【Python】动手分析天猫内衣售卖数据,得到你想知道的信息
2021-06-29 20:04
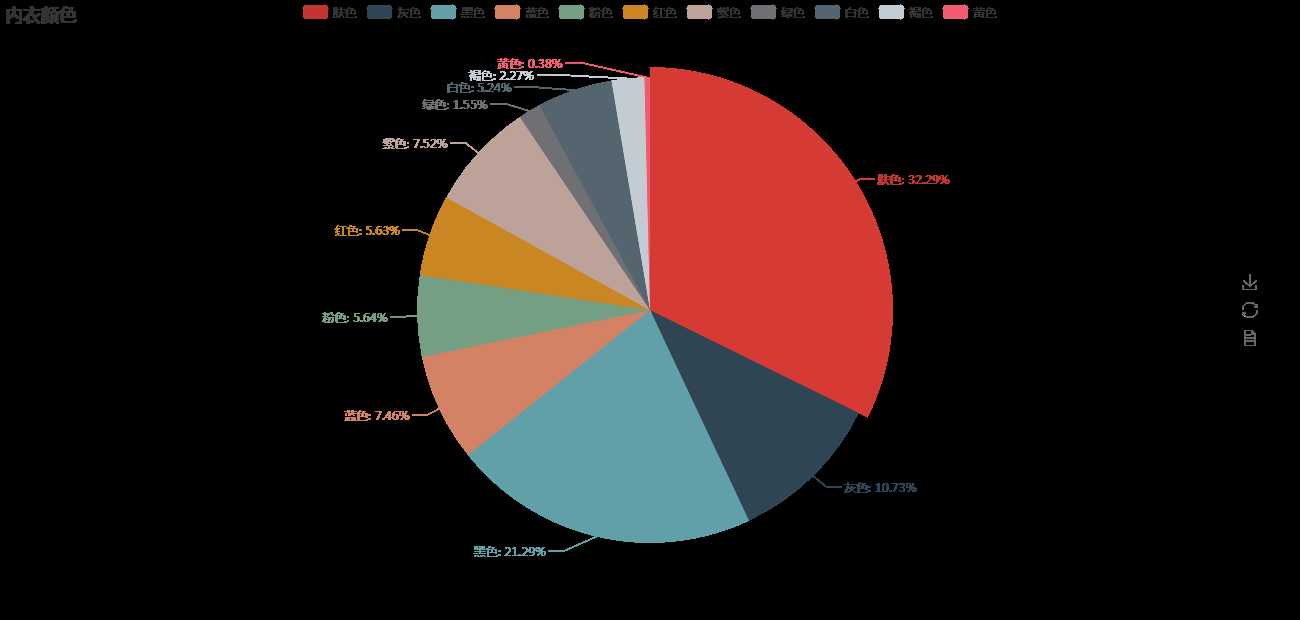
标签:获取 完成 不同的 执行 cli enc 影响 最大 功能 大家好,我是一个老实人,现在我决定用 Python 抓取天猫内衣销售数据,并分析得到中国女性普遍的罩杯数据,和最受欢迎的内衣颜色是什么。 希望看完之后你能替你女朋友买上一件心怡的内衣。 我们先看看分析得到的成果是怎样的?(讲的很详细,推荐跟着敲一遍) 图片看不清楚的话,可以把图片单独拉到另一个窗口。 这里是分析了一万条数据得出的结论,可能会有误差,但是还是希望单身的你们能找到 0.06% 那一批妹纸。 下面我会详细介绍怎么抓取天猫内衣销售数据,存储、分析、展示。 研究天猫网站 我们随意进入一个商品的购买界面(能看到评论的那个界面),F12 开发者模式 -- Network 栏 -- 刷新下界面 -- 在如图的位置搜索 list_ 会看到一个 list_detail_rate.htm?itemId= .... 如下图:【单击】这个url 能看到返回的是一个 Json 数据 ,检查一下你会发现这串 Json 就是商品的评论数据 [‘rateDetail‘][‘rateList‘] 【双击】这个url 你会得到一个新界面,如图 看一下这个信息 这里的路径 就是获取评论数据的 url了。这个 URL 有很多参数你可以分析一下每个值都是干嘛的。 itemId 对应的是商品id, sellerId 对应的是店铺id,currentPage 是当前页。这里 sellerId 可以填任意值,不影响数据的获取。 抓取天猫评论数据 写一个抓取天猫评论数据的方法。getCommentDetail 这里需要注意的是 jsonp128 这个值需要你自己看一下,你那边跟我这个应该是不同的。 还有几十 common 这我自己封装的一个工具类,主要就是上一篇博客里写的一些功能,想 requests 和 pymysql 模块的功能。在文章最后我会贴出来。 在上面的方法里有两个变量,itemId 和 currentPage 这两个值我们动态来控制,所以我们需要获得 一批 商品id号 和 评论的最大页数 用来遍历。 写个获取商品评论最大页数的方法 getLastPage 那现在怎么获取 产品的id 列表呢? 我们可以在天猫中搜索商品关键字 用开发者模式观察 这里观察一下这个页面的元素分布,很容易就发现了 商品的id 信息,当然你可以想办法确认一下。 现在就写个 获取商品id 的方法 getProductIdList 现在所有的基本要求都有了,是时候把他们组合起来。 在 main 方法中写剩下的组装部分 所有的代码就这样完成了,我现在把 common.py 的代码,还有 tmallbra.py 的代码都贴出来 上面需要注意,数据库的配置。 存储、分析数据 所有的代码都有了,就差数据库的建立了。我这里用的是 MySql 数据库。 这里有两个地方需要注意, comment 评论字段需要设置编码格式为 utf8mb4 ,因为可能有表情文字。还有表需要设置为 utf8 编码,不然存不了中文。 建好了表,就可以完整执行代码了。(这里的执行可能需要点时间,可以做成多线程的方式)。看一下执行完之后,数据库有没有数据。 数据是有了,但是有些我们多余的文字描述,我们可以稍微整理一下。 这里需要根据自己实际情况来修改。如果数据整理的差不多了,我们可以分析一下数据库的信息。 (想知道是哪6位小姐姐买的 G (~ ̄▽ ̄)~ ) 数据可视化 数据的展示,我用了是 mycharts 模块,如果不了解的可以去 学习一下 http://pyecharts.org/#/zh-cn/prepare 这里我就不细说了,直接贴代码看 这一章就到这里了,该知道的你也知道了,不该知道的你也知道了。 