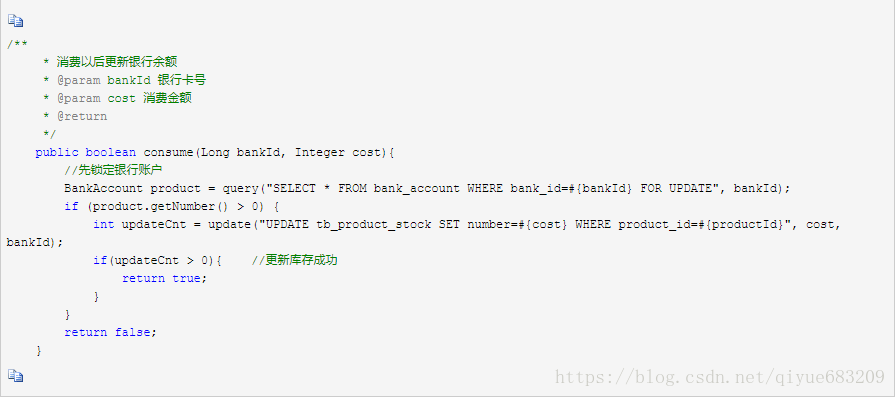
乐观锁与悲观锁的区别基于Redis实现
基于ZooKeeper实现
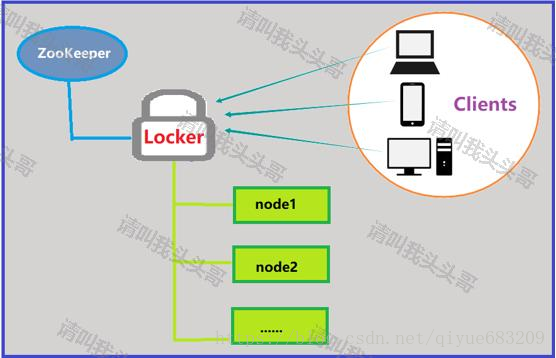
分布式锁有很多种,开篇说的"相对主流的有三种"只是针对我所遇到的。分布式锁未来肯定是千变万化的,无论你身处一个什么样的公司,最开始的工作可能都得尽可能的从简单的做起。希望大家能根据所在公司业务场景,选择适合所在项目的方案。
文章标题:Java分布式锁,搞懂分布式锁实现看这篇文章就对了
文章链接:http://soscw.com/index.php/essay/95628.html