基于C#的机器学习--机器学习的基本知识
2021-06-21 22:09
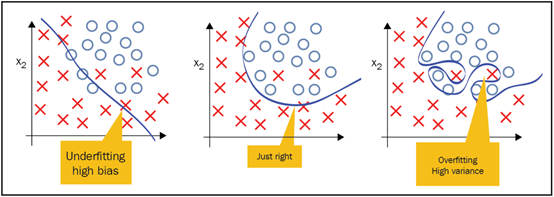
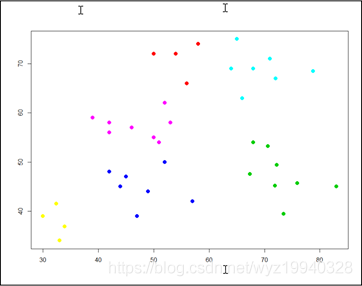
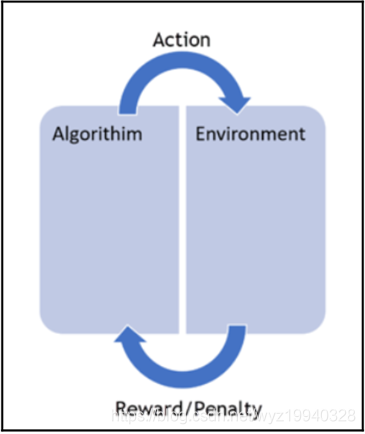
标签:基本 some 维度 put 最大的 编码 关于 name ast 作为一个终生的微软开发人员,我经常看到开发人员努力寻找解决日常问题所需的资源。让我们面对现实吧,我们没有人有时间按照自己喜欢的方式做事,我们中很少有人有幸在真正的研发部门工作。虽然这些年来我们已经走过了相当长的一段旅程,还记得曾经我们通过桌上的C程序员参考资料和其他50本书中翻找资料,到现在能够在谷歌中快速搜索并得到我们想要的东西。但现在人工智能时代已经到来,情况有些不同了。 作为c#开发人员,当涉及到机器学习时,谷歌搜索并不总是我们最好的朋友,因为几乎所有正在使用的东西都是Python, R, MATLAB和Octave。我们还必须记住,机器学习已经存在很多年了; 只是在最近,美国的企业已经接受了它,我们看到越来越多的人参与其中。 但是,我的朋友们,毫无疑问,这个世界是一个可怕的地方!c# .NET开发人员该何去何从? 让我们在下一节开始用一个小故事来回答这个问题,不幸的是,这个故事是千真万确的。 在本章中,我们将学习以下主题: 数据挖掘技术(即指从资料中发掘资讯或知识) 是购买、构建还是开源 强化学习 无监督学习 监督式学习 概率和统计 深度学习 人工智能(AI)和生物人工智能 我曾经有一个老板,我告诉他我正在使用机器学习来发现更多关于我们数据的信息。他的回答是:“你认为你能学到什么,我不知道!”。 如果你在职业生涯中还没有遇到这样的情况,那么恭喜你。如果你有任何职位空缺请告诉我!但你很可能会遇到或者已经遇到了。如果是你你会如何处理呢?而我并没有因此放弃这件事。 我:“我们的目标是了解更多关于我们所拥有的基金的信息和细节,以及它们如何与用户的实际情况进行关联的。” Boss:“但这些我都知道。机器学习只是一个时髦的词,它最终都是数据,我们都只是数据管理员。其余的都是流行语。我们为什么要这样做,它最终将如何帮助我。” 我:“我来问你。当你在谷歌中输入搜索时,你认为会发生什么?” Boss看起来有些愤怒。 Boss:“你想表达什么?Google当然是拿着我的输入的内容在网络中寻找与之相似的东西。” 我:“好,那这是怎么做的呢?” Boss看起来更愤怒以及有些沮丧。 Boss:“很显然它会先在网络中进行搜索,然后将我的输入和它的搜索结果进行比对。” 我:“但是你有没有想过这个搜索是如何在其他数十亿个搜索中匹配的,以及搜索背后的所有数据是如何不断更新的?很明显,人们不能参与其中,否则就无法扩大规模。” Boss:“当然,算法经过了很好的调整,给出了我们正在寻找的结果,或者至少给出了建议。” 我:“没错,正是机器学习做到了这一点。” (不一定,但足够接近!) Boss:“好吧,我不知道我还能从这些数据中学到什么所以让我们看看它是怎样的。” 所以,让我们做诚实的人。有时候,再多的逻辑也无法覆盖盲目或抗拒改变的心理,但这个故事的背后,有着与一个无视我们在生物学中所学到的一切的老板截然不同、更为重要的意义。在机器学习的世界里,要想向那些不像你一样每天都在开发战壕里的人证明/展示正在发生的事情、事情是否在工作、它们如何工作、它们为什么(或为什么不)工作,等等要难得多。即使那样,你也很难理解这个算法在做什么。 以下是你在决定机器学习是否适合你时应该问自己的一些问题: 你只是想顺应流行(这可能是真正需要的),还是真的需要这种类型的解决方案? 你有你需要的资料吗? 数据是否足够清晰以供使用(稍后将详细介绍)? 