lucene
2021-06-11 08:03
标签:数据库链接 如何 reader 简单 analysis dao google 停用 query Lucene 是apache下的一个开源的全文检索引擎工具包(类库)。它的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能。 它只是一个工具包,并不是一个完整的搜索引擎 全文检索 全文检索首先将要查询的目标文档中的词提取出来,组成索引,通过查询索引达到搜索目标文档的目的。这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。 lucene全文检索流程 全文检索要搜索的数据信息格式是多种多样的,比如:搜索引擎(百度, google),通过搜索引擎网站能搜索互联网上的网页(html)、互联网上的音乐(mp3..)、视频(avi..)、pdf电子书等。 全文检索搜索的这些数据称为非结构化数据。 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。 非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等。 如何对结构化数据搜索? 由于结构化数据是固定格式,所以就可以针对固定格式的数据设计算法来搜索,比如数据库like查询,like查询采用顺序扫描法,使用关键字匹配内容,对于内容量大的like查询速度慢。 如何对非结构化数据搜索? 需要将所有要搜索的非结构化数据通过技术手段采集到一个固定的地方,将这些非结构化的数据想办法组成结构化的数据,再以一定的算法去搜索。 由于数据源头是多种多样的,所以:需要将各种各样的数据按照一定的规则统一封装到lucene的文档对象中。有统一的规则,才能进行数据的存储,搜索。 采集数据的过程:就是将数据按照规则封装到lucene文档对象中的过程。 例如:数据库数据的采集 pojo类 dao接口代码 dao实现类 数据库采集,构建索引 IndexWriter是索引过程的核心组件,通过IndexWriter可以创建新索引、更新索引、删除索引操作。IndexWriter需要通过Directory对索引进行存储操作。 Directory描述了索引的存储位置,底层封装了I/O操作,负责对索引进行存储。它是一个抽象类,它的子类常用的包括FSDirectory(在文件系统存储索引)、RAMDirectory(在内存存储索引)。 采集数据的目的是为了索引,在索引前需要将原始内容创建成文档(Document),文档(Document)中包括一个一个的域(Field)。 Tokenizer是分词器,负责将reader转换为语汇单元即进行分词,Lucene提供了很多的分词器,也可以使用第三方的分词,比如IKAnalyzer一个中文分词器。 tokenFilter是分词过滤器,负责对语汇单元进行过滤,tokenFilter可以是一个过滤器链,Lucene提供了很多的分词器过滤器,比如大小写转换、去除停用词等。 如下图是语汇单元的生成过程: 从一个Reader字符流开始,创建一个基于Reader的Tokenizer分词器,经过三个TokenFilter生成语汇单元Token。 Token就是分词过程中产生的对象(包含分词的词语内容,该词在文本中的开始和结束位置)。 term 是搜索时的最小单元。 索引时使用: 输入关键字进行搜索,当需要让该关键字与文档域内容所包含的词进行匹配时需要对文档域内容进行分析,需要经过Analyzer分词器处理生成语汇单元(Token) 搜索时使用: 对搜索关键字进行分析和索引分析一样,使用Analyzer对搜索关键字进行分析、分词处理,使用分析后每个词语进行搜索,匹配。 1、用户定义查询语句,用户确定查询什么内容(输入什么关键字) 2、IndexSearcher索引搜索对象,定义了很多搜索方法,程序员调用此方法搜索。 