代码全部存放在 GitHub 上 https://github.com/zwwjava/python_capture 【Python】动手分析天猫内衣售卖数据,得到你想知道的信息 标签:获取 完成 不同的 执行 cli enc 影响 最大 功能 原文地址:https://www.cnblogs.com/zhaww/p/9636383.html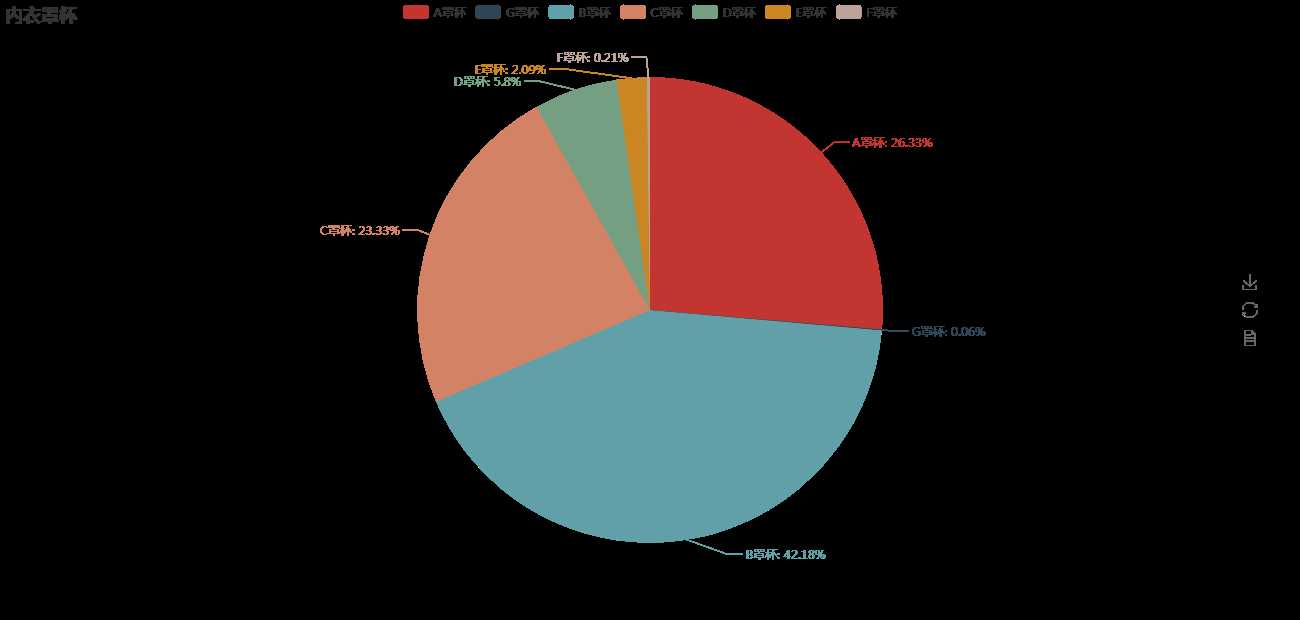
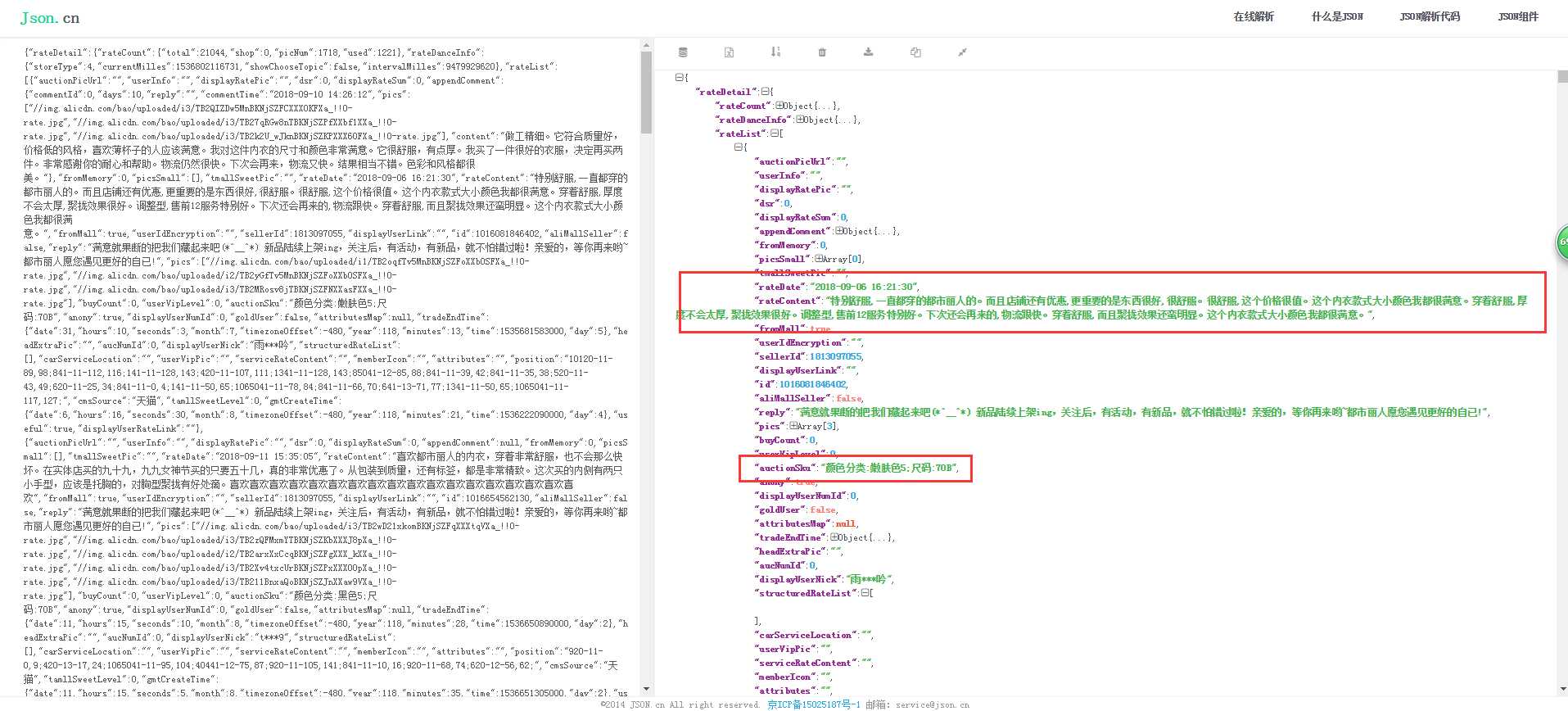
# 获取商品评论数据
def getCommentDetail(itemId,currentPage):
url = ‘https://rate.tmall.com/list_detail_rate.htm?itemId=‘ + str(
itemId) + ‘&sellerId=2451699564&order=3¤tPage=‘ + str(currentPage) + ‘&append=0callback=jsonp336‘
# itemId 产品id ; sellerId 店铺id 字段必须有值,但随意值就行
html = common.getUrlContent(url) # 获取网页信息
# 删掉返回的多余信息
html = html.replace(‘jsonp128(‘,‘‘) #需要确定是不是 jsonp128
html = html.replace(‘)‘,‘‘)
html = html.replace(‘false‘,‘"false"‘)
html = html.replace(‘true‘,‘"true"‘)
# 将string 转换为字典对象
tmalljson = json.loads(html)
return tmalljson
# 获取商品评论最大页数
def getLastPage(itemId):
tmalljson = getCommentDetail(itemId,1)
return tmalljson[‘rateDetail‘][‘paginator‘][‘lastPage‘] #最大页数
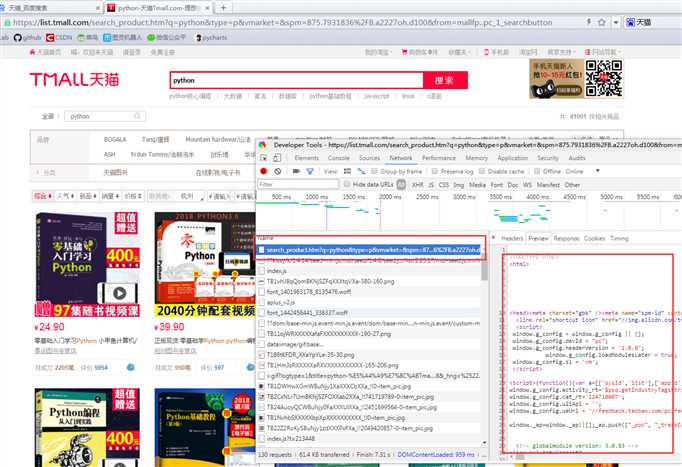
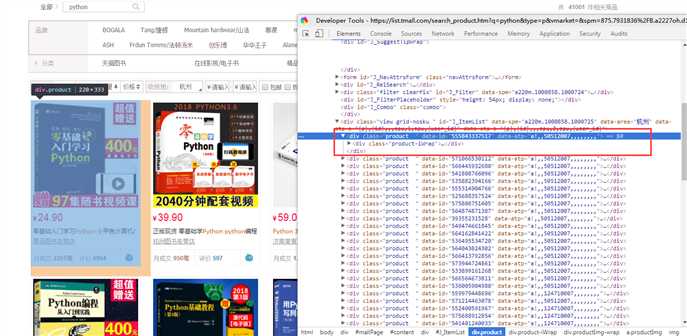
# 获取商品id
def getProductIdList():
url = ‘https://list.tmall.com/search_product.htm?q=内衣‘ # q参数 是查询的关键字
html = common.getUrlContent(url) # 获取网页信息
soup = BeautifulSoup(html,‘html.parser‘)
idList = []
# 用Beautiful Soup提取商品页面中所有的商品ID
productList = soup.find_all(‘div‘, {‘class‘: ‘product‘})
for product in productList:
idList.append(product[‘data-id‘])
return idList
if __name__ == ‘__main__‘:
productIdList = getProductIdList() #获取商品id
initial = 0
while initial # 总共有60个商品,我只取了前30个
try:
itemId = productIdList[initial]
print(‘----------‘, itemId, ‘------------‘)
maxPage = getLastPage(itemId) #获取商品评论最大页数
num = 1
while num and num #每个商品的评论我最多取20 页,每页有20条评论,也就是每个商品最多只取 400 个评论
try:
# 抓取某个商品的某页评论数据
tmalljson = getCommentDetail(itemId, num)
rateList = tmalljson[‘rateDetail‘][‘rateList‘]
commentList = []
n = 0
while (n len(rateList)):
comment = []
# 商品描述
colorSize = rateList[n][‘auctionSku‘]
m = re.split(‘[:;]‘, colorSize)
rateContent = rateList[n][‘rateContent‘]
dtime = rateList[n][‘rateDate‘]
comment.append(m[1])
comment.append(m[3])
comment.append(‘天猫‘)
comment.append(rateContent)
comment.append(dtime)
commentList.append(comment)
n += 1
print(num)
sql = "insert into bras(bra_id, bra_color, bra_size, resource, comment, comment_time) value(null, %s, %s, %s, %s, %s)"
common.patchInsertData(sql, commentList) # mysql操作的批量插入
num += 1
except Exception as e:
num += 1
print(e)
continue
initial += 1
except Exception as e:
print(e)
# -*- coding:utf-8 -*-
# Author: zww
import requests
import time
import random
import socket
import http.client
import pymysql
import csv
# 封装requests
class Common(object):
def getUrlContent(self, url, data=None):
header = {
‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8‘,
‘Accept-Encoding‘: ‘gzip, deflate, br‘,
‘Accept-Language‘: ‘zh-CN,zh;q=0.9,en;q=0.8‘,
‘user-agent‘: "User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
‘cache-control‘: ‘max-age=0‘
} # request 的请求头
timeout = random.choice(range(80, 180))
while True:
try:
rep = requests.get(url, headers=header, timeout=timeout) # 请求url地址,获得返回 response 信息
# rep.encoding = ‘utf-8‘
break
except socket.timeout as e: # 以下都是异常处理
print(‘3:‘, e)
time.sleep(random.choice(range(8, 15)))
except socket.error as e:
print(‘4:‘, e)
time.sleep(random.choice(range(20, 60)))
except http.client.BadStatusLine as e:
print(‘5:‘, e)
time.sleep(random.choice(range(30, 80)))
except http.client.IncompleteRead as e:
print(‘6:‘, e)
time.sleep(random.choice(range(5, 15)))
print(‘request success‘)
return rep.text # 返回的 Html 全文
def writeData(self, data, url):
with open(url, ‘a‘, errors=‘ignore‘, newline=‘‘) as f:
f_csv = csv.writer(f)
f_csv.writerows(data)
print(‘write_csv success‘)
def queryData(self, sql):
db = pymysql.connect("localhost", "zww", "960128", "test")
cursor = db.cursor()
results = []
try:
cursor.execute(sql) #执行查询语句
results = cursor.fetchall()
except Exception as e:
print(‘查询时发生异常‘ + e)
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
return results
print(‘insert data success‘)
def insertData(self, sql):
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "000000", "zwwdb")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
try:
# sql = "INSERT INTO WEATHER(w_id, w_date, w_detail, w_temperature) VALUES (null, ‘%s‘,‘%s‘,‘%s‘)" % (data[0], data[1], data[2])
cursor.execute(sql) #单条数据写入
# 提交到数据库执行
db.commit()
except Exception as e:
print(‘插入时发生异常‘ + e)
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
print(‘insert data success‘)
def patchInsertData(self, sql, datas):
# 打开数据库连接
db = pymysql.connect("localhost", "zww", "960128", "test")
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
try:
# 批量插入数据
# cursor.executemany(‘insert into WEATHER(w_id, w_date, w_detail, w_temperature_low, w_temperature_high) value(null, %s,%s,%s,%s)‘,datas)
cursor.executemany(sql, datas)