您知道在哪里以及是否可以获得可能丢失的数据吗?更重要的是,您如何知道数据实际上是丢失的? 你有很多数据还是只有少量数据? 有没有另一种已知且经过验证的解决方案,我们可以用它来代替? 你知道你想要完成什么吗? 你知道你将如何完成它吗? 你将如何向别人解释? 当被问到这个问题的时候,你如何能够证明在幕后发生了什么? 这些只是我们在开始机器学习之旅时将共同解决的许多问题中的一部分。 现在,如果有人能够执行一个返回多行数据的SQL查询,他们似乎将称自己为数据科学家。对于简历来说这足够公平;每个人偶尔都需要鼓励一下,即使是自己提供的。但他们真的是数据科学家吗?数据科学家到底是什么意思?我们真的在做机器学习吗?这到底意味着什么?好吧,到这本书的结尾,我们希望能找到所有这些问题的答案,或者至少,创造一个你可以自己找到答案的环境。 并不是所有人都能在奢华的研究或学术领域工作。我们许多人每天都火要救,正确的解决方案可能只是一个战术解决方案,必须在2小时内解决。这就是我们c#开发人员所做的。我们整天坐在桌子后面,运气好的话戴上耳机,不停地打字。但是我们真的能得到我们想要的或者需要的全部时间来按照我们想要的方式开发一个项目吗?如果我们这样做了,我们的项目中就不会有我们现在所拥有的那么多技术债务了,对吗(您确实跟踪了您的技术债务,对吗) ? 我们需要思考如何才能避免走弯路,有时我们通过思考而不是编码来做到这一点,尤其是在前期。知识是无价的,因为知识是无法被替代的。但在美国企业中,大多数生产代码都不是用Python、R、Matlab和Octave等学术语言编写的。即使所有的学术财富都是可以得到的,但它们并不是以最适合我们工作的形式得到的。 在此,让我们停下来,赞美那些为开源社区做出贡献的人。正因为有了它们,我们才有了一些优秀的第三方开源解决方案,我们可以利用它们来完成这项工作。开源社区允许我们利用他们所开发的东西,这本书的目的是让你了解其中的一些工具并展示如何使用它们。在这个过程中,我们会试着至少给你们一些你们应该知道的基本的背景知识,这样一切就不是黑洞对黑盒了! 你到处都能听到流行语。我以前每天上下班要花2-4个小时,我不记得我看到过多少广告牌上面写着机器学习或人工智能。它们无处不在,但这一切到底意味着什么? 人工智能,机器学习,数据科学,自然语言处理(NLP),数据挖掘,神经元。似乎只要美国公司参与进来,似乎一旦美国企业参与进来,这门曾经完美的艺术就变成了一场混乱的混战,一项完全不切实际的微观管理项目。我甚至听到一位潜在客户说,我不知道这意味着什么,但我就是不想被落在后面! 我们必须做的第一件事是学习处理机器学习项目的正确方法。让我们从一些定义开始: Tom Mitchell将机器学习定义为: "A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E." 我们的定义会有一点不同。希望当你被要求为你选择的道路辩护时,你可以使用它: "Machine learning is a collection of techniques which can be used to deal with large amounts of data in the most efficient and effective manner possible, which will derive actionable results and insight for us from that data." “机器学习是一组技术的集合,可以用来以最有效的方式处理大量数据,这将为我们从这些数据中获得可操作的结果和洞察力。” 现在,那些我们称之为技术的东西呢? 毫无疑问;诸如概率,统计等技术,它们都在那里,只是被隐藏起来了。