3、IndexReader索引读取对象,它对应的索引维护对象IndexWriter,IndexSearcher通过IndexReader读取索引目录中的索引文件 4、Directory索引流对象,IndexReader需要Directory读取索引库,使用FSDirectory文件系统流对象 5、IndexSearcher搜索完成,返回一个TopDocs(匹配度高的前边的一些记录) 输入查询语句 用户输入查询关键字,执行搜索之前需要先构建一个查询对象,查询对象中可以指定查询要搜索的Field文档域、查询关键字等,查询对象会生成具体的查询语法, 例如:语法 “name:lucene”表示要搜索Field域为name内容为“lucene”的文档 通过倒排索引的方式进行查询文档。( 传统方法是先找到文件,再找内容,如何在文件中找内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大就搜索慢。 倒排索引结构是根据内容(词语)找文档,倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它是在索引中匹配搜索关键字,由于索引内容量有限并且采用固定优化算法搜索速度很快,找到了索引中的词汇,词汇与文档关联,从而最终找到了文档。 比如:name:lucene 表示要从name域中查询lucene的文档,如下图查询出文档的ID列表。 将查询的结果集进行处理,并渲染到页面,提供给用户一个友好的界面。 搜索查询过程: 第一步:创建一个Directory对象,也就是索引库存放的位置。 第二步:创建一个indexReader对象,需要指定Directory对象。 第三步:创建一个indexsearcher对象,需要指定IndexReader对象 第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。 第五步:执行查询。 第六步:返回查询结果。遍历查询结果并输出。 第七步:关闭IndexReader对象 Field是文档中的域,包括Field名和Field值两部分,一个文档可以包括多个Field,Document只是Field的一个承载体,Field值即为要索引的内容,也是要搜索的内容。 l 是否分词(tokenized),是将field的内容分成一个一个单词。分词的目的:分词目的为了索引,要分词:如: 商品的名称,商品的介绍。不分词,将内容作为一个整体存储。如:商品ID 身份证号,图片路径 l 索引(indexed) 将field的值建立索引,索引的目的:索引的目的为了搜索。建立索引:如:商品的名称,商品的介绍;不建立索引如:图片路径 l 是否存储(stored)存储的目的:(为了展示在页面) 要存储:如:商品名称,图片路径;不存储:如页面不需要展示的介绍,如果需要展示,根据ID从数据库查询展示在详情页面。 常用的几个用的Filed类型,注意Field的属性,根据需求选择: 索引的更新和删除操作 lucene 标签:数据库链接 如何 reader 简单 analysis dao google 停用 query 原文地址:http://www.cnblogs.com/jiangxiangit/p/7292075.html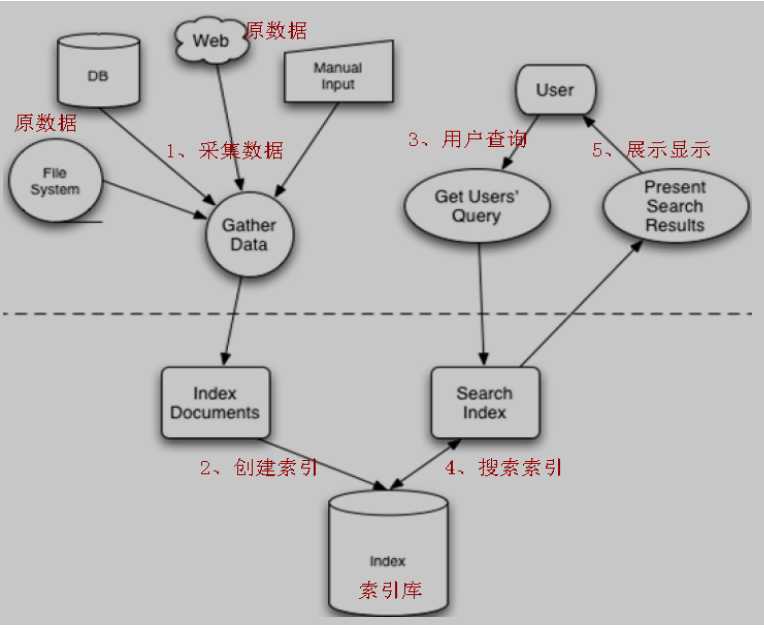
package com.lucene.pojo;
public class Book {
// 图书ID
private Integer id;
// 图书名称
private String name;
// 图书价格
private Float price;
// 图书图片
private String pic;
// 图书描述
private String description;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Float getPrice() {
return price;
}
public void setPrice(Float price) {
this.price = price;
}
public String getPic() {
return pic;
}
public void setPic(String pic) {
this.pic = pic;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
