Python网络爬虫实战案例之:7000本电子书下载(4)
2021-06-21 08:05
标签:ima requests blog 正文 框架 jpg 剖析 alt c89 本文是《Python开发实战案例之网络爬虫》的第四部分:7000本电子书下载网络爬虫-源码框架剖析。配套视频课程详见:51CTO学院。 3.1 requests-html文件结构 上一篇: Python网络爬虫实战案例之:7000本电子书下载(4) 标签:ima requests blog 正文 框架 jpg 剖析 alt c89 原文地址:http://blog.51cto.com/hadoop2/2178106二、章节目录
3.2 requests-html源码框架
3.3 导入依赖库
3.4 HTMLSession请求类
3.5 HTMLResponse请求响应类
3.6 HTML页面结构类三、正文
3.1 requests-html 文件结构
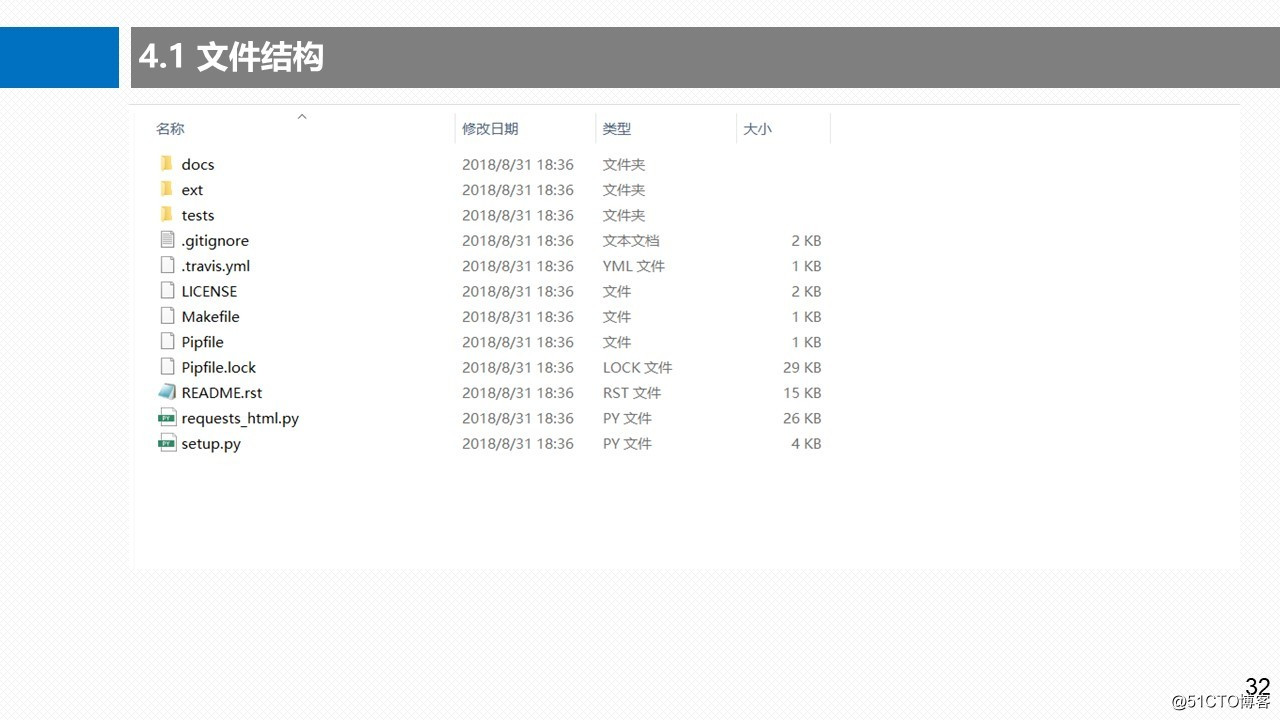
3.2 requests-html源码框架
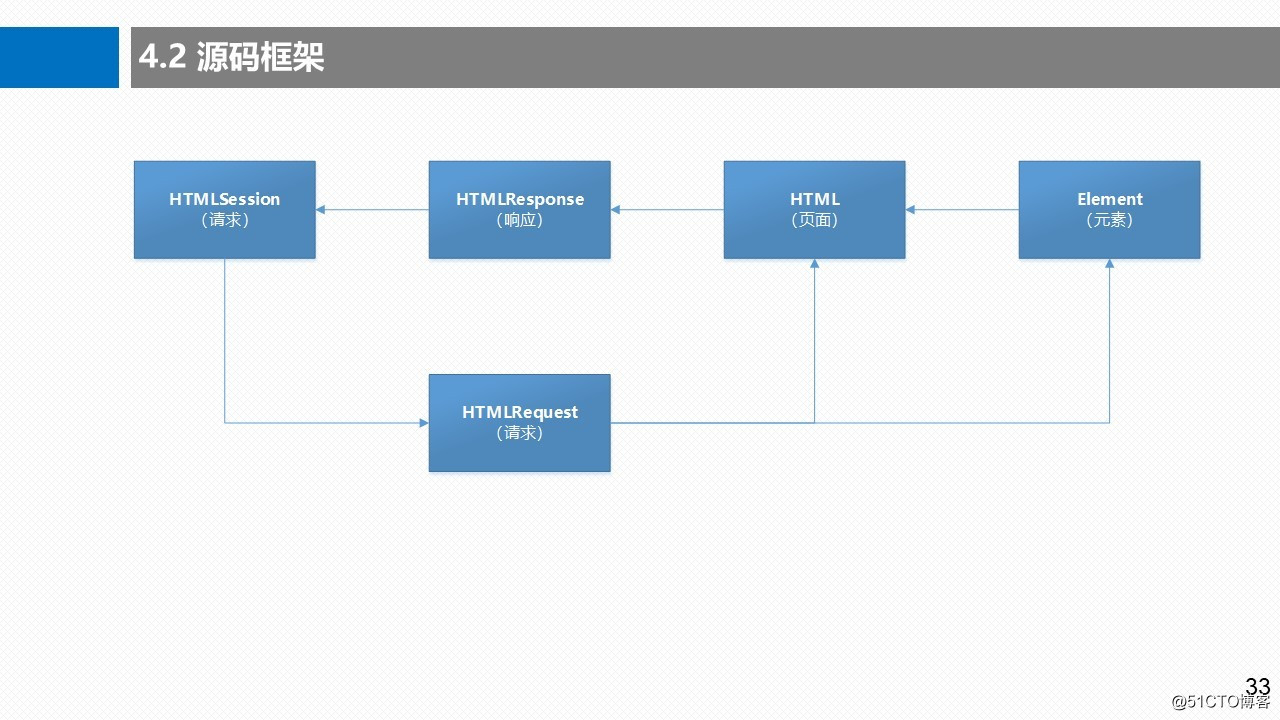
3.3 导入依赖库
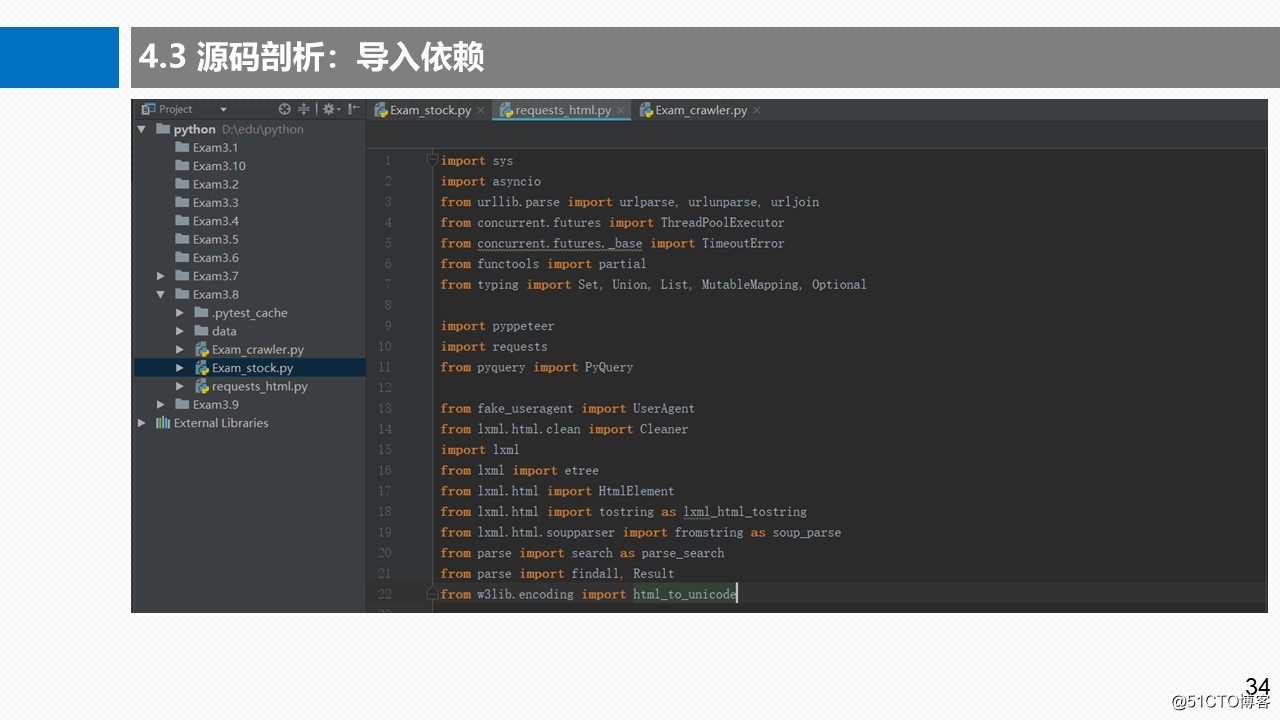
