第十八节、图像描述符匹配算法
2021-06-27 23:06
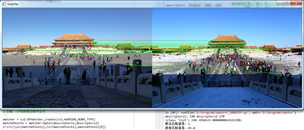
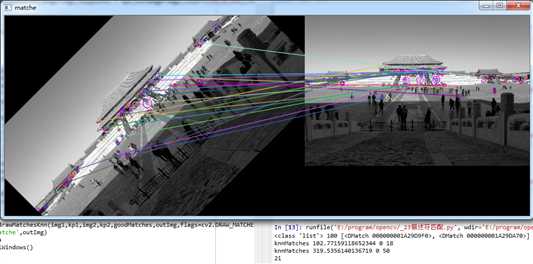
标签:函数 lang libary net lam eric query decided lan 在前面的一些小节中,我们已经使用到的图像描述符匹配相关的函数,在OpenCV中主要提供了暴力匹配、以及FLANN匹配函数库。 暴力匹配即两两匹配。该算法不涉及优化,假设从图片A中提取了$m$个特征描述符,从B图片提取了$n$个特征描述符。对于A中$m$个特征描述符的任意一个都需要和B中的$n$个特征描述符进行比较。每次比较都会给出一个距离值,然后将得到的距离进行排序,取距离最近的一个作为匹配点。这种方法简单粗暴,其结果也是显而易见的,通过前几节的演示案例,我们知道有大量的错误匹配,这就需要使用一些机制来过滤掉错误的匹配。比如我们对匹配点按照距离来排序,并指定一个距离阈值,过滤掉一些匹配距离较远的点。 OpenCV专门提供了一个BFMatcher对象来实现匹配,并且针对匹配误差做了一些优化: 参数说明: BFMatcher对象有两个方法BFMatcher.match()和BFMatcher.knnMatch()。 注意:$k$近邻匹配,在匹配的时候选择$k$个和特征点最相似的点,如果这$k$个点之间的区别足够大,则选择最相似的那个点作为匹配点,通常选择$k = 2$,也就是最近邻匹配。对每个匹配返回两个最近邻的匹配,如果第一匹配和第二匹配距离比率足够大(向量距离足够远),则认为这是一个正确的匹配,比率的阈值通常在2左右。 具体可以参考C++版本程序,博客SLAM入门之视觉里程计(1):特征点的匹配,python程序如下: 运行结果如下: 在程序中我们指定获取100个特征点,并且指定knn的参数k=2,也就是说A图中的一个特征描述符会在B图中找到两个对应的特征描述符,一个是最佳匹配,距离最小,另一次次之,我们在程序中输出了一组匹配结果: 可以看到dMatch0和dMatch1是DMatch类型,这个类型主要包括以下几个属性: 然后我们遍历每一组匹配结果,我们设置最小比率为$\frac{1}{3}$,过滤掉匹配距离较为相近的。最后只剩下21组,匹配效果如上图所示。我们可以误匹配明显少了很多,基本看不到误匹配点。(实际上,比率设置为0.7,大概就可以过滤掉90%的误匹配点) FLANN英文全称Fast Libary for Approximate Nearest Neighbors,FLANN是一个执行最近邻搜索的库,官方网站http://www.cs.ubc.ca/research/flann。它包含一组算法,这些算法针对大型数据集中的快速最近邻搜索和高维特征进行了优化,对于大型数据集,它比BFMatcher工作得更快。经验证、FLANN比其他的最近邻搜索软件快10倍。 在GitHub上可以找到FLANN,网址为https://github.com/mariusmuja/flann。根据作者的经验,基于FLANN的匹配非常准确、快速、使用起来也很方便。 其中FLANN匹配对象接收两个参数:indexParams和searchParams。这两个参数在python中以字典形式进行参数传递(在C++中以结构体形式进行参数传递),为了计算匹配,FALNN内部会决定如何处理索引和搜索对象。 1、indexParams 对于像SIFT,SURF等算法,您可以传递以下内容: 使用ORB时,您可以传递以下内容: 参数algorithm用来指定匹配所使用的算法,可以选择的有LinearIndex、KTreeIndex、KMeansIndex、CompositeIndex和AutotuneIndex,这里选择的是KTreeIndex(使用kd树实现最近邻搜索)。KTreeIndex配置索引很简单(只需要指定待处理核密度树的数量,最理想的数量在1~16之间),并且KTreeIndex非常灵活(kd-trees可被并行处理)。 2、searchParams SearchParams它指定索引数倍遍历的次数。 值越高,精度越高,但也需要更多时间。 如果要更改该值,请传递: 实际上、匹配效果很大程度上取决于输入。5 kd-trees和50 checks总能取得具有合理精度的结果,而且能够在很短的时间内完成匹配。 程序中我们通过matchesMask来设置绘制时需要显示的匹配线,对于A图中的一个特征描述符$a1$,对应在B图中两个特征描述符$b1,b2$,Mask有4中设置结果: 上面我们已经介绍到,使用queryImage,在其中找到了一些特征点,我们采用了另一个trainingImage,找到了该图像中的特征,我们发现它们之间的最佳匹配。简而言之,我们在另一个杂乱的图像中找到了对象的某些部分的位置。此信息足以在trainingImage上准确找到对象。 第十八节、图像描述符匹配算法 标签:函数 lang libary net lam eric query decided lan 原文地址:https://www.cnblogs.com/zyly/p/9646201.html一 暴力匹配以及优化(交叉匹配、KNN匹配)
cv2.BFMatcher_create([,normType[,crossCheck]])
# -*- coding: utf-8 -*-
"""
Created on Fri Sep 14 14:02:44 2018
@author: zy
"""
‘‘‘
特征描述符匹配算法 暴力匹配,KNN匹配,FLANN匹配
‘‘‘
import cv2
import numpy as np
def match_test():
‘‘‘
暴力匹配 KNN最近邻匹配
‘‘‘
img1 = cv2.imread(‘./image/orb1.jpg‘,0)
img2 = cv2.imread(‘./image/orb2.jpg‘,0)
img2 = cv2.resize(img2,dsize=(450,300))
‘‘‘
1.使用SIFT算法检测特征点、描述符
‘‘‘
sift = cv2.xfeatures2d.SIFT_create(100)
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
#在图像上绘制关键点
img1 = cv2.drawKeypoints(image=img1,keypoints = kp1,outImage=img1,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
img2 = cv2.drawKeypoints(image=img2,keypoints = kp2,outImage=img2,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
#显示图像
#cv2.imshow(‘sift_keypoints1‘,img1)
#cv2.imshow(‘sift_keypoints2‘,img2)
cv2.waitKey(20)
‘‘‘
2、匹配
‘‘‘
bf = cv2.BFMatcher()
knnMatches = bf.knnMatch(des1,des2, k=2)
print(type(knnMatches),len(knnMatches),knnMatches[0])
#获取img1中的第一个描述符在img2中最匹配的一个描述符 距离最小
dMatch0 = knnMatches[0][0]
#获取img1中的第一个描述符在img2中次匹配的一个描述符 距离次之
dMatch1 = knnMatches[0][1]
print(‘knnMatches‘,dMatch0.distance,dMatch0.queryIdx,dMatch0.trainIdx)
print(‘knnMatches‘,dMatch1.distance,dMatch1.queryIdx,dMatch1.trainIdx)
#将不满足的最近邻的匹配之间距离比率大于设定的阈值匹配剔除。
goodMatches = []
minRatio = 1/3
for m,n in knnMatches:
if m.distance / n.distance minRatio:
goodMatches.append([m])
print(len(goodMatches))
sorted(goodMatches,key=lambda x:x[0].distance)
#绘制最优匹配点
outImg = None
outImg = cv2.drawMatchesKnn(img1,kp1,img2,kp2,goodMatches,outImg,flags=cv2.DRAW_MATCHES_FLAGS_DEFAULT)
cv2.imshow(‘matche‘,outImg)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == ‘__main__‘:
match_test()
bf = cv2.BFMatcher()
knnMatches = bf.knnMatch(des1,des2, k=2)
print(type(knnMatches),len(knnMatches),knnMatches[0])
#获取img1中的第一个描述符在img2中最匹配的一个描述符 距离最小
dMatch0 = knnMatches[0][0]
#获取img1中的第一个描述符在img2中次匹配的一个描述符 距离次之
dMatch1 = knnMatches[0][1]
print(‘knnMatches‘,dMatch0.distance,dMatch0.queryIdx,dMatch0.trainIdx)
print(‘knnMatches‘,dMatch1.distance,dMatch1.queryIdx,dMatch1.trainIdx)
DMatch.distance - Distance between descriptors. The lower, the better it is.DMatch.trainIdx - Index of the descriptor in train descriptors;训练描述符就是我们程序中的img2的描述符;DMatch.queryIdx - Index of the descriptor in query descriptors;测试描述符就是我们程序中的img1的描述符;DMatch.imgIdx - Index of the train image.二 FLANN匹配
# -*- coding: utf-8 -*-
"""
Created on Fri Sep 14 14:02:44 2018
@author: zy
"""
‘‘‘
特征描述符匹配算法 暴力匹配,KNN匹配,FLANN匹配
‘‘‘
import cv2
import numpy as np
def flann_test():
‘‘‘
FLANN匹配
‘‘‘
#加载图片 灰色
img1 = cv2.imread(‘./image/orb1.jpg‘)
gray1 = cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY)
img2 = cv2.imread(‘./image/orb2.jpg‘)
img2 = cv2.resize(img2,dsize=(450,300))
gray2 = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY)
queryImage = gray1.copy()
trainingImage = gray2.copy()
#创建SIFT对象
sift = cv2.xfeatures2d.SIFT_create(100)