}
package com.lucene.dao;
import java.util.List;
import com.lucene.pojo.Book;
public interface BookDao {
public List
package com.lucene.dao.impl;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import com.lucene.dao.BookDao;
import com.lucene.pojo.Book;
public class BookDaoImpl implements BookDao {
@Override
public List

/**
* 收集数据,创建索引
*/
@Test
public void test() throws IOException {
IndexWriter indexWriter = null;
try {
//采集数据
BookDao dao = new BookDaoImpl();
List
执行查询
@Test
public void doInsearch() throws IOException {
//指定索引库
FSDirectory directory = FSDirectory.open(new File("E:\\upload\\lucene"));
DirectoryReader reader = IndexReader.open(directory);
//创建indexsearcher对象
IndexSearcher searcher = new IndexSearcher(reader);
//创建termquery对象
TermQuery termQuery = new TermQuery(new Term("description","项目"));
//构造中传termQuery对象 ,10表示查询分数最高的10条
TopDocs topdoc = searcher.search(termQuery, 10);
ScoreDoc[] scoreDocs = topdoc.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
int id = scoreDoc.doc;//文档的id
Document doc = searcher.doc(id);//获取doc对象
System.out.println(doc.get("id"));
System.out.println(doc.get("name"));
System.out.println(doc.get("price"));
System.out.println(doc.get("pic"));
System.out.print(doc.get("description"));
}
}
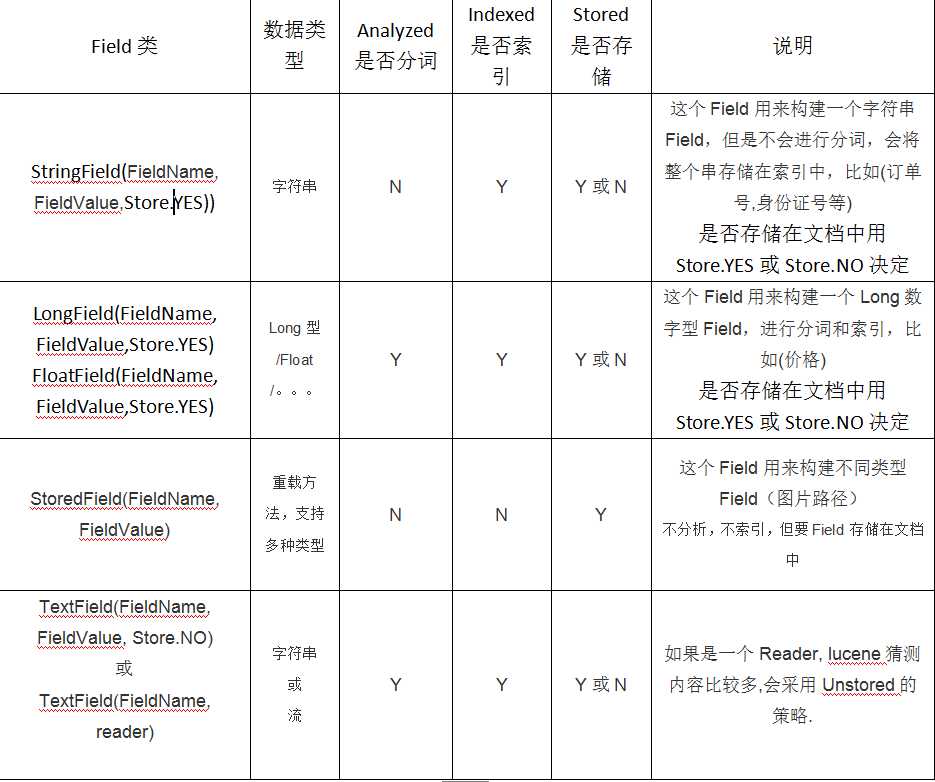
1.1 Field属性
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexableField;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer;
import java.io.File;
import java.io.IOException;
/**
* Created by Administrator on 2017/8/5.
*/
public class IndexCURD {
private IndexWriter getIndexWriter() throws IOException {
//获取索引库
FSDirectory directory = FSDirectory.open(new File("E:\\upload\\lucene"));
//创建分词器标准
// Analyzer analyzer = new StandardAnalyzer();
//创建ik分词器
Analyