WC项目——python实现
2021-06-28 08:05
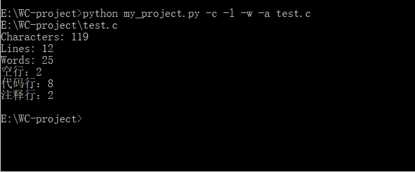
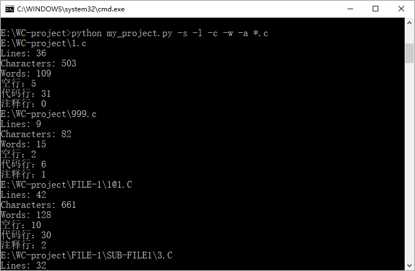
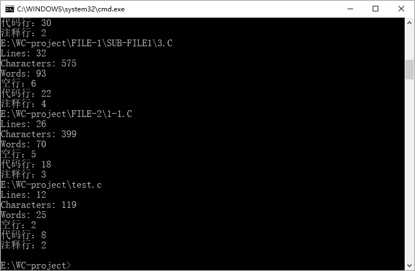
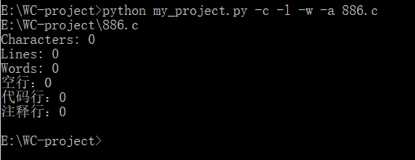
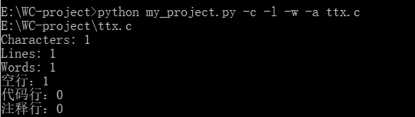
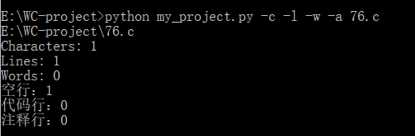
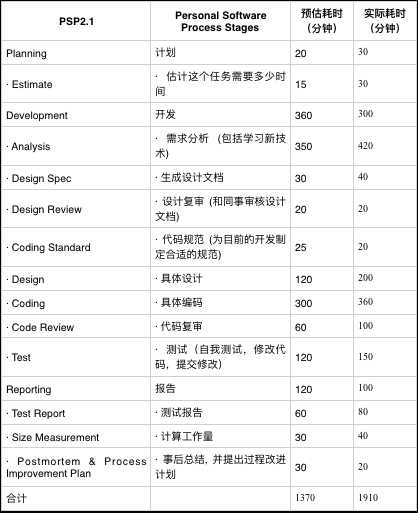
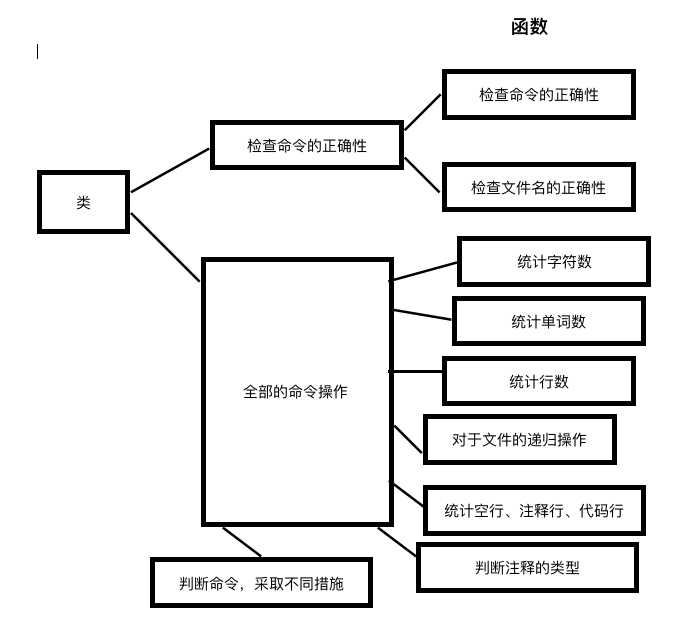
标签:改变 含义 image 若是 利用 放弃 测试结果 特殊情况 complex GitHub地址:https://github.com/Amy-CC/SCHOOL.git 项目要求: 实现一个统计程序,它能正确统计程序文件中的字符数、单词数、行数,以及还具备其他扩展功能,并能够快速地处理多个文件。 PSP表格: 解题思路: 看到题目时,我先想到的是实现基础功能。首先考虑的是考虑用sys模块输入,使其能在命令行中输入。然后考虑文件的打开问题,我使用的是py文件所在的文件夹。-c功能考虑了所有的字符,-w功能先使用正则表达式去掉不是字母和空格的字符,然后通过空格分割来计数。-l则很简单,使用len()函数就可以解决。 -w开始的时候想着用os.path模块、os.walk函数,但是发现在这种情况下,我仍然需要对文件列表进行进一步的循环操作,所以放弃了os.walk函数,而是采用递归的方法。 -a我只考虑了c文件,因为c文件无法跟python的源文件同时判断,由于注释#的问题,在c语言中有含义,无法同时读取。首先设置for循环,第一次判断空行的情况,因为标准是少于或等于一个字符,我先把前后的空格去掉,就能判断只有一个字符。第二次判断注释,用另一个函数,用正则判断。第三次判断直接通过len()判断代码行,避免前面两行的影响。 在设计的过程中,我也查找了百度关于python的os库,如何实现命令的输入,文件的读取,还有对于文件目录的函数。我查看了关于python的书籍还有正则表达式的书籍。对于单元测试还是没有完整覆盖,所以最后采用的手动测试的方式。 设计实现过程: 因为首先做好的设计是关于基础功能的,所以在后面实现扩展功能时,发现有着架构的问题,所以在后来需要把读取文件的架构做一些修改:添加一个文件路径列表,在读取文件的时候直接使用readlines()函数,避免在计数的过程中出现文件变量被清空的情况。 在刚开始实现的时候,发现对于命令和文件名的判断函数出现了问题,因为对于正则表达式的不熟悉,所以经过几次的修改才能通过。 在考虑基础功能时,开始写的函数是每个命令每次都重读一次文件,但是这太过于麻烦,需要多个for循环会提高复杂度,所以采用了一次读取,多次使用的readlines()函数。而且readlines()函数会带来问题,就是每个字符串都会出现一个换行符,所以我后来使用了rstrip()来去掉。 扩展功能-s刚开始出现了不知道怎么判断输入的文件后缀名,后来通过分割再拼接的方式,实现读取后缀名。而且因为后缀名有大小写的问题,所以后面加了upper()函数。 扩展功能-a实现的时候因为re模块函数不熟悉,在注释的判断上用了match()函数,发现由于match只针对开头判断,所以后面改变为search函数。 程序结构: 第一个类检查输入的正确性,第二个命令是各种操作的代码。由判断menu()函数来实现对其他操作函数的调用。 代码说明: 一、第一个类:检查正确性 1、判断文件名的正确性 2、判断命令名字的正确性 二、第二个类:各个操作 1、统计字符数 输入是readlines后的列表,只需统计除了最后换行符的字符串长度 2、统计单词数 先去掉最后换行符,再通过去掉非空格、非字母的字符,利用空格分割,统计非空字符串,即为单词数。 3、统计行数 直接返回readlines()后的个数 4、递归文件 通过分割拼接,得到完整路径,如果符合后缀名,则放入列表;如果为文件夹则递归寻找。 5、统计空行、代码行、注释行 先判断空行,去掉前后的空格等字符,则为显示字符。 注释行需另外函数来统计,因为需要标记/*的特殊情况。 代码行则多于1个代码并且不是注释行。 6、菜单(调用操作、打开文件) 先遍历文件列表,打开文件,再遍历命令列表。 三、相当于main函数的主体 先判断文件列表是否为空,选择是否进入递归文件函数。 还要查询递归后,是否有此类文件,有才执行菜单操作,否则退出。 测试结果: 各种命令的测试(正常源文件): 目标文件: 若是命令不符合: 若是文件名不符合: -w操作的实现 目标目录: 空白文档: 单个字符文档(字母): 单个字符文档(非字母,而是控制字符): 项目总结: 1、因为是第一次使用python开发一个项目,所以很多东西都需要查询资料,例如各种的模块,由于各种模块运用的还不是很熟练,而导致了一些混淆的现象,例如re模块的match和search函数。 2、而且在过程中遇到了很多的困难,只有靠不断的测试,查百度才了解了自己的错误原因,进行一遍遍的修正。了解到了查询资料、测试的重要性。 3、尽管实现了基础功能和扩展功能,项目的时间复杂度还是比较高的,还需要进一步的优化。 4、学会了使用GitHub来控制自己的版本操作,尽管上传失败了很多次,在一次次的摸索中终于上传成功了。 5、明白了开始的规划其实很重要,由于我之前规划的不好,导致后来增加功能需要重新架构,浪费了很多的时间。 6、之前没有学会写一个函数及时测试, 导致后面的函数增加后,测试难度加大,需要用更多的时间来排查错误,下次需要改进。 WC项目——python实现 标签:改变 含义 image 若是 利用 放弃 测试结果 特殊情况 complex 原文地址:https://www.cnblogs.com/cc-cc/p/9648816.html
高级功能(未实现)
#检查文件的合法性
def check_file(self):
if re.match(r"[a-zA-Z0-9]*\..",self.file_name):
self.file_list.append(os.path.abspath(self.file_name))
return True
elif re.match("([\*\?$]+\.[a-zA-Z]+$)",self.file_name):
return True
print("The file name is not right.")