# 提交到数据库执行
db.commit()
except Exception as e:
print(‘插入时发生异常‘ + e)
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
print(‘insert data success‘)
# -*- coding:utf-8 -*-
# Author: zww
from Include.commons.common import Common
from bs4 import BeautifulSoup
import json
import re
import pymysql
common = Common()
# 获取商品id
def getProductIdList():
url = ‘https://list.tmall.com/search_product.htm?q=内衣‘ # q参数 是查询的关键字,这要改变一下查询值,就可以抓取任意你想知道的数据
html = common.getUrlContent(url) # 获取网页信息
soup = BeautifulSoup(html,‘html.parser‘)
idList = []
# 用Beautiful Soup提取商品页面中所有的商品ID
productList = soup.find_all(‘div‘, {‘class‘: ‘product‘})
for product in productList:
idList.append(product[‘data-id‘])
return idList
# 获取商品评论数据
def getCommentDetail(itemId,currentPage):
url = ‘https://rate.tmall.com/list_detail_rate.htm?itemId=‘ + str(
itemId) + ‘&sellerId=2451699564&order=3¤tPage=‘ + str(currentPage) + ‘&append=0callback=jsonp336‘
# itemId 产品id ; sellerId 店铺id 字段必须有值,但随意值就行
html = common.getUrlContent(url) # 获取网页信息
# 删掉返回的多余信息
html = html.replace(‘jsonp128(‘,‘‘) #需要确定是不是 jsonp128
html = html.replace(‘)‘,‘‘)
html = html.replace(‘false‘,‘"false"‘)
html = html.replace(‘true‘,‘"true"‘)
# 将string 转换为字典对象
tmalljson = json.loads(html)
return tmalljson
# 获取商品评论最大页数
def getLastPage(itemId):
tmalljson = getCommentDetail(itemId,1)
return tmalljson[‘rateDetail‘][‘paginator‘][‘lastPage‘] #最大页数
if __name__ == ‘__main__‘:
productIdList = getProductIdList() #获取商品id
initial = 0
while initial # 总共有60个商品,我只取了前30个
try:
itemId = productIdList[initial]
print(‘----------‘, itemId, ‘------------‘)