我们将要用来执行示例的工具将隐藏细节,就像Python、R和其他工具一样!话虽这么说,如果我们没有至少让您了解一些基本知识,这将是对您的一种伤害,我们稍后将介绍这些基本知识。我并不是要降低它们的重要性因为它们都是同等重要的,但是我们的目标是让所有的c#开发人员尽可能快地启动和运行。我们将为您提供足够的信息,使您的buzzword符合规范,然后您将了解更多,而不仅仅是封装好的黑盒API调用! 我鼓励你们每个人在这个领域尽可能多地追求学术知识。机器学习和人工智能似乎每天都在变化,所以要时刻跟上最新的发展。你知道的越多,你的项目就越容易被接受。 既然我们提出了buzzword兼容的主题,让我们从一开始就清理一些术语。数据挖掘,机器学习,人工智能,等等。我现在只讲几个术语,但是这里有一个简单的方法。 你和家人在公路上旅行。让我们假设你有孩子,让我们把“我们还在吗”的对话放在一边! 你和你的一个孩子在高速公路上开车(一个很小的蹒跚学步的孩子),你的孩子指着窗外的一辆卡车大喊卡车。这个孩子还很小,所以他是怎么知道那辆车是卡车的(让我们假设它真的是卡车!)。他们知道这是一辆卡车,因为每次他们做同样的事情,你说“是”或“不是”。这是机器学习。然后,当你告诉他们是或不是,那就是强化学习。如果你说是的话,那是一辆大卡车,它会给强化过程增加背景,让我们沿着这条路深入学习。看看你教给你的孩子什么是甚至你都不知道的。 数据挖掘处理的是为非常具体的信息搜索大量的数据。您正在数据中搜索特定的内容。例如,信用卡公司将使用数据挖掘,通过分析购买行为和购买地点来了解购买者的习惯。这些信息对诸如目标广告之类的东西非常有用。 另一方面,机器学习侧重于使用您提供的算法搜索数据的实际任务。有道理吗? 这里有一个很好的链接,您可以在这里学习更多关于数据挖掘的知识: https:/?/?blog.?udacity.?com/?2014/?12/?24-?data-?science-?resources-?keep-?fingerpulse.?html 人工智能是机器学习的一个更高层次。有些人把它定义为机器看起来和人类一样聪明或比人类聪明。对我来说,这个问题还没有定论。我每天看的新闻越多,我就越想知道到底哪种智能是人工的,就这一点而言,什么才是真正的智能!关于人工智能的定义有很多,但简而言之,人工智能被认为是一种机器,它所做的事情是人类能够或应该做的,以至于任何理性的人都无法在反应上区分机器和人类。无论如何,人工智能是一个影响深远的主题,不幸的是,它的含义和人们使用这个术语的含义一样多。 生物-AI指的是将一个生物组件与一个计算组件放在一起。基因型,表现型,神经元,镜像神经元,典型神经元,突触…你会听到在这个类别下所有提到的,人工神经网络(ANNs)!生物人工智能主要应用于医学领域。现在,我们不需要关心这个问题,只需要知道这个术语的存在,以及生物学是它的构成的基础。 多年来,人们认为神经网络(使用一种称为隐藏层的概念)只需要一个隐藏层就可以解决任何问题。随着计算能力的提高,计算硬件成本的降低,以及神经网络算法的进步,在您的网络中有数百甚至数千个隐藏层是很常见的。隐藏层的数量的增加,以及其他一些东西,简单来说就是什么是深度学习!这里有一个直观的比较,可能有助于让事情变得更清楚: 如下图所示,网络中有几个隐藏的层 信不信由你,这就是你正在做的;它是从你的观点中很好地抽象出来的。但是让我给你一个难以置信的,过度简化的,快速入门…以防你被绕晕了。 你看见一只北极熊在雪地里走。你想知道它会留下什么样的脚印。这是概率。接下来,你看到雪地上的脚印,想知道这是不是北极熊。这是统计数据。再举一个例子以防万一: 接下来,让我们谈谈我们将如何处理我们的机器学习项目,在此过程中,继续定义/改进我们的机器学习心态。让我们从定义每次处理这些项目时需要使用的基本步骤开始。