排序算法分享
2021-06-21 02:04
标签:.com 完成 length selection log code tmp 扫描 pytho 十种常见排序算法可以分为两大类: 稳定: 如果a原本在b前面,而a=b,排序之后a仍然在b的前面。 时间复杂度: 对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。 冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。 选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。 选择排序是表现最稳定的排序算法之一,因为无论什么数据进去都是O(n2)的时间复杂度,所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。理论上讲,选择排序可能也是平时排序一般人想到的最多的排序方法了吧。 n个记录的直接选择排序可经过n-1趟直接选择排序得到有序结果。具体算法描述如下: 插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。 一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下: 排序算法分享 标签:.com 完成 length selection log code tmp 扫描 pytho 原文地址:https://www.cnblogs.com/praglody/p/9686167.html排序算法分享
概述
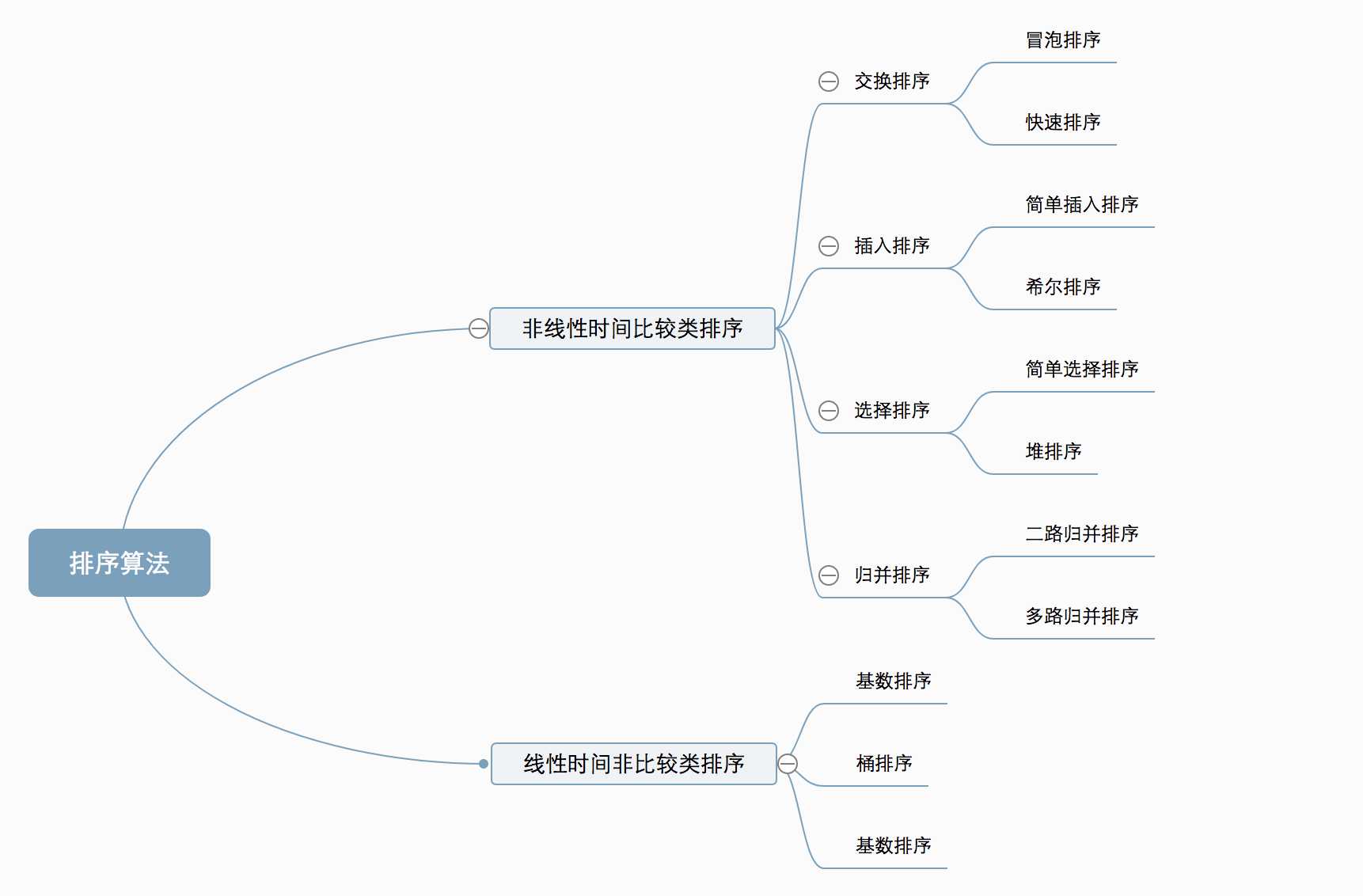