maxPage = getLastPage(itemId) #获取商品评论最大页数
num = 1
while num and num #每个商品的评论我最多取20 页,每页有20条评论,也就是每个商品最多只取 400 个评论
try:
# 抓取某个商品的某页评论数据
tmalljson = getCommentDetail(itemId, num)
rateList = tmalljson[‘rateDetail‘][‘rateList‘]
commentList = []
n = 0
while (n len(rateList)):
comment = []
# 商品描述
colorSize = rateList[n][‘auctionSku‘]
m = re.split(‘[:;]‘, colorSize)
rateContent = rateList[n][‘rateContent‘]
dtime = rateList[n][‘rateDate‘]
comment.append(m[1])
comment.append(m[3])
comment.append(‘天猫‘)
comment.append(rateContent)
comment.append(dtime)
commentList.append(comment)
n += 1
print(num)
sql = "insert into bras(bra_id, bra_color, bra_size, resource, comment, comment_time) value(null, %s, %s, %s, %s, %s)"
common.patchInsertData(sql, commentList) # mysql操作的批量插入
num += 1
except Exception as e:
num += 1
print(e)
continue
initial += 1
except Exception as e:
print(e)
CREATE TABLE `bra` (
`bra_id` int(11) NOT NULL AUTO_INCREMENT COMMENT ‘id‘ ,
`bra_color` varchar(25) NULL COMMENT ‘颜色‘ ,
`bra_size` varchar(25) NULL COMMENT ‘罩杯‘ ,
`resource` varchar(25) NULL COMMENT ‘数据来源‘ ,
`comment` varchar(500) CHARACTER SET utf8mb4 DEFAULT NULL COMMENT ‘评论‘ ,
`comment_time` datetime NULL COMMENT ‘评论时间‘ ,
PRIMARY KEY (`bra_id`)
) character set utf8
;
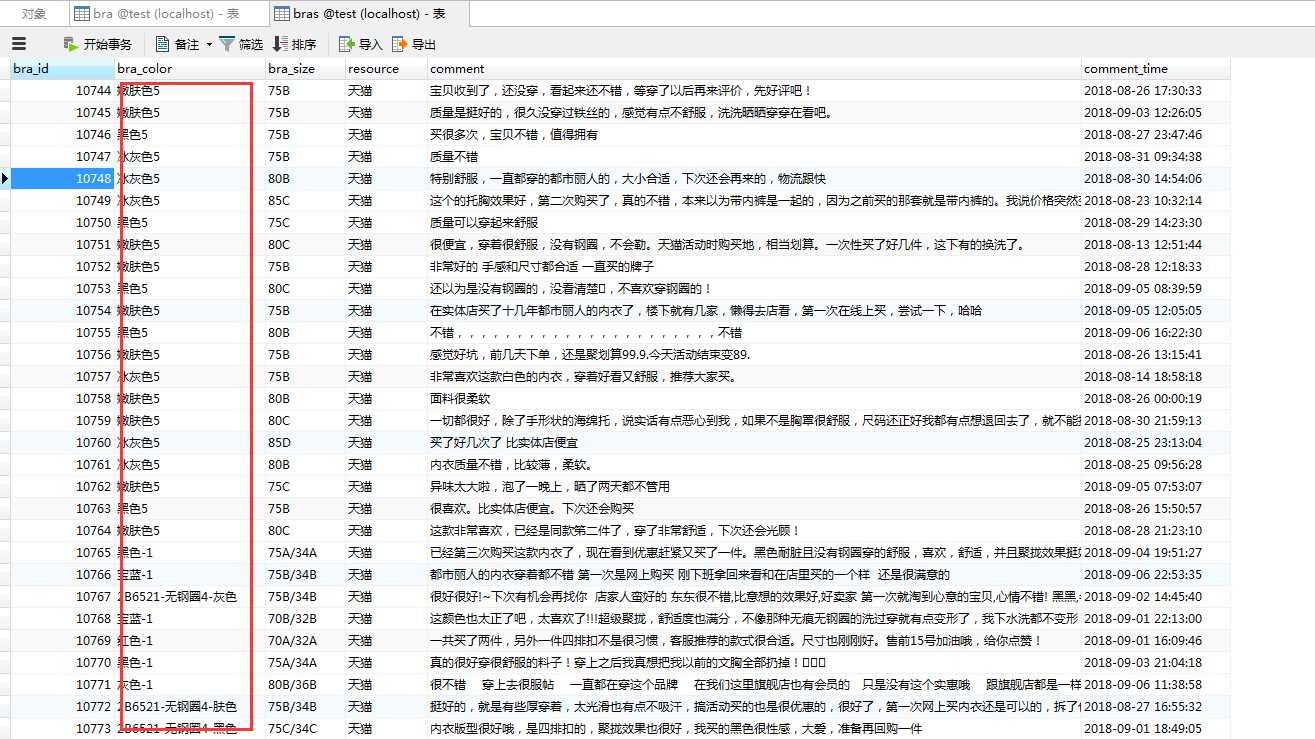
update bra set bra_color = REPLACE(bra_color,‘2B6521-无钢圈4-‘,‘‘);
update bra set bra_color = REPLACE(bra_color,‘-1‘,‘‘);
update bra set bra_color = REPLACE(bra_color,‘5‘,‘‘);
update bra set bra_size = substr(bra_size,1,3);
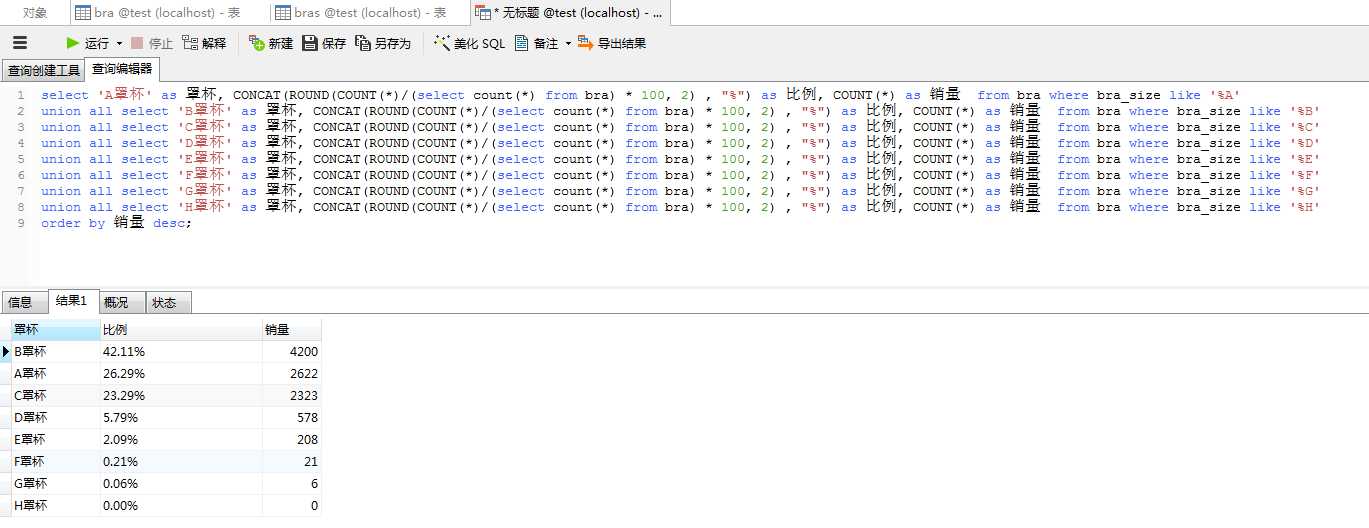
select ‘A罩杯‘ as 罩杯, CONCAT(ROUND(COUNT(*)/(select count(*) from bra) * 100, 2) , "%") as 比例, COUNT(*) as 销量 from bra where bra_size like ‘%A‘