基本上,我们可以把它们分成以下几类。 有无数类型的数据可供您使用,从SQL和NoSQL数据库、Excel文件、Access数据库、文本文件等等。您需要决定数据位于何处、如何格式化数据、如何导入和细化数据。您需要始终记住,大量的测试和培训数据以及它们的质量是无法替代的。在机器学习中,无用输入和无用输出会变得非常混乱 如前所述,数据质量是无可替代的。是否有丢失、畸形或不正确的数据?我们不要忘记另一个你们可能熟悉的术语,数据离群值。这些讨厌的小数据片段根本不适合您的其他数据!你有吗?如果是,他们应该在那里吗?如果是,他们将如何处理?如果您不确定,下面是在绘制数据时数据离群值的样子: 在统计学中,离群值是一个观测点,它与其他观测点之间的距离很远,有时非常远,有时不太远。异常值本身可能是由于测量的可变性导致的,这表明了实验存在缺陷,或者它实际上可能是有效的。如果您在数据中看到异常值,您需要了解原因。它们可以指示某种形式的测量误差,而您使用的算法可能不够健壮,无法处理这些异常值。 在创建和训练模型时,需要考虑以下几点。 一旦您使用了您的训练数据,您将继续使用您之前准备的测试数据集来测试/评估您的模型。在这里,我们可以发现我们的模型是如何根据它以前没有看到的数据工作的。如果我们的模型在这里失败了,我们将返回到开始的地方,并改进我们的流程。 当您在评估您的模型时,您可能在某个时候决定您需要选择一个不同的模型,或者引入更多的特性/变量/超参数来提高模型的效率和性能。减少暴露的一个好方法是在数据收集部分和数据准备部分花费额外的时间。正如我们前面所说,大量正确的数据是无可替代的。 鸢尾花数据集是生物学家Ronald Fisher先生于1936年介绍的花卉数据集。此数据集包含了3种鸢尾花(鸢尾花,鸢尾花,鸢尾花色)各50个样本。每个样本包括四个特征(萼片的长度,花瓣的长度,萼片的宽度,花瓣的宽度)。结合这些数据,就可以得到一个线性判别模型来区分不同的物种。 那么,我们如何从花到数据: 我们现在需要把我们所知道的花的视觉表现形式转化成计算机可以理解的东西。我们将花的所有信息分解为列(特征)和行(数据项),如下所示: 既然所有的测量数据都是计算机能够理解的格式,我们的第一步应该是确保我们没有丢失或畸形的数据,因为这会带来麻烦。如果您查看前面屏幕截图中的黄色高亮部分,您可以看到我们丢失了一些数据。我们需要确保在将其提交给应用程序之前填充了它。一旦正确地准备和验证了数据,我们就可以开始了。如果我们从Encog34运行Iris验证器,我们的输出应该反映出我们有150个数据集,它确实有: 现在,让我们简要地熟悉一下我们将在整本书中讨论的不同类型的机器学习,重要的是你至少要熟悉这些术语,因为它们总有一天会出现,你知道的和理解的越多,你就能更好地处理你的问题并向别人解释它。 下面是一个简单的图表,展示了机器学习的三个主要类别: 这些类型的机器学习模型被用来根据提供给它的数据预测结果。所提供的说明是明确和详细的,或者至少应该是明确和详细的,这是获得所监督的标签的原因。我们基本上是在学习一个基于输入和输出对将输入映射到输出的函数。这个函数是从被称为标记的训练数据中推断出来的,因为它明确地告诉这个函数它期望什么。在监督学习中,总是有一个输入和相应的输出(或者更准确地说,是一个期望的输出值)。更正式地说,这类算法使用一种称为归纳偏差的技术来实现这一点,这基本上意味着算法将使用一组假设来预测给定输入的输出,这些输入可能是它以前见过的,也可能不是。 在监督学习中,我们通常可以访问一组X特征(X1, X2, X3,…)Xx),用观测值来测量,响应Y,也用同样的n个观测值来测量。然后我们试着用X1,X2, X3…Xn来预测Y。 支持向量机(SVM)、线性回归、朴素贝叶斯和基于树的方法等模型只是监督学习的几个范例。 