算法分类
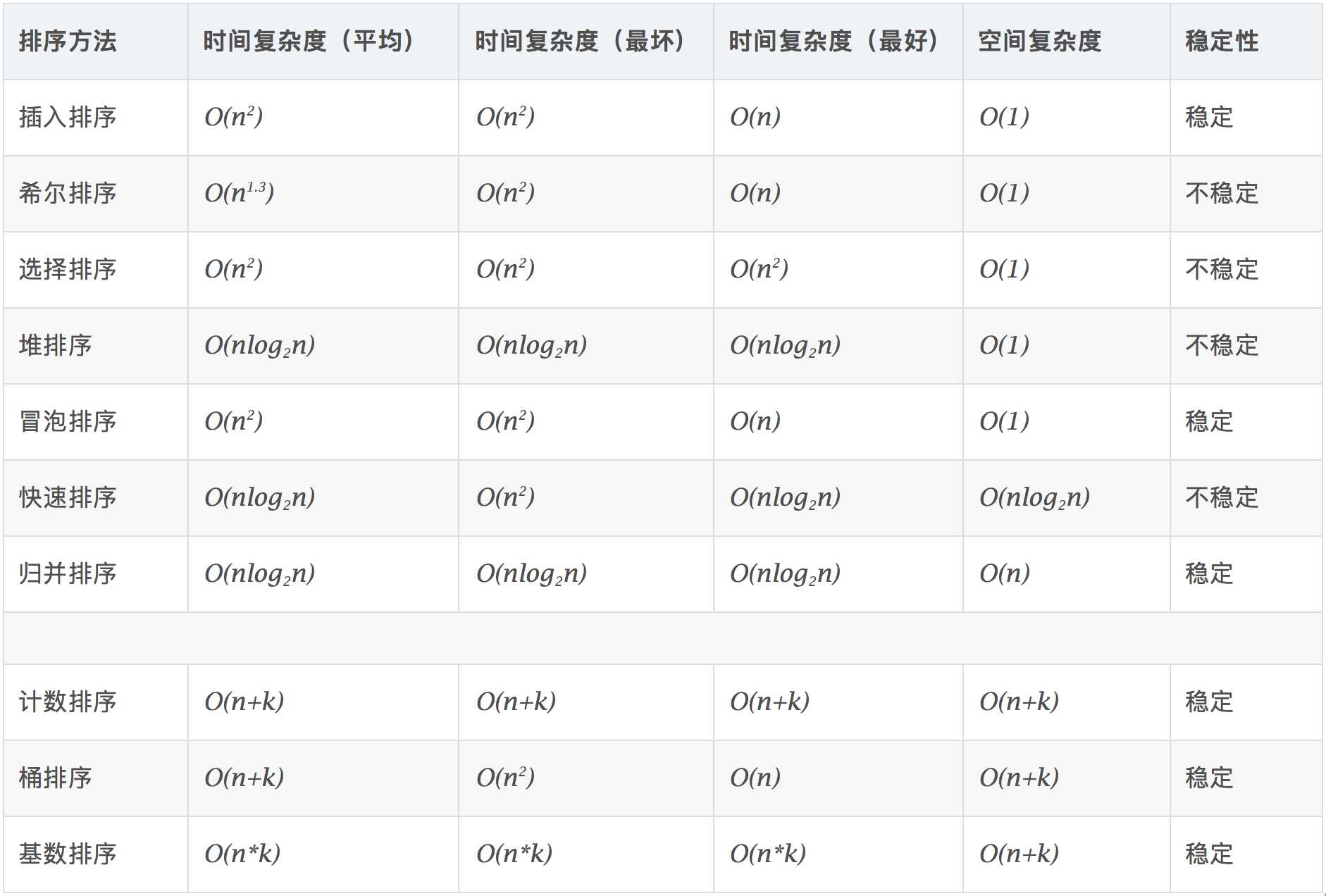
算法复杂度
相关概念
不稳定: 如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
空间复杂度: 是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。冒泡排序(Bubble Sort)
算法原理
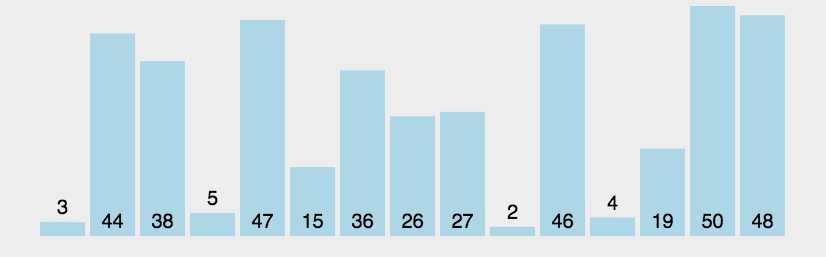
代码实现
def bubble_sort(L):
i = 0
flag = True
length = len(L)
while i i:
if L[j - 1] > L[j]:
L[j - 1], L[j] = L[j], L[j - 1]
flag = True
j = j - 1
i = i + 1
选择排序(Selection Sort)
算法原理
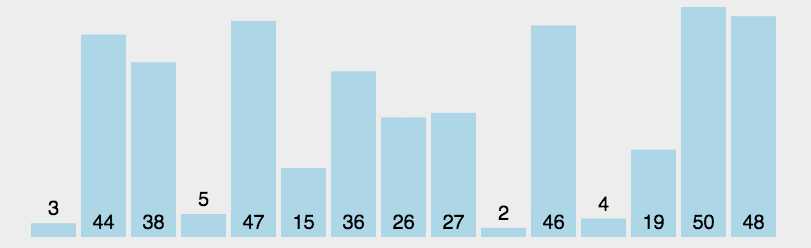
代码实现
def selection_sort(L):
i = 0
length = len(L)
while i L[j]:
min = j
j = j + 1
if i != min:
L[i], L[min] = L[min], L[i]
i = i + 1插入排序(Insertion Sort)
算法原理
代码实现
def insertion_sort(L):
for i in range(1, len(L)):
# 若下标为i的元素小于下标为i-1的元素,则将下标为i的元素放到合适位置
if L[i] = 0 and tmp