java集合之List
2021-06-19 05:03
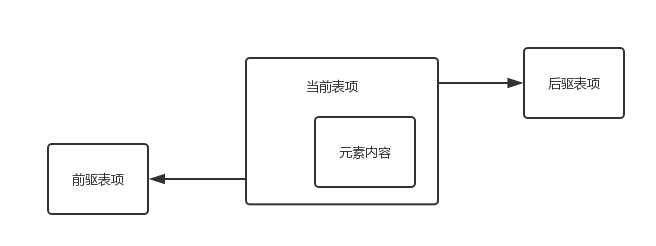
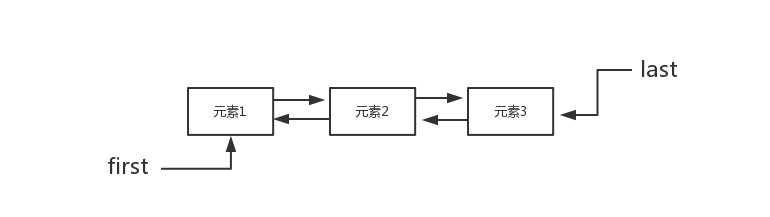
标签:com height 因此 sel 数组 功能 性能 over turn List是java重要的数据结构之一,我们经常接触到的有ArrayList、Vector和LinkedList三种,他们都继承来自java.util.Collection接口,类图如下 接下来,我们对比下这三种List的实现和不同: 一、基本实现 1、ArrayList和Vector使用了数组实现,可以认为它们封装了对内部数组的操作;它们两个底层的实现基本可以认为是一致的,主要的一点区别在于对多线程的支持上面。ArrayList没有对内部的方法做线程的同步,它不是线程安全的,而Vector内部做了线程同步,是线程安全的。 2、LinkedList使用了双向链表数据结构,与基于数组实现的ArrayList和Vector相比,这是一种不同的实现方式,这也决定了他们不同的应用场景。LinkedList链表由一系列列表项构成,一个表项包含三个部分:元素内容、前驱表项和后驱表项,如下图所示 在JDK的实现中,增加了两个节点指针first、last分别指向首尾节点 二、不同之处 在这里我们主要对比下ArrayList与LinkedList的不同之处 1、增加元素到列表尾端: 在ArrayList中增加元素到列表尾端 在这个过程当时,add的性能主要是由ensureCapacityInternal方法的实现,我们继续往下跟踪代码 calculateCapacity方法会根据你对ArrayList初始化的不同,对当前elmentData这个对象数组进行非空判断。如果它是一个空数组,则返回ArrayList默认容量和新容量比较的最大值,如果不为空则直接返回新容量。接下来在ensureExplicitCapacity方法中判断,如果新容量大于当前对象数组的长度则调用grow方法对数组进行扩容。 在这里我们可以看到如果ArrayList容量满足需求时,add()其实就是直接对数组进行赋值,性能很高。而当ArraList容量无法满足要求扩容时,需要对之前的数组进行复制操作。因此合理的数组大小有助于减少数组的扩容次数,如果使用时能够预估ArrayList数组大小,并进行初始化,指定容量大小对性能会有所提升。 在LinkedList中增加元素到列表尾端 LinkedList由于使用了链表结构,因此不需要维护容量的大小,这是相比ArrayList的优势。但每次元素的增加都需要新建一个node对象,并进行更多的赋值操作。在大数据量频繁的调用过程中,对性能会有所影响。 2、增加元素到任意位置: 由于实现上的不同,ArrayList和LinkedList在这个方法上存在存在一定的性能差异。由于ArrayList是基于数组实现的,而数组是一块连续的内存空间,如果在数组的任意位置插入元素,必然导致在该位置后的所有元素需要重新排列,因此效率会比较低。 ArrayList代码实现如下: 可以看到,ArrayList每次插入操作,都会进行一次数组复制。并且插入的元素在List中位置越靠前,数组重组的开销也越大。 再开LinkedList代码实现 LinkedList中定位一个节点需要遍历链表,如果新增的位置处于List的前半段,则从前往后找;若其位置处于后半段,则从后往前找。