接下来,让我们简要讨论一下在有监督学习中我们需要关注的一些事情。它们没有特定的顺序。 偏差及方差的权衡 在讨论偏差-方差权衡之前,我们首先要确保您熟悉各个术语本身。 当我们讨论偏差-方差权衡时,偏差指的是学习算法中由于不正确的假设而产生的错误。高偏差会导致所谓的欠拟合现象,这种现象会导致算法遗漏数据中相关的特征-输出层关系 另一方面,方差是对训练集中的小波动的敏感误差。高方差会导致算法模拟随机噪声,而不是实际的预期输出,这种现象称为过拟合。 每个机器学习开发人员都需要理解偏差和方差之间的平衡。它与数据的过拟合和过拟合有直接关系。我们说,如果一个学习算法在不同的训练集中预测不同的输出结果,那么它对输入的方差很大,这当然不好。 低偏差的机器学习算法必须足够灵活,才能很好地适应数据。但是,如果算法设计过于灵活,每个训练和测试数据集的拟合就会不一样,导致方差很大。 然而您的算法又必须足够灵活,那么你可以通过固有的算法知识或可由用户调整的参数来调整这种权衡。 下图显示了一个具有高偏差(左侧)的简单模型和一个具有高方差(右侧)的更复杂模型。 训练的数据量 正如我们反复说过的,没有什么可以替代足够的数据来正确和完整地完成这项工作。这与学习算法的复杂性直接相关。一个低偏差、低方差的简单算法可以从更少的数据中获得更好的学习效果。然而,如果您的学习算法很复杂(许多输入特性、参数等),那么您将需要一个更大的训练集,在低偏差和高方差的情况下进行学习。 输入空间维数 对于每一个学习问题我们的输入都是向量的形式。特征向量,即数据本身的特征,这对算法的影响很大。如果输入的特征向量非常大,也就是所谓的高维性,那么即使只需要其中的几个特征,学习起来也会更加困难。有时,额外的维度会混淆您的学习算法,从而导致高方差。反过来,这意味着您必须优化算法,使其具有更低的方差和更高的偏差。如果适用的话,从数据中删除额外的特性有时会更容易提高学习方法的准确性。 也就是说,一些机器学习算法使用了一种称为降维的流行技术。这些算法将识别和删除不相关的特征。 不正确的输出值 我们在这里需要问自己的是,机器学习算法的期望输出中存在多少错误。学习算法可能会试图将数据拟合得太好,从而导致我们前面提到的过拟合。过度拟合可能是由于不正确的数据,或学习算法过于复杂,无法完成手头的任务。如果出现这种情况,我们需要调整算法,或者寻找一个偏差更大、方差更小的算法。 数据的多样性 数据的多样性意味着特征向量包含许多不同种类的特征。如果这适用于我们的应用程序,那么我们最好为任务应用不同的学习算法。一些学习算法还要求我们的数据被缩放以适应特定的范围,如[0 -1]、[-1 -1]等。当我们学习以距离函数为基础的算法时,比如最近邻居法和支持向量法,你会发现它们对这个非常敏感。另一方面,基于树的算法(决策树等)可以很好地处理这种现象。 我们应该始终从最简单、最合适的算法开始,并确保正确地收集和准备我们的数据。从这里开始,我们可以尝试不同的学习算法,并对它们进行优化,看看哪种算法最适合我们的情况。毫无疑问,优化算法可能不是一项简单的任务,并且最终会消耗比我们可用的时间多得多的时间。总是首先确保有适当数量的数据可用 与监督学习相反,在如何确定结果方面,非监督学习通常有更多的灵活性。对于算法来说,数据的处理使得数据集中没有任何一个特征比其他特征更重要。这些算法从输入数据的数据集学习,而不需要标记期望的输出数据。k均值聚类(聚类分析)是无监督模型的一个例子。它非常善于在数据中找到与输入数据相关的有意义的模式。我们在监督部分所学到的和这里的最大区别是我们现在有了x的特征X1 X2 X3,…用n个观测值测量。但我们不再对Y的预测感兴趣,因为我们不再有Y了,我们唯一感兴趣的是在已有的特征上发现数据模式: 在前面的图中,我们可以看到这样的数据本身更适合于非线性方法,在这种方法中,数据似乎是按重要性分组的。