python系统学习4——多个爬虫测试案例
2021-04-26 13:27
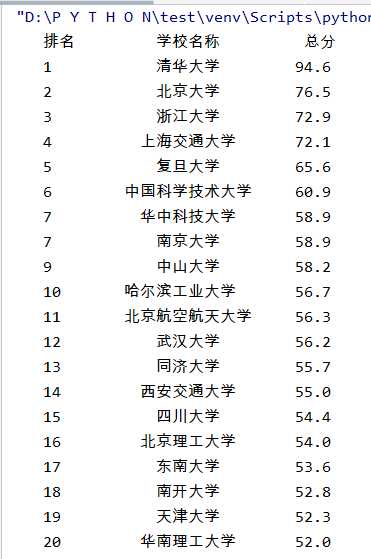
标签:淘宝 rom 基础框架 app http 部分 股票 过程 python 通过几天学习,对基础的静态网页、网页信息不是由js等动态显示的网页的爬虫编写有了较好的认识,用几个简单案例进行测试。 在编写过程中要注意几个问题:1、源网页robot.txt中对爬取规则的要求 2、对源网页信息的目标信息的分析 3、编程中注意模块化编写、代码复用和程序稳定性 案例1:全国大学排名 要求爬取全国大学网上2019年的全国大学排名,并展示出排名、名称及分数,由于每一个大学都是在一个tbody标签下,所以利用bs4较为简单 1、技术路线:requests+bs4 2、编写思路:函数分别为:网页爬取部分、数据处理部分、格式化输出部分 3、遇到问题:编写过程中遇到了几个问题: (1)网页原址较教学视频中的网址有改动,导致出现爬取结果为空,修改后问题解决 (2)在格式化输出中,为了让学校名称居中输出,用到了format函数,并在相应位置用chr(12288)中文空格来填充,结果较为美观 4、实验源码: 5、实验截图: 案例2:淘宝网关键词商品爬取 要求爬取淘宝网上“书包”商品信息,并格式化输出商品名、商品价格 (淘宝的robots.txt中“disallow:/”的内容,即淘宝是禁止爬虫进行信息爬取的,这里仍然进行了测试是非常不好的行为。) 1、技术路线:request+re(正则表达式) 2、编写思路:基础框架与案例1类似。 3、问题提出:在编写中要注意以下几个问题: (1)、在一个url中只有部分商品信息,要爬取更多信息需要有“翻页操作”,为解决这个办法,对网页进行分析发现,每翻一次页,url的末端&s参数会加44,利用这个性质完成翻页过程。 (2)、在实验中,会发现直接爬取无法返回结果,因为淘宝拒绝没有登录信息的访问,所以要在headers字段中加入cookie,通过开发者模式找到cookie(登录,然后找到开发者模式中的 header中的cookie字段),加入到代码中,问题解决。 (3)、关于正则表达式:淘宝页面源码中商品信息如下:以价格举例:"view_price":"129.00",他没有直接写在一个标签中,所以bs4并不理想,用正则表达式进行匹配更简单。 5、实验截图: 此外还进行了股票信息爬取,内容与其他区别不大,且基本没有遇到问题,不再列出 python系统学习4——多个爬虫测试案例 标签:淘宝 rom 基础框架 app http 部分 股票 过程 python 原文地址:https://www.cnblogs.com/xsy948306073/p/13252524.htmlimport requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find(‘tbody‘).children:
if isinstance(tr, bs4.element.Tag):
tds = tr(‘td‘)
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
tplt = "{0:^8}\t{1:{3}^8}\t{2:^10}"
print(tplt.format("排名", "学校名称", "总分", chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], chr(12288)))
def main():
uinfo = []
url = ‘http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html‘
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()
r‘\"view_price\"\:\"[\d\.]*\"‘这一正则表达式可以很好的匹配价格字段。
4、实验源码:import re
import requests
# 获得页面
def getHTMLText(url):
try:
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36",
"cookie": "隐私内容,如要使用代码,自行获取cookie"
}
r = requests.get(url, timeout=30, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
# 对页面进行解析
def parsePage(ilt,html):
try:
plt=re.findall(r‘\"view_price\"\:\"[\d\.]*\"‘,html)
tlt=re.findall(r‘\"raw_title\"\:\".*?\"‘,html)
for i in range(len(plt)):
price=eval(plt[i].split(":")[1]) #eval去掉双引号
title=eval(tlt[i].split(":")[1])
ilt.append([price,title])
except:
print("")
# 打印商品信息
def printGoodList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
print("")
# 主函数定义
def main():
goods = ‘书包‘ # 爬取商品
depth = 2 # 爬取深度
start_url = ‘https://s.taobao.com/search?q=‘ + goods
infoList = [] # 返回的结果
for i in range(depth):
try:
url = start_url + ‘&s=‘ + str(44 * i) # 加入页码
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodList(infoList)
# 主函数调用
main()
