java面试题目
2021-06-20 11:06
标签:channel 事件 jpeg blocking 了解 factory 上下 比较 func
1.项目中Spring AOP用在什么地方,为什么这么用,切点,织入,通知,用自己的话描述一下,AOP原理,动态代理2种实现。
主要是事务那方面,采用声明式的事务配置方式,是AOP给你封装好的。
通知:
定义:切面也需要完成工作。在 AOP 术语中,切面的工作被称为通知。
工作内容:通知定义了切面是什么以及何时使用。除了描述切面要完成的工作,通知还解决何时执行这个工作。
Spring 切面可应用的 5 种通知类型:
Before——在方法调用之前调用通知
After——在方法完成之后调用通知,无论方法执行成功与否
After-returning——在方法执行成功之后调用通知
After-throwing——在方法抛出异常后进行通知
Around——通知包裹了被通知的方法,在被通知的方法调用之前和调用之后执行自定义的行为
连接点:
定义:连接点是一个应用执行过程中能够插入一个切面的点。 连接点可以是调用方法时、抛出异常时、甚至修改字段时、 切面代码可以利用这些点插入到应用的正规流程中 程序执行过程中能够应用通知的所有点。
切点:
定义:如果通知定义了“什么”和“何时”。那么切点就定义了“何处”。切点会匹配通知所要织入的一个或者多个连接点。 通常使用明确的类或者方法来指定这些切点。
作用:定义通知被应用的位置(在哪些连接点)
切面:
定义:切面是通知和切点的集合,通知和切点共同定义了切面的全部功能——它是什么,在何时何处完成其功能。
引入: 引入允许我们向现有的类中添加方法或属性
织入: 织入是将切面应用到目标对象来创建的代理对象过程。 切面在指定的连接点被织入到目标对象中,在目标对象的生命周期中有多个点可以织入。
AOP原理:面向切面编程,就是把可重用的功能提取出来,然后将这些通用功能在合适的时候织入到应用程序中,比如事务管理、权限控制、日志记录、性能统计等。
动态代理的实现:
CGLIB中的动态代理是JDK proxy的一个很好的补充,在JDK中实现代理时,要求代理类必须是继承接口的类,因为JDK最后生成的proxy class其实就是实现了被代理类所继承的接口并且继承了java中的Proxy类,通过反射找到接口的方法,调用InvocationHandler的invoke 方法实现拦截。CGLIb中最后生成的proxy class是一个继承被代理类的class,通过重写被代理类中的非final的方法实现代理。
总结为: JDK proxy:代理类必须实现接口,不需要引来第三方库
CGLIB: 代理类不能是final,代理的方法也不能是final(继承限制),针对类实现的代理,必须依赖CGLib类库。(hibernate中相关的代理采用的是CGLib来执行)。
2.Spring里面注解用过没有?autowired 和resource区别
@Resource和@Autowired都是做bean的注入时使用,其实@Resource并不是Spring的注解,它的包是javax.annotation.Resource,需要导入,但是Spring支持该注解的注入。
1、共同点
两者都可以写在字段和setter方法上。两者如果都写在字段上,那么就不需要再写setter方法。
2、不同点
(1)@Autowired
@Autowired为Spring提供的注解,需要导入包org.springframework.beans.factory.annotation.Autowired;只按照byType注入。

@Autowired注解是按照类型(byType)装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它的required属性为false。如果我们想使用按照名称(byName)来装配,可以结合@Qualifier注解一起使用。如下:
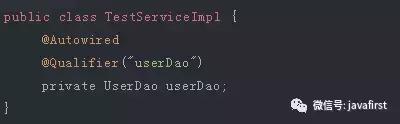
(2)@Resource
@Resource默认按照ByName自动注入,由J2EE提供,需要导入包javax.annotation.Resource。@Resource有两个重要的属性:name和type,而Spring将@Resource注解的name属性解析为bean的名字,而type属性则解析为bean的类型。
所以,如果使用name属性,则使用byName的自动注入策略,而使用type属性时则使用byType自动注入策略。如果既不制定name也不制定type属性,这时将通过反射机制使用byName自动注入策略。
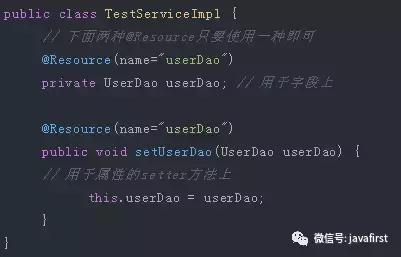
注:最好是将@Resource放在setter方法上,因为这样更符合面向对象的思想,通过set、get去操作属性,而不是直接去操作属性。
3.Linux命令,怎么日志文件里面找关键字
1、查看日志 前 n行:
cat 文件名 | head -n 数量
demo:
