python 实现 wc.exe
2021-06-28 20:07
标签:imei div 多个 action inf lib 设置 readlines 令行 wc.exe 是一个常见的工具,它能统计文本文件的字符数、单词数和行数。这个项目要求写一个命令行程序,模仿已有wc.exe 的功能,并加以扩充,给出某程序设计语言源文件的字符数、单词数和行数。实现一个统计程序,它能正确统计程序文件中的字符数、单词数、行数,以及还具备其他扩展功能,并能够快速地处理多个文件。 拓展功能: Personal Software Process Stages 预估耗时(分钟) 实际耗时(分钟) 计划 -估计这个任务需要多少时间 开发 ·-需求分析 (包括学习新技术) -生成设计文档 -具体编码 报告 -测试报告 -事后总结, 并提出过程改进计划 使用if-elif-else结构读取命令行,并跳转到指定的函数,输出结果。 计算文件中的换行符个数 通过判断字母前是否有非字母字符存在来确定一个单词的开始,并使计数器+1 对正则表达式的使用还不是很熟练,所以使用了类似c的实现 总共设置了5个标记:mark_flag(当前是否处于字符串中)、block_comment_flag(当前是否处于一个块注释中)、line_comment_flag(当前字符是否在一个行注释中)、slash(前一个字符是否是一个斜杠)和 测试样例: python 实现 wc.exe 标签:imei div 多个 action inf lib 设置 readlines 令行 原文地址:https://www.cnblogs.com/AndyVirginia/p/9648599.html前言:
项目简介:
程序处理用户需求的模式为:wc.exe [parameter] [file_name]
wc.exe -c file.c//返回文件 file.c 的字符数(实现)wc.exe -w file.c//返回文件 file.c 的词的数目(实现)wc.exe -l file.c//返回文件 file.c 的行数(实现)
只有不超过一个可显示的字符,例如“{”。
} //注释
在这种情况下,这一行属于注释行。
需求举例:wc.exe -s -a *.c
返回当前目录及子目录中所有*.c 文件的代码行数、空行数、注释行数。PSP:
60
70
180
150
60
60
-代码规范 (为目前的开发制定合适的规范)
30
30
-具体设计
120
120
240
300
-代码复审
60
80
-测试(自我测试,修改代码,提交修改)
60
60
60
60
-计算工作量
30
30
60
60
总计
解题思路:
关键代码:
主函数:
def main():
# 主程序
parser = OptionParser()
parser.add_option(‘-c‘,‘--char‘, dest = ‘char‘, action = ‘store‘,
default = False, help = ‘only user to count chars‘)
parser.add_option(‘-l‘, ‘--line‘, dest = ‘line‘, action = ‘store‘,
default = False, help = ‘only user to count lines‘)
parser.add_option(‘-w‘, ‘--word‘, dest = ‘word‘, action = ‘store‘,
default = False, help = ‘only user to count words‘)
parser.add_option(‘-a‘, dest = ‘type‘, action = ‘store‘,
default = False, help = ‘only user to count type of line‘)
option, args = parser.parse_args()
if option.char:
print(chars(option.char))
elif option.line:
print(lines(option.line))
elif option.word:
print(words(option.word))
elif option.type:
print(type(option.type))
else:
print(‘无效的命令行参数!‘)
行数统计:
def lines(args):
‘‘‘ 返回文件 file.c 的行数‘‘‘
try:
with open(args,‘r‘,encoding=‘UTF-8‘) as file:# 指定读取的编码方式为UTF-8
i = file.read().count(‘\n‘)
return i+1
except FileNotFoundError:
return ‘未找到该文件!‘
词数统计:
def words(args):
# 返回文件单词数
try:
with open(args,‘r‘,encoding=‘UTF-8‘) as f:
file = f.readlines()
space_flag = False # 标记上一个字符是否为空格
words_num = 0
for x in file:
for y in x:
if (y ‘Z‘) and (y ‘z‘):
space_flag = True
else:
if space_flag == True:
words_num += 1
space_flag = False
return words_num
except FileNotFoundError:
return ‘未找到该文件!‘
字符数统计:
def chars(args):
# 返回文件字符个数
try:
with open(args,‘r‘,encoding=‘UTF-8‘) as f:
file = f.readlines()
num = 0
for x in file:
for y in x:
if (y >= ‘A‘ and y = ‘a‘ and y ):
num += 1
return num
except FileNotFoundError:
return ‘未找到该文件!‘
拓展功能:支持 -a 参数:
asterisk(前一个字符是否是一个*)。并设置了一个计数器计算当前行的代码字符数。
def type(args):
space_line = 0
comment_line = 0
code_line = 0
try:
with open(args,‘r‘,encoding=‘UTF-8‘) as file:
mark_flag = False # 双引号标记
block_comment_flag = False # 块注释标记
for line in file.readlines():
line_comment_flag = False # 行注释标记
code_num = 0 # 行代码字符数
slash = False
asterisk = False
for char in line:
if char != ‘ ‘:
if block_comment_flag == False and line_comment_flag == False:
# 不处于注释中时记录代码字符个数
code_num += 1
if char == ‘\"‘ and not block_comment_flag:
# 当当前的字符不处于一条注释中时,对字符串进行判定
if mark_flag:
# 如果字符串已开始,结束字符串
mark_flag = False
else:
# 否则开始一个字符串,置标记为真
mark_flag = True
elif char == ‘/‘ and not mark_flag and not block_comment_flag:
# 当当前不处于字符串和块注释中,对注释进行判定
if not slash:
slash = True
else:
# 当前一个字符为一个斜杠,说明此时开始了一个行注释
line_comment_flag = True
# 前面计数器将两个斜杠记为代码字符,应减去避免统计错误
code_num -= 2
elif slash and char == ‘*‘ and not mark_flag:
# 当当前不处于字符串时,判断一个块注释
block_comment_flag = True
code_num -= 2
elif block_comment_flag and char == ‘*‘:
# 判断在块注释中是否出现一个星号
asterisk = True
elif asterisk:
if char == ‘/‘:
# 结束一个块注释,并将其最后一行作为行注释处理
block_comment_flag = False
line_comment_flag = True
if code_num > 1:
# 若当前行代码字符超过1视为代码行
code_line += 1
else:
if block_comment_flag or line_comment_flag:
comment_line += 1
else:
space_line += 1
return ‘代码行:‘+str(code_line)+‘\n注释行:‘+str(comment_line)+‘\n空行:‘+str(space_line)
except FileNotFoundError:
return ‘找不到该文件‘
测试:
#include
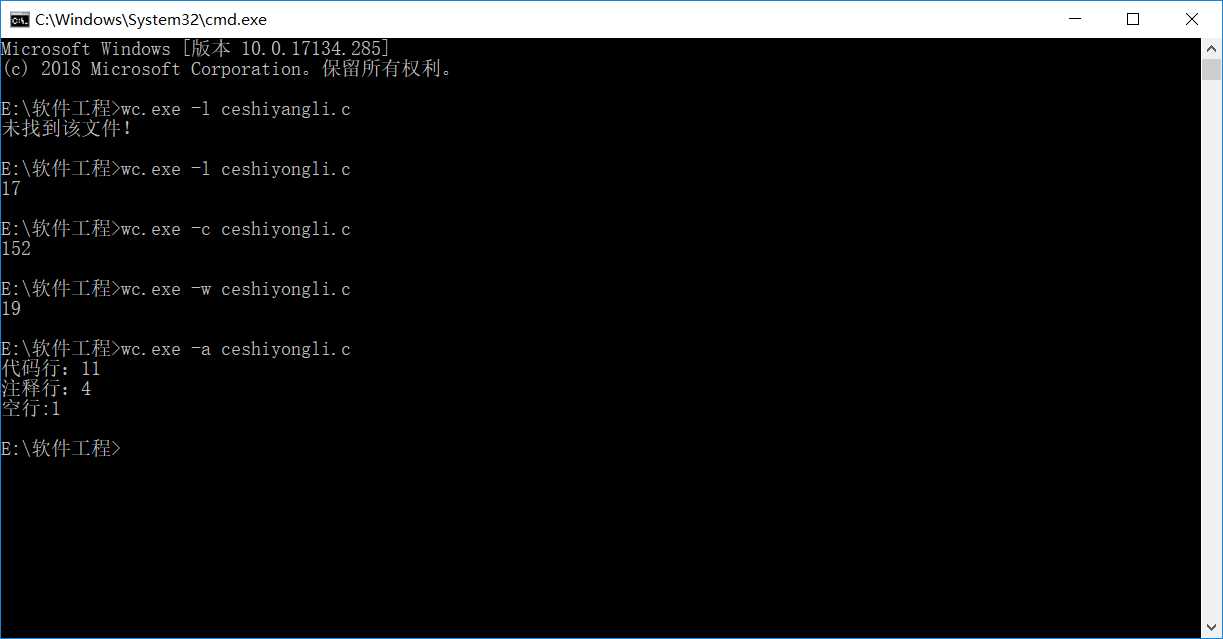
项目小结:
上一篇:Python最新版还原VX撤回消息教程!这波你给几分?
下一篇:python010