它是非线性的,因为我们无法得到一条直线来准确地分离和分类数据。无监督学习允许我们在几乎不知道结果会是什么或应该是什么的情况下解决问题。结构来自于数据本身,而不是应用于输出标签的监督规则。这种结构通常由数据的聚类关系导出。 例如,假设我们有许多个基因来自我们的基因组数据科学实验。我们希望将这些数据分组为类似的片段,如头发颜色、寿命、体重等等。 第二个例子是众所周知的酒会效应,它基本上指的是大脑能够将注意力集中到一件事上,并过滤掉周围的噪音。 这两个示例都可以使用集群来实现它们的目标。 强化学习是一种机器被训练为一个特定的结果,唯一的目的是最大化的效率和/或性能。该算法因做出正确的决策而得到奖励,因做出错误的决策而受到惩罚。持续的训练是为了不断提高绩效。持续的学习过程意味着更少的人为干预。马尔可夫模型是强化学习的一个例子,自动驾驶汽车就是这样一个应用的很好的例子。它不断地与环境进行交互,监视障碍物、速度限制、距离、行人等等,以便(希望如此)做出正确的决策。 我们与强化学习最大的不同是我们没有处理正确的输入和输出数据。这里的重点是性能,这意味着需要在看不见的数据和算法已经学过的东西之间找到一种平衡。 算法将一个动作应用到它的环境中,根据它所做的、重复的等行为接受奖励或惩罚,如下图所示。你可以想象一下每秒有多少次这种情况发生在刚刚在酒店接你的自动驾驶出租车上。 接下来,让我们问自己一个非常重要的问题。我们是需要购买、构建还是使用开源? 接触开源世界,这是我的建议,当然也是我写这本书的原因之一。我意识到许多开发人员都有“它不是在这里构建的”综合症,但是在走上这条道路之前,我们应该对自己诚实。我们真的认为我们有能力做得更好、更快、在我们的时间限制内进行测试吗?我们应该先试着看看已经有什么可以使用。有很多很棒的开源工具包可供我们使用,这些工具包的开发人员已经投入了大量的时间和精力来开发和测试它们。显然,开源并不是每个人、每次都可以使用的解决方案,但是即使您不能在应用程序中使用它,也可以通过使用和试验它们获得大量的知识。 购买通常不是一个最佳选择。如果你足够幸运地找到要买的东西,但你可能不会得到批准,因为它将花费一大笔钱!如果你需要修改产品来做你需要的事情,会发生什么?祝您好运,能够访问源代码或者让支持团队为您更改他们的优先级。这中情况几乎不会发生,至少不会像我们需要的那么快。 至于自己构建,嘿,我们是开发者,这是我们都想做的,对吧?但是在您启动Visual Studio之前,请仔细地考虑一下您将要进入的环境。 所以开源应该永远是第一选择。您可以将其引入内部(假设许可允许您这样做),在需要时根据您的标准对其进行调整(代码联系、更多的单元测试、更好的文档,等等)。 在这一章中,我们讨论了机器学习的许多方面,以及实现您的代码的不同策略,如构建、购买或开源,并简单介绍了一些重要的定义。我希望这能让你们为接下来的章节做好准备。 转载请注明出处:https://www.cnblogs.com/wangzhenyao1994/p/10223720.html 文章发表的另一个地址:https://blog.csdn.net/wyz19940328/article/details/85835239 基于C#的机器学习--机器学习的基本知识 标签:基本 some 维度 put 最大的 编码 关于 name ast 原文地址:https://www.cnblogs.com/wangzhenyao1994/p/10223720.html机器学习的基本知识
机器学习概论
数据挖掘
人工智能
生物-AI
深度学习
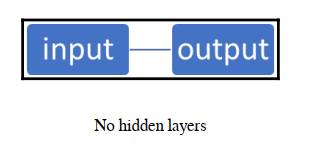
?
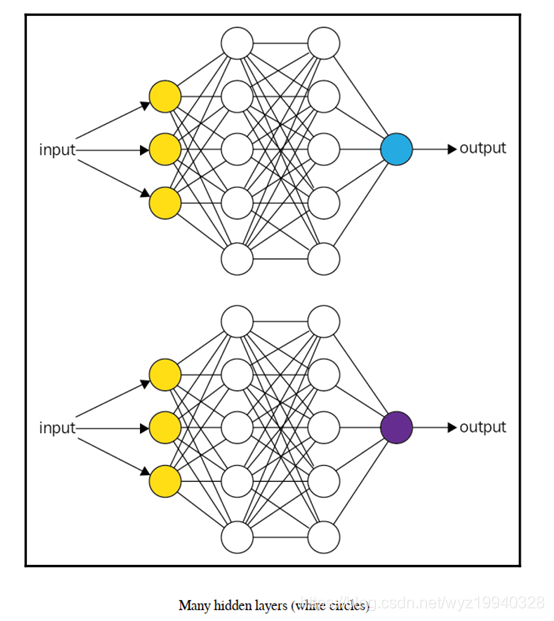
?