union all select ‘B罩杯‘ as 罩杯, CONCAT(ROUND(COUNT(*)/(select count(*) from bra) * 100, 2) , "%") as 比例, COUNT(*) as 销量 from bra where bra_size like ‘%B‘
union all select ‘C罩杯‘ as 罩杯, CONCAT(ROUND(COUNT(*)/(select count(*) from bra) * 100, 2) , "%") as 比例, COUNT(*) as 销量 from bra where bra_size like ‘%C‘
union all select ‘D罩杯‘ as 罩杯, CONCAT(ROUND(COUNT(*)/(select count(*) from bra) * 100, 2) , "%") as 比例, COUNT(*) as 销量 from bra where bra_size like ‘%D‘
union all select ‘E罩杯‘ as 罩杯, CONCAT(ROUND(COUNT(*)/(select count(*) from bra) * 100, 2) , "%") as 比例, COUNT(*) as 销量 from bra where bra_size like ‘%E‘
union all select ‘F罩杯‘ as 罩杯, CONCAT(ROUND(COUNT(*)/(select count(*) from bra) * 100, 2) , "%") as 比例, COUNT(*) as 销量 from bra where bra_size like ‘%F‘
union all select ‘G罩杯‘ as 罩杯, CONCAT(ROUND(COUNT(*)/(select count(*) from bra) * 100, 2) , "%") as 比例, COUNT(*) as 销量 from bra where bra_size like ‘%G‘
union all select ‘H罩杯‘ as 罩杯, CONCAT(ROUND(COUNT(*)/(select count(*) from bra) * 100, 2) , "%") as 比例, COUNT(*) as 销量 from bra where bra_size like ‘%H‘
order by 销量 desc;
# encoding: utf-8
# author zww
from pyecharts import Pie
from Include.commons.common import Common
if __name__ == ‘__main__‘:
common = Common()
results = common.queryData("""select count(*) from bra where bra_size like ‘%A‘
union all select count(*) from bra where bra_size like ‘%B‘
union all select count(*) from bra where bra_size like ‘%C‘
union all select count(*) from bra where bra_size like ‘%D‘
union all select count(*) from bra where bra_size like ‘%E‘