#SIFT对象会使用DoG检测关键点,并且对每个关键点周围的区域计算特征向量。该函数返回关键点的信息和描述符
keypoints1,descriptor1 = sift.detectAndCompute(queryImage,None)
keypoints2,descriptor2 = sift.detectAndCompute(trainingImage,None)
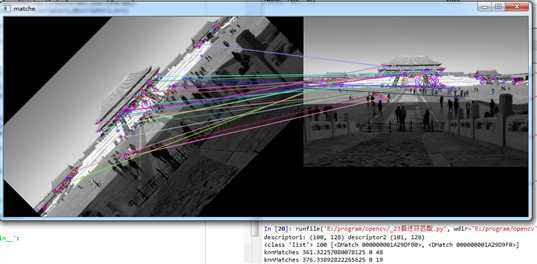
print(‘descriptor1:‘,descriptor1.shape,‘descriptor2‘,descriptor2.shape)
#在图像上绘制关键点
queryImage = cv2.drawKeypoints(image=queryImage,keypoints = keypoints1,outImage=queryImage,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
trainingImage = cv2.drawKeypoints(image=trainingImage,keypoints = keypoints2,outImage=trainingImage,color=(255,0,255),flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
#显示图像
#cv2.imshow(‘sift_keypoints1‘,queryImage)
#cv2.imshow(‘sift_keypoints2‘,trainingImage)
#cv2.waitKey(20)
#FLANN匹配
FLANN_INDEX_KDTREE = 0
indexParams = dict(algorithm = FLANN_INDEX_KDTREE,trees = 5)
searchParams = dict(checks = 50)
flann = cv2.FlannBasedMatcher(indexParams,searchParams)
matches = flann.knnMatch(descriptor1,descriptor2,k=2)
print(type(matches),len(matches),matches[0])
#获取queryImage中的第一个描述符在trainingImage中最匹配的一个描述符 距离最小
dMatch0 = matches[0][0]
#获取queryImage中的第一个描述符在trainingImage中次匹配的一个描述符 距离次之
dMatch1 = matches[0][1]
print(‘knnMatches‘,dMatch0.distance,dMatch0.queryIdx,dMatch0.trainIdx)
print(‘knnMatches‘,dMatch1.distance,dMatch1.queryIdx,dMatch1.trainIdx)
#设置mask,过滤匹配点 作用和上面那个一样
matchesMask = [[0,0] for i in range(len(matches))]
minRatio = 1/3
for i,(m,n) in enumerate(matches):
if m.distance/n.distance minRatio:
matchesMask[i] = [1,0] #只绘制最优匹配点
drawParams = dict(#singlePointColor=(255,0,0),matchColor=(0,255,0),
matchesMask = matchesMask,
flags = 0)
resultImage = cv2.drawMatchesKnn(queryImage,keypoints1,trainingImage,keypoints2,matches,
None,**drawParams)
cv2.imshow(‘matche‘,resultImage)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == ‘__main__‘:
flann_test()
flann = cv2.FlannBasedMatcher(indexParams,searchParams)
indexParams = dict(algorithm = FLANN_INDEX_KDTREE,trees = 5)
indexParams= dict(algorithm = FLANN_INDEX_LSH,
table_number = 6, # 12
key_size = 12, # 20
multi_probe_level = 1) #2
searchParams = dict(checks = 50)
三 FLANN的单应性匹配
为此,我们可以使用来自calib3d模块的函数,即cv2.findHomography()。如果我们从两个图像中传递一组点,它将找到该对象的相应变换。然后我们可以使用cv2.perspectiveTransform()来查找对象。它需要至少四个正确的点来找到转换。
我们已经看到匹配时可能存在一些可能的错误,这可能会影响结果。为了解决这个问题,算法使用RANSAC或LEAST_MEDIAN(可以由标志决定)。因此,提供正确估计的良好匹配称为内点,剩余称为异常值。 cv2.findHomography()返回一个指定内部和异常点的掩码。参考文章:
[1]SLAM入门之视觉里程计(1):特征点的匹配
[2]近似最近邻搜索方法FLANN简介
[3]OpenCV-Python Tutorials Feature Detection and Description
[4]Feature Matching + Homography to find Objects