cat test.log | head -n 200 # 查看test.log前200行
2、查看日志 尾 n行:
cat 文件名 | tail -n 数量
demo:
cat test.log | tail -n 200 # 查看test.log倒数200行
3、根据 关键词 查看日志 并返回关键词所在行:
方法一:cat 路径/文件名 | grep 关键词
demo:
cat test.log | grep "http" # 返回test.log中包含http的所有行
方法二:grep -i 关键词 路径/文件名 (与方法一效果相同,不同写法而已)
demo:
grep -i "http" ./test.log # 返回test.log中包含http的所有行
单个文件可以使用vi或vim编辑器打开日志文件,使用编辑器里的查找功能。在查看模式下,符号/后面跟关键字向下查找,符号?后面跟关键字向上查找,按n查找下一个,按N查找上一个。
4.怎么杀死一个进程
方法1: 通过kill 进程id的方式可以实现, 首先需要知道进程id, 例如,想要杀死firefox的进程,通过 ps -ef|grep firefox,可以查到firefox的进程id: 然后通过 kill 3781 就可以关闭进程了. 补充: 1. kill -9 来强制终止退出, 例如: kill -9 3781 kill -9 -1 终止你拥有的全部进程。
方法2: killall 通过程序的名字,来杀死进程 例如: killall firefox 注意: 该命令可以使用 -9 参数来强制杀死进程, killall -9 firefox
方法3: pkill 通过程序的名字, 直接杀死所有进程 例如: pkill firefox
5.MQ,zookeeper,dubbo,redis,是否了解分布式,是否了解负载均衡?
MQ 消息队列(上游--消息队列--下游) 在高并发环境下,由于来不及同步处理,请求往往会发生阻塞,比如大量的insert、update之类的请求同时到达mysql,直接导致无数的行锁和表锁,从而触发too many connections错误,通过消息队列,可以异步处理请求,从而缓解系统压力。
MQ的不足是: 1)系统更复杂,多了一个MQ组件 2)消息传递路径更长,延时会增加 3)消息可靠性和重复性互为矛盾,消息不丢不重难以同时保证 4)上游无法知道下游的执行结果,这一点是很致命的。 调用方实时依赖执行结果的业务场景,请使用调用,而不是MQ。
什么时候使用MQ
【典型场景一:数据驱动的任务依赖】
什么是任务依赖,举个栗子,互联网公司经常在凌晨进行一些数据统计任务,这些任务之间有一定的依赖关系,比如:
1)task3需要使用task2的输出作为输入
2)task2需要使用task1的输出作为输入 这样的话,tast1, task2, task3之间就有任务依赖关系,必须task1先执行,再task2执行,载task3执行。
采用MQ解耦: 1)task1准时开始,结束后发一个“task1 done”的消息 2)task2订阅“task1 done”的消息,收到消息后第一时间启动执行,结束后发一个“task2 done”的消息 3)task3同理
采用MQ的优点是:
1)不需要预留buffer,上游任务执行完,下游任务总会在第一时间被执行
2)依赖多个任务,被多个任务依赖都很好处理,只需要订阅相关消息即可
3)有任务执行时间变化,下游任务都不需要调整执行时间
需要特别说明的是,MQ只用来传递上游任务执行完成的消息,并不用于传递真正的输入输出数据。
【典型场景二:上游不关心执行结果】
上游需要关注执行结果时要用“调用”,上游不关注执行结果时,就可以使用MQ了。
举个栗子,58同城的很多下游需要关注“用户发布帖子”这个事件,比如招聘用户发布帖子后,招聘业务要奖励58豆,房产用户发布帖子后,房产业务要送2个置顶,二手用户发布帖子后,二手业务要修改用户统计数据。
如果使用调用关系,会导致上下游逻辑+物理依赖严重
优化方案是,采用MQ解耦: 1)帖子发布成功后,向MQ发一个消息 2)哪个下游关注“帖子发布成功”的消息,主动去MQ订阅
其优点是:1.上游执行时间短,2.上下游逻辑+物理解耦,,模块之间不相互依赖.3.新增一个下游消息关注方,上游不需要修改任何代码
典型场景三:上游关注执行结果,但执行时间很长 有时候上游需要关注执行结果,但执行结果时间很长(典型的是调用离线处理,或者跨公网调用),也经常使用回调网关+MQ来解耦。
举个栗子,微信支付,跨公网调用微信的接口,执行时间会比较长,但调用方又非常关注执行结果,此时一般怎么玩呢?
一般采用“回调网关+MQ”方案来解耦:
1)调用方直接跨公网调用微信接口
2)微信返回调用成功,此时并不代表返回成功
3)微信执行完成后,回调统一网关
4)网关将返回结果通知MQ
5)请求方收到结果通知
总结
MQ是一个互联网架构中常见的解耦利器。
什么时候不使用MQ? 上游实时关注执行结果
什么时候使用MQ? 1)数据驱动的任务依赖
2)上游不关心多下游执行结果
3)异步返回执行时间长
zookeeper
1.ZooKeeper是什么?