概率与统计
开始你的机器学习项目
数据收集
数据准备
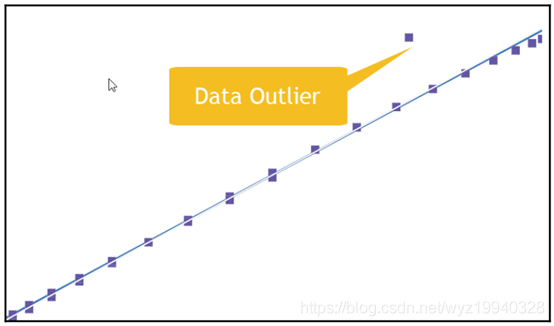
?
选择与训练模型
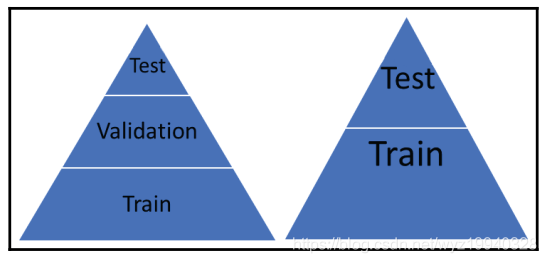
?
评估模型
调教模型
鸢尾花数据集
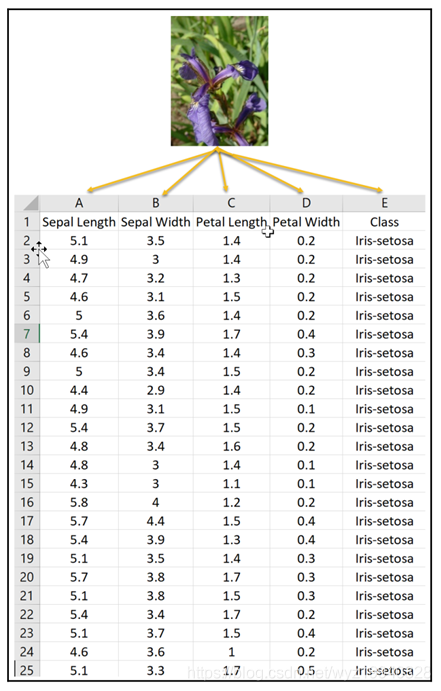
?
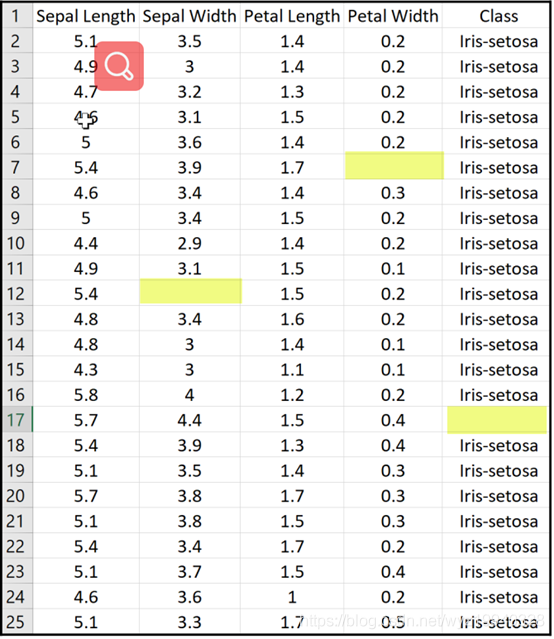
?
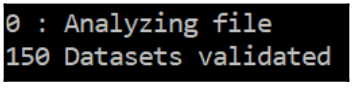
?
机器学习中的分类
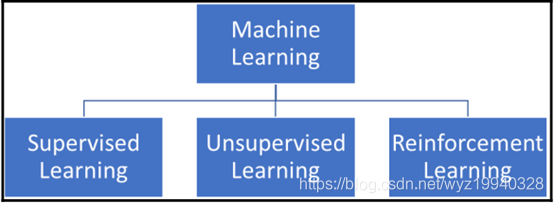
?
监督式学习
?
无监督式学习
?
强化学习
?
构建、购买或开源
总结
文章标题:基于C#的机器学习--机器学习的基本知识
文章链接:http://soscw.com/index.php/essay/97099.html