3.4 HTMLSession请求类
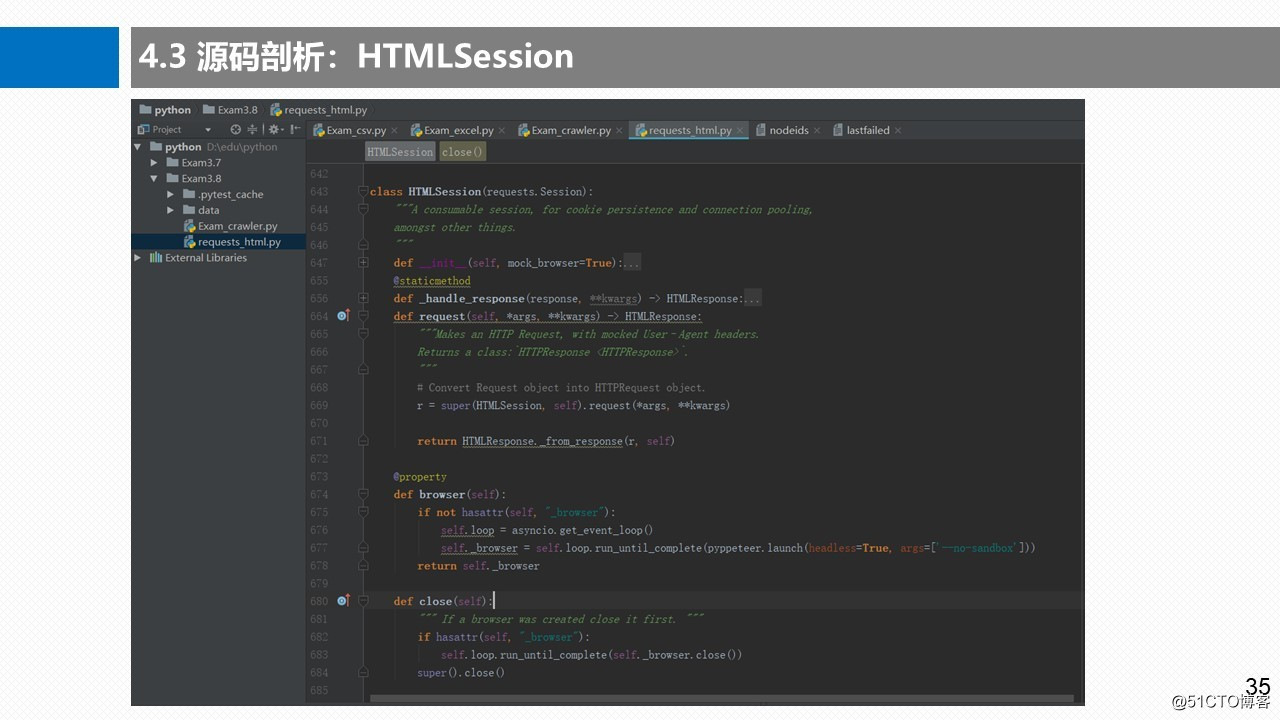
3.5 HTMLResponse请求响应类
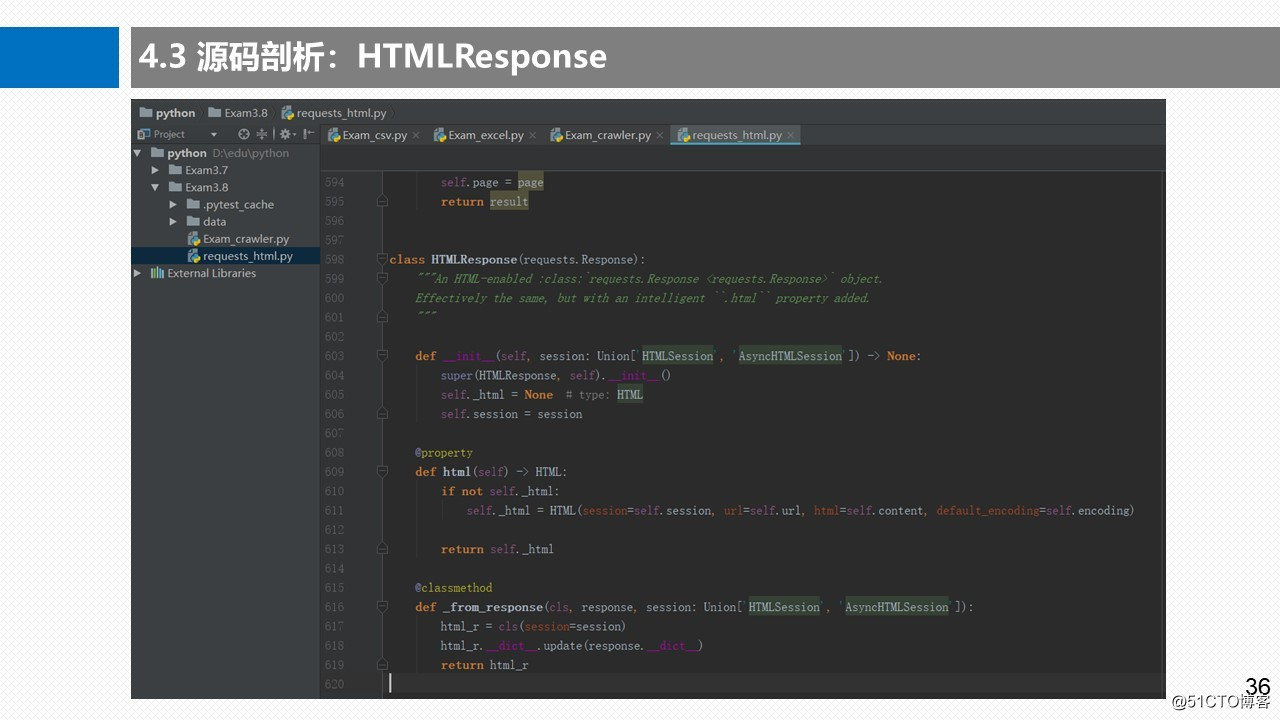
3.6 HTML页面结构类
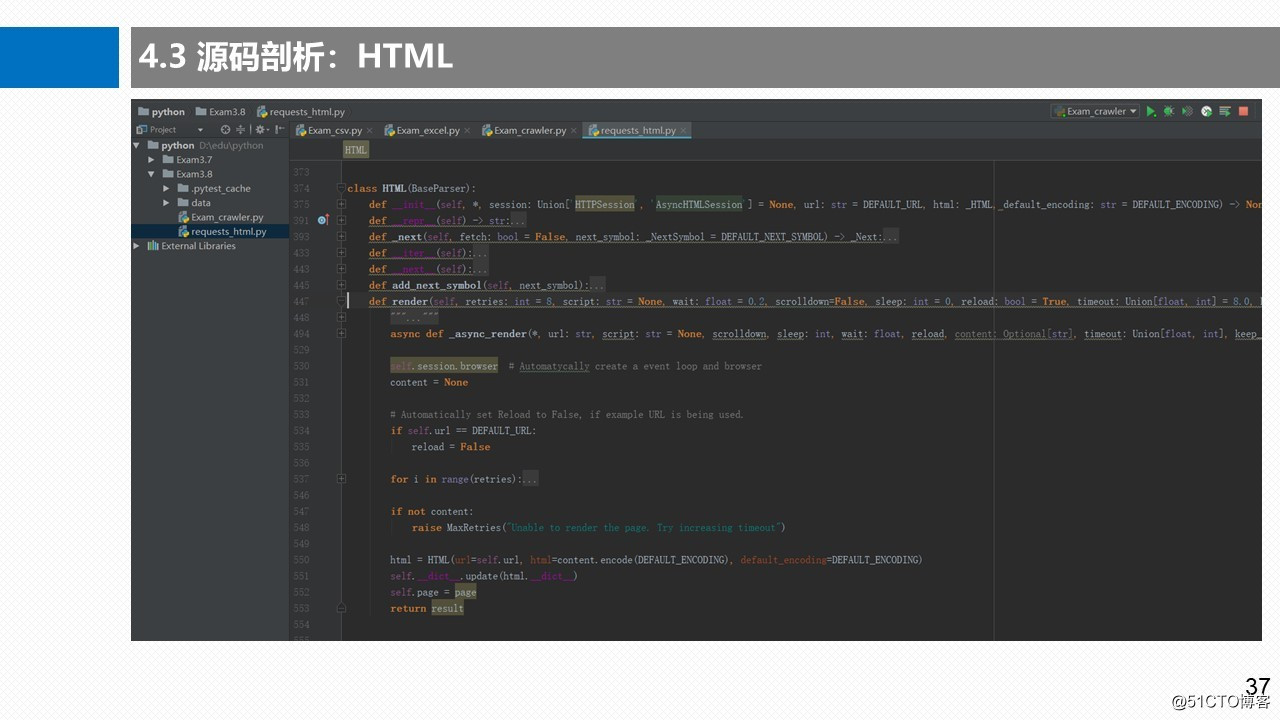