return False
#检查命令的合法性
def check_command(self):
for i in range(1,self.order_number-1):
if (self.order_list[i]!=‘-w‘) and self.order_list[i]!=‘-c‘ and self.order_list[i]!=‘-l‘ and self.order_list[i]!=‘-s‘ and self.order_list[i]!=‘-a‘:
print("The order does not exist")
return False
break
return True
#统计字符数
def re_chara(self,ff):
count1 = 0
for i in ff:
count1 += len(i.rstrip())
return count1
#统计单词数(由于readlines读出的每一行都会有最后的换行符,所以用rstrip函数去掉)
def re_word(self,ff):
count2 = 0
string_after = ""
for i in ff:
string_after+=i.rstrip()
new_a = re.sub("[^a-zA-z0-9\s]"," ",string_after)
words = new_a.split()
for word in words:
if word != "":
count2 += 1
return count2
#统计行数
def re_line(self,ff):
return len(ff)
#查看目录中的文件
def file_recurse(self,pathh):
#列出文件夹中所有的文件,包括文件夹
files = os.listdir(pathh)
#分割输入的文件名
p1=self.order_list[self.order_number-1].split(".")
#拼接为后缀名
p = "."+ p1[1].upper()
for f in files:
#拼接为完整路径
real_path = os.path.join(pathh,f)
#如果是文件
if os.path.isfile(real_path):
#分隔路径
spl = os.path.splitext(real_path)
if spl[1].upper()==p:
#把路径加入文件列表
self.file_list.append(real_path)
#若是文件夹,则递归
if os.path.isdir(real_path):
self.file_recurse(real_path)
#判断注释行
def explain_search(self,k,flag):
if re.search(r"//",k) != None:
flag = 1
return flag
if re.search(r"/\*",k)!= None:
flag = 0
if re.search(r"\*/",k)!= None:
flag=1
return flag
#处理复杂数据
def complex_data(self,ff):
#标志空行
empty_l = 0
#标志代码行
code_num = 0
#标志注释行
explanation = 0
#用来/**/注释方式的出现
flag = 0
for i in ff:
k = i.strip()
if len(k):
empty_l += 1
elif all_operation.explain_search(self,i,flag)==True:
explanation += 1
elif len(k)>1:
code_num += 1
print("空行:"+str(empty_l))
print("代码行:"+str(code_num))
print("注释行:"+str(explanation))
def menu(self):
for f in self.file_list:
try:
with open(f) as file_object:
ff = file_object
f1 = ff.readlines()
print(os.path.abspath(f))
for i in range(1, num-1):
if self.order_list[i] == ‘-c‘:
print("Characters: "+ str(all_operation.re_chara(self,f1)))
elif self.order_list[i] == ‘-w‘:
print("Words: "+ str(all_operation.re_word(self,f1)))
elif self.order_list[i] == "-l":
print("Lines: "+ str(all_operation.re_line(self,f1)))
elif self.order_list[i] == ‘-s‘:
continue
elif self.order_list[i] == ‘-a‘:
all_operation.complex_data(self,f1)
else:
print("the order is wrong, please try again")
except FileNotFoundError:
msg = "file: " + os.path.basename(f) + " does not exist"
print (msg)
num = len(sys.argv)
#设置一个文件夹列表,存放文件路径
file_list=[]
#检查是否有足够的参数
if num:
print("The parameters are not enough.")
else:
instance = check_every(sys.argv[num-1],file_list, num, sys.argv)
if instance.check_file()==True and instance.check_command()==True:
instan = all_operation(file_list, num, sys.argv)
if len(file_list)==0:
pp = os.path.abspath(__file__)
instan.file_recurse(os.path.dirname(pp))
if len(file_list)==0:
print("There is no such file")
else:
instan.menu()