union all select count(*) from bra where bra_size like ‘%F‘
union all select count(*) from bra where bra_size like ‘%G‘""") # 获取每个罩杯数量
attr = ["A罩杯", ‘G罩杯‘, "B罩杯", "C罩杯", "D罩杯", "E罩杯", "F罩杯"]
v1 = [results[0][0], results[6][0], results[1][0], results[2][0], results[3][0], results[4][0], results[5][0]]
pie = Pie("内衣罩杯", width=1300, height=620)
pie.add("", attr, v1, is_label_show=True)
pie.render(‘size.html‘)
print(‘success‘)
results = common.queryData("""select count(*) from bra where bra_color like ‘%肤%‘
union all select count(*) from bra where bra_color like ‘%灰%‘
union all select count(*) from bra where bra_color like ‘%黑%‘
union all select count(*) from bra where bra_color like ‘%蓝%‘
union all select count(*) from bra where bra_color like ‘%粉%‘
union all select count(*) from bra where bra_color like ‘%红%‘
union all select count(*) from bra where bra_color like ‘%紫%‘
union all select count(*) from bra where bra_color like ‘%绿%‘
union all select count(*) from bra where bra_color like ‘%白%‘
union all select count(*) from bra where bra_color like ‘%褐%‘
union all select count(*) from bra where bra_color like ‘%黄%‘ """) # 获取每个罩杯数量
attr = ["肤色", ‘灰色‘, "黑色", "蓝色", "粉色", "红色", "紫色", ‘绿色‘, "白色", "褐色", "黄色"]
v1 = [results[0][0], results[1][0], results[2][0], results[3][0], results[4][0], results[5][0], results[6][0], results[7][0], results[8][0], results[9][0], results[10][0]]
pieColor = Pie("内衣颜色", width=1300, height=620)
pieColor.add("", attr, v1, is_label_show=True)
pieColor.render(‘color.html‘)
print(‘success‘)
文章标题:【Python】动手分析天猫内衣售卖数据,得到你想知道的信息
文章链接:http://soscw.com/index.php/essay/99512.html