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,它是集群的管理者,监视着集群中各个节点的状态,根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户
2.ZooKeeper提供了什么?
1)文件系统
2)通知机制
3.Zookeeper文件系统
每个子目录项如 NameService 都被称作为znode,和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
有四种类型的znode:
1、PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
2、PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3、EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
4、EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
4.Zookeeper通知机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
5.Zookeeper做了什么?
1.命名服务 2.配置管理 3.集群管理 4.分布式锁 5.队列管理
6.Zookeeper命名服务
在zookeeper的文件系统里创建一个目录,即有唯一的path。在我们使用tborg无法确定上游程序的部署机器时即可与下游程序约定好path,通过path即能互相探索发现。
7.Zookeeper的配置管理
程序总是需要配置的,如果程序分散部署在多台机器上,要逐个改变配置就变得困难。现在把这些配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好
8.Zookeeper集群管理
所谓集群管理无在乎两点:是否有机器退出和加入、选举master。
对于第一点,所有机器约定在父目录GroupMembers下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除,于是,所有人都知道:它上船了。
新机器加入也是类似,所有机器收到通知:新兄弟目录加入,highcount又有了,对于第二点,我们稍微改变一下,所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为master就好。
9.Zookeeper分布式锁
有了zookeeper的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
对于第一类,我们将zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除掉自己创建的distribute_lock 节点就释放出锁。
对于第二类, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选master一样,编号最小的获得锁,用完删除,依次方便。
10.Zookeeper队列管理
两种类型的队列:
1、同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
2、队列按照 FIFO 方式进行入队和出队操作。
第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。
11.Zookeeper设计目的
1.最终一致性:client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。
2.可靠性:具有简单、健壮、良好的性能,如果消息被到一台服务器接受,那么它将被所有的服务器接受。
3.实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
4.等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
5.原子性:更新只能成功或者失败,没有中间状态。
6.顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
12.Zookeeper工作原理
Zookeeper 的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和 leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
13.Zookeeper 下 Server工作状态
每个Server在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻
LEADING:当前Server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前Server与之同步
14.Zookeeper选主流程(basic paxos)
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。
1.选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
2.选举线程首先向所有Server发起一次询问(包括自己);
3.选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
4.收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
5.线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数,设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。 通过流程分析我们可以得出:要使Leader获得多数Server的支持,则Server总数必须是奇数2n+1,且存活的Server的数目不得少于n+1. 每个Server启动后都会重复以上流程。在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的server还会从磁盘快照中恢复数据和会话信息,zk会记录事务日志并定期进行快照,方便在恢复时进行状态恢复。
redis
Redis是一款开源的、高性能的键-值存储(key-value store)。它常被称作是一款数据结构服务器(data structure server)。
Redis的键是String类型,值可以包括字符串(strings)类型,同时它还包括哈希(hashes)、列表(lists)、集合(sets)和 有序集合(sorted sets)等数据类型。 对于这些数据类型,你可以执行原子操作。
为了获得优异的性能,Redis采用了内存中(in-memory)数据集(dataset)的方式。同时,Redis支持数据的持久化,需要经常将内存中的数据同步到磁盘来保证持久化。
Redis同样支持主从复制(master-slave replication),并且具有非常快速的非阻塞首次同步( non-blocking first synchronization)、网络断开自动重连等功能。同时Redis还具有其它一些特性,其中包括简单的事物支持、发布订阅 ( pub/sub)、管道(pipeline)和虚拟内存(vm)等 。
