浙大《数据结构》第九章:排序(上)
2021-01-29 17:17
标签:取出 i++ 问题 序列 while scanf delete 第一个 zju 注:本文使用的网课资源为中国大学MOOC https://www.icourse163.org/course/ZJU-93001
基本思想: 时间复杂度: 稳定性:是 A[i+1])
{
Swap(A[i], A[i+1]);
flag = 0; // 标识发生了交换
}
}
if (flag==0) // 如果第一趟冒泡全程无交换
break;
}
}
基本思想: 时间复杂度: 稳定性:是 ——(34,8) (34,32) (34,21) (64,51) (64,32) (64,21) (51,32) (51,21) (32,21) ——如果序列基本有序,则插入排序简单且高效
归纳为: 原始希尔排序 : \(D_M = \left \lfloor N/2 \right \rfloor, D_k = \left \lfloor D_{k+1}/2 \right \rfloor\) Hibbard增量序列 Sedgewick增量序列
思路: 思路:与选择排序类似,但是改变最小元的扫描策略,利用堆结构扫描 算法1 思路: 因此: 算法2: 思路:
将子序列A,B的元素依次比较,合并成C序列 可以推得:T(N) = T(N/2)+T(N/2)+O(N) --> T(N)=O(N logN ) 统一函数接口 思路: 结论: 浙大《数据结构》第九章:排序(上) 标签:取出 i++ 问题 序列 while scanf delete 第一个 zju 原文地址:https://www.cnblogs.com/Superorange/p/12831402.html简单排序
前提
void X_Sort( ElementType A[], int N )
冒泡排序
void Bubble_Sort( ElementType A[], int N )
{
int P,i,flag;
for (P=N-1; P>=0; P--)
{
flag = 0;
for (i=0; i插入排序
void Insertion_Sort( ElementType A[], int N )
{
int P, i;
ElementType Tmp;
for ( P=1; P时间复杂度下界
希尔排序
举个例子
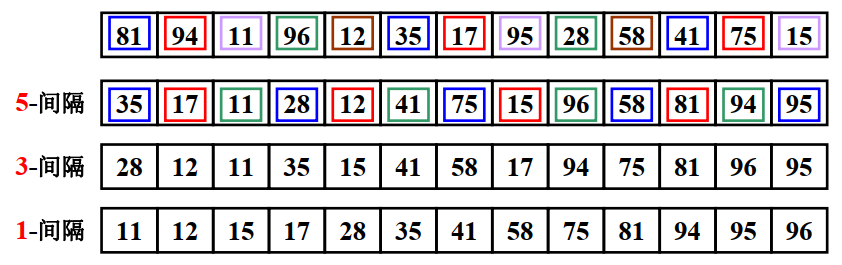
原始希尔增量序列
void Shell_Sort( ElementType A[], int N )
{
int D,P,i;
ElementType Tmp;
for ( D=N/2; D>0; D/=2 ) // 希尔增量序列
{
for ( P=D; P更多增量序列
/* 希尔排序 - 用Sedgewick增量序列 */
void ShellSort( ElementType A[], int N )
{
int Si, D, P, i;
ElementType Tmp;
/* 这里只列出一小部分增量 */
int Sedgewick[] = {929, 505, 209, 109, 41, 19, 5, 1, 0};
for ( Si=0; Sedgewick[Si]>=N; Si++ )
; /* 初始的增量Sedgewick[Si]不能超过待排序列长度 */
for ( D=Sedgewick[Si]; D>0; D=Sedgewick[++Si] )
for ( P=D; P堆排序
选择排序
void Selection_Sort( ElementType A[], int N )
{
int i, MinPosition;
for ( i=0; i堆排序
void Heap_Sort( ElementType A[], int N )
{
BuildHeap(A); // 将数组A调整为堆,复杂度为O(N)
for ( i=0; i
/* 交换 */
void Swap( ElementType *a, ElementType *b )
{
ElementType t = *a; *a = *b; *b = t;
}
/* 将N个元素的数组中以A[p]为根的子堆调整为最大堆 */
void PercDown( ElementType A[], int p, int N )
{
int Parent, Child;
ElementType X;
X = A[p]; /* 取出根结点存放的值 */
for( Parent=p; (Parent*2+1)
归并排序
核心思想:有序子列的归并
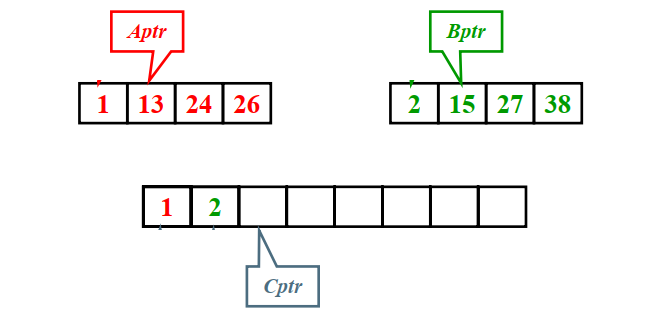
/* L = 左边起始位置, R = 右边起始位置, RightEnd = 右边终点位置 */
void Merge( ElementType A[], ElementType TmpA[], int L, int R, int RightEnd )
{
int LeftEnd, Tmp, NumElements;
LeftEnd = R - 1; // 左边终点位置。假设左右两列挨着
Tmp = L; // 存放结果的数组的初始位置
NumElements = RightEnd - L + 1;
while ( L递归版分而治之
void MSort( ElementType A[], ElementType TmpA[], int L, int RightEnd )
{
int Center;
if ( L void Merge_sort( ElementType A[], int N )
{
ElementType *TmpA;
TmpA = (ElementType *)malloc(N*sizeof( ElementType ))
if ( TmpA != NULL )
{
MSort(A, TmpS, 0, N-1);
free( TmpA );
}
else
Error("空间不足");
}
非递归版归并排序
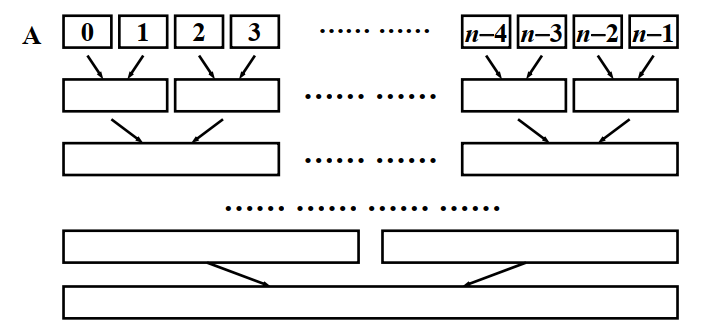
/* 归并排序 - 循环实现 */
/* 两两归并相邻有序子列 */
/* length = 当前有序子列的长度*/
void Merge_pass( ElementType A[], ElementType TmpA[], int N, int length )
{
int i, j;
for ( i=0; i