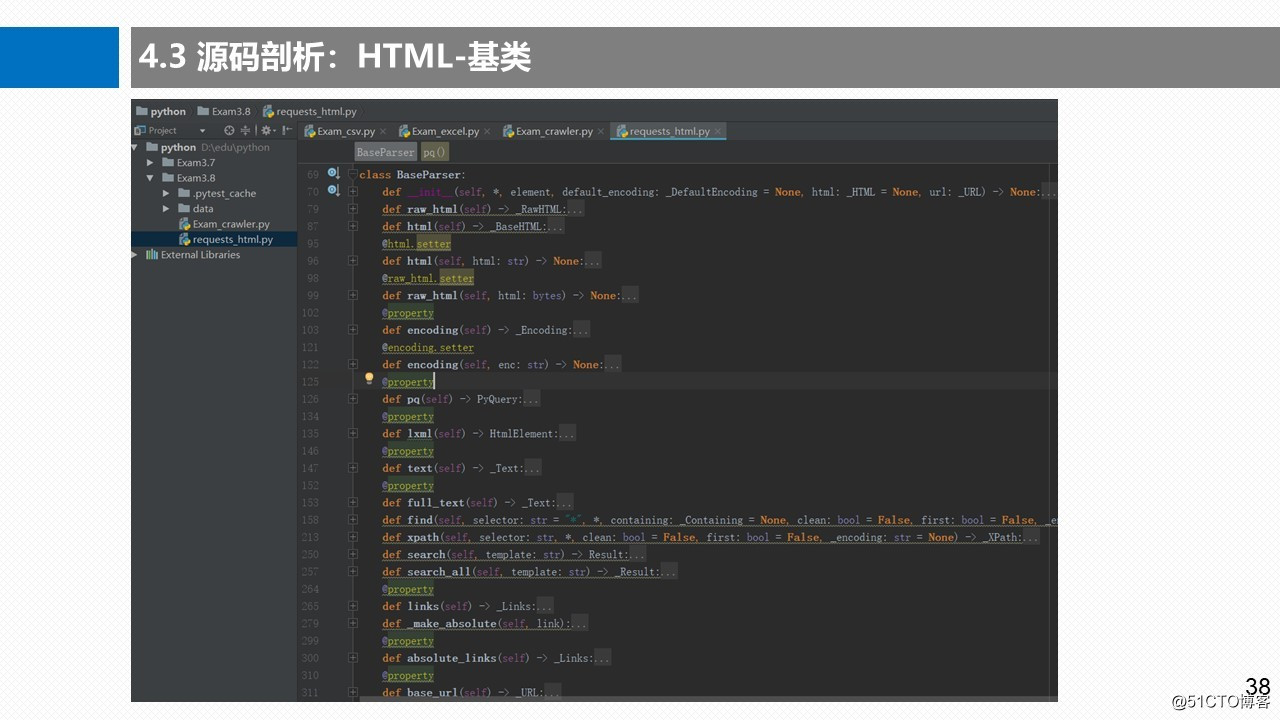
3.7 BaseParserHTML-基类
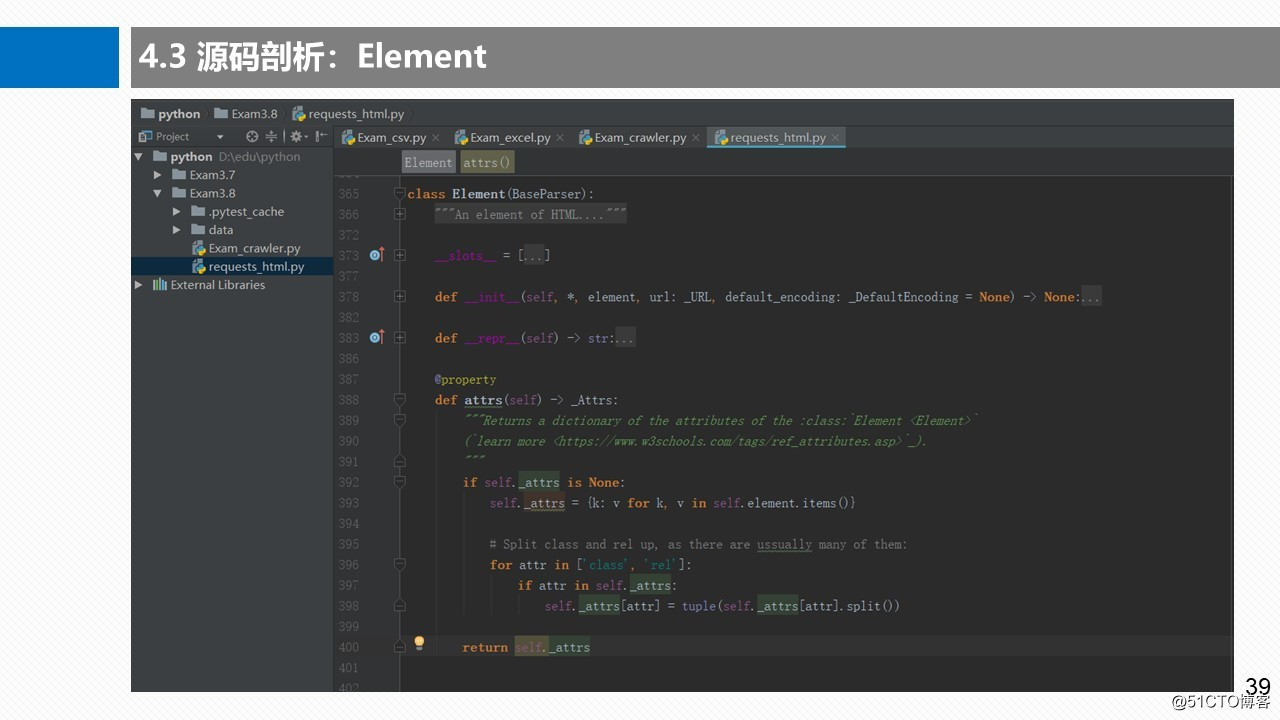
3.8 Element元素类
四、未完待续
《Python网络爬虫实战案例之:7000本电子书下载(1)》
《Python网络爬虫实战案例之:7000本电子书下载(2)》
《Python网络爬虫实战案例之:7000本电子书下载(3)》
《Python网络爬虫实战案例之:7000本电子书下载(4)》
上一篇:07-归并排序算法
下一篇:算法工程师笔/面试总结
文章标题:Python网络爬虫实战案例之:7000本电子书下载(4)
文章链接:http://soscw.com/index.php/essay/96810.html