Redis功能:
持久化:
redis是一个支持持久化的内存数据库,即redis需要经常将内存中的数据同步到磁盘来保证持久化,这是相对memcache来说的一个大的优势。redis支持两种持久化方式,一种是 Snapshotting(快照)也是默认方式,另一种是Append-only file(缩写aof)的方式。
主从复制:
主从复制允许多个slave server拥有和master server相同的数据库副本。下面是关于redis主从复制的一些特点
1.master可以有多个slave。
2.除了多个slave连到相同的master外,slave也可以连接其他slave形成图状结构。
3.主从复制不会阻塞master。也就是说当一个或多个slave与master进行初次同步数据时,master可以继续处理client发来的请求。相反slave在初次同步数据时则会阻塞,不能处理client的请求。
4.主从复制可以用来提高系统的可伸缩性(我们可以用多个slave 专门用于client的读请求,比如sort操作可以使用slave来处理),也可以用来做简单的数据冗余。
5.可以在master禁用数据持久化,只需要注释掉master 配置文件中的所有save配置,然后只在slave上配置数据持久化。
事务:
redis对事务的支持目前还比较简单。redis只能保证一个client发起的事务中的命令可以连续的执行,而中间不会插入其他client的命令。
Multi 事物开始
Exec 执行事务
Discard 放弃事物
Watch 监听key
Unwatch 放弃所有key的监听
watch 命令会监视给定的key,当exec时候如果监视的key从调用watch后发生过变化,则整个事务会失败。注意watch的key是对整个连接有效的,和事务一样,如果连接断开,监视和事务都会被自动清除。
发布订阅:
发布订阅(pub/sub)是一种消息通信模式。订阅者可以通过subscribe和psubscribe命令向redis server订阅自己感兴趣的消息类型,redis将消息类型称为通道(channel)。当发布者通过publish命令向redis server发送特定类型的消息时。订阅该消息类型的全部client都会收到此消息。这里消息的传递是多对多的。一个client可以订阅多个 channel,也可以向多个channel发送消息。
Subscribe
Unsubscribe
Psubscribe
Punsubscribe
Publish
管道:
redis是一个cs模式的tcp server,使用和http类似的请求响应协议。一个client可以通过一个socket连接发起多个请求命令。每个请求命令发出后client通常 会阻塞并等待redis服务处理,redis处理完后请求命令后会将结果通过响应报文返回给client。
虚拟内存:
redis没有使用os提供的虚拟内存机制而是自己实现了自己的虚拟内存机制 ,但是思路和目的都是相同的。就是暂时把不经常访问的数据从内存交换到磁盘中,从而腾出内存空间用于其他需要访问的数据。
Redis应用场景:
1.取最新N个数据的操作
比如典型的取你网站的最新文章,通过下面方式,我们可以将最新的5000条评论的ID放在Redis的List集合中,并将超出集合部分从数据库获取
使用LPUSH latest.comments
插入完成后再用LTRIM latest.comments 0 5000命令使其永远只保存最近5000个ID
然后我们在客户端获取某一页评论时可以用下面的逻辑(伪代码)
FUNCTION get_latest_comments(start,num_items):
id_list = redis.lrange("latest.comments",start,start+num_items-1)
IF id_list.length id_list = SQL_DB("SELECT ... ORDER BY time LIMIT ...")
END
RETURN id_list
END
如果你还有不同的筛选维度,比如某个分类的最新N条,那么你可以再建一个按此分类的List,只存ID的话,Redis是非常高效的。
2.排行榜应用,取TOP N操作
这个需求与上面需求的不同之处在于,前面操作以时间为权重,这个是以某个条件为权重,比如按顶的次数排序,这时候就需要我们的sorted set出马了,将你要排序的值设置成sorted set的score,将具体的数据设置成相应的value,每次只需要执行一条ZADD命令即可。
3.需要精准设定过期时间的应用
比如你可以把上面说到的sorted set的score值设置成过期时间的时间戳,那么就可以简单地通过过期时间排序,定时清除过期数据了,不仅是清除Redis中的过期数据,你完全可以把Redis里这个过期时间当成是对数据库中数据的索引,用Redis来找出哪些数据需要过期删除,然后再精准地从数据库中删除相应的记录。
4.计数器应用
Redis的命令都是原子性的,你可以轻松地利用INCR,DECR命令来构建计数器系统。
5.Uniq操作,获取某段时间所有数据排重值
这个使用Redis的set数据结构最合适了,只需要不断地将数据往set中扔就行了,set意为集合,所以会自动排重。
6.实时系统,反垃圾系统
通过上面说到的set功能,你可以知道一个终端用户是否进行了某个操作,可以找到其操作的集合并进行分析统计对比等。没有做不到,只有想不到。
7.Pub/Sub构建实时消息系统
Redis的Pub/Sub系统可以构建实时的消息系统,比如很多用Pub/Sub构建的实时聊天系统的例子。
8.构建队列系统
使用list可以构建队列系统,使用sorted set甚至可以构建有优先级的队列系统。
9.缓存
这个不必说了,性能优于Memcached(在某些方面,并不是全面优于),数据结构更多样化。
Redis总结:
Redis使用最佳方式是全部数据in-memory。
Redis更多场景是作为Memcached的替代者来使用。
当需要除key/value之外的更多数据类型支持时,使用Redis更合适。
当存储的数据不能被剔除时,使用Redis更合适。(持久化)
对数据高并发读写
对海量数据的高效率存储和访问
对数据的高可扩展性和高可用性(分布式)
redis和memcached的区别:
1 Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
2 Redis支持数据的备份,即master-slave模式的数据备份。
3 Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
4 memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复
在Redis中,并不是所有的数据都一直存储在内存中的。这是和Memcached相比一个最大的区别(我个人是这么认为的)。
java面试题目
标签:channel 事件 jpeg blocking 了解 factory 上下 比较 func
原文地址:https://www.cnblogs.com/stonegarlic/p/9688755.html
下一篇:Java之路——Two