因此指定操作元素的位置越靠前或这靠后,效率都是非常高效的。但如果位置越靠中间,需要遍历半个List,效率较低。因此LinkedList中定位一个节点需要遍历链表,所以下标有关的插入、删除时间复杂度都变为O(n) ; 3、删除任意位置元素 对ArrayList来说,remove()方法和add()方法是相同的,在删除指定位置元素后,都要对数组进行重组。代码如下 可见,在进行一次有效删除后,都要进行数组的重组。并且跟add()指定位置的元素一样,删除元素的位置越靠前,重组时的开销就越大,删除的元素位置越靠后,开销越小 再看LinkedList中代码的实现如下 可见跟之前的插入任意位置一样,LinkedList中定位一个节点需要遍历链表,效率跟删除的元素的具体位置有关,所以删除任意位置元素时间复杂度也为O(n) ; 4、随机访问 首先看ArrayList的实现代码如下 可见ArrayList随机访问是直接读取数组第几个下标,效率很高。 LinkedList实现代码如下 相反LinkedList随机访问,每次都需要遍历半个List确定元素位置,效率较低。 5、总结 通过比较与分析ArrayList与LinkList两种不同实现的的List的功能代码后,我个人感觉两种List的具体使用真的要看实际的业务场景,有些具体的功能如新增删除等操作根据实际情况,效率不可一概而论。在这里进行简单的分析只是为了个人加强理解,如有不正确的地方还望指出与海涵。 参考资料:《Java程序性能优化》 java集合之List 标签:com height 因此 sel 数组 功能 性能 over turn 原文地址:https://www.cnblogs.com/dafanjoy/p/9690568.html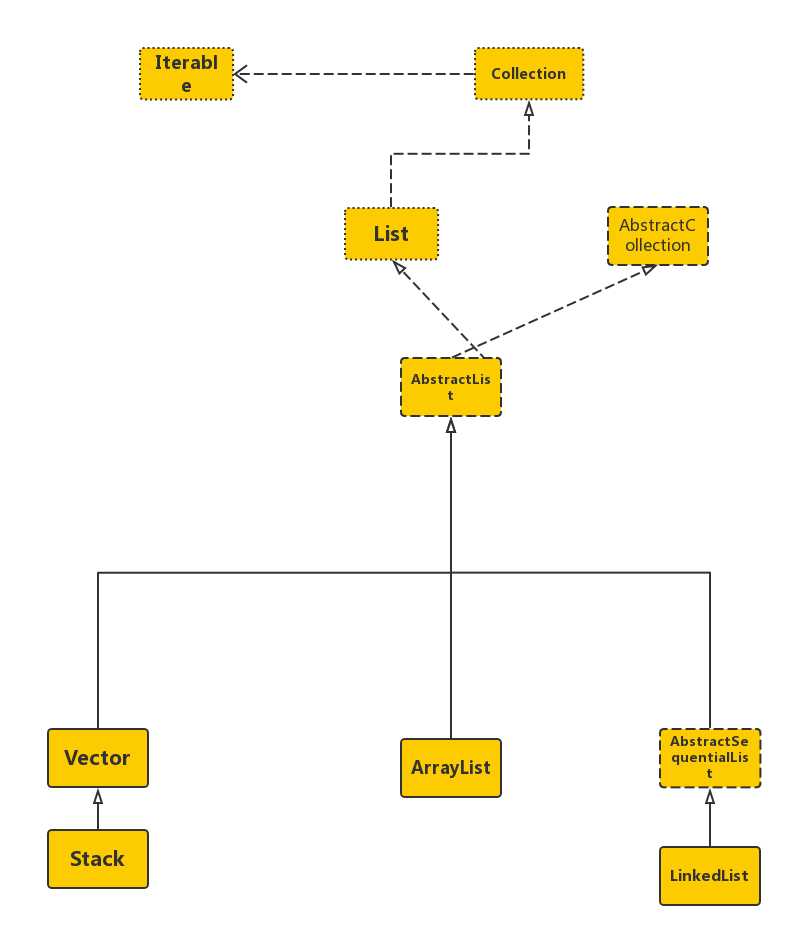
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 确保内部数组有足够的空间
elementData[size++] = e; //将元素加入到数组的末尾,完成添加
return true;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity )
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
//尾端插入,即将节点值为e的节点设置为链表的尾节点
void linkLast(E e) {
final Node
void add(int index, E element)
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//数组复制
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
Node
public E remove(int index)
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
//移动数组
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
Node
public E get(int index)
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node
上一篇:Python变量类型的强制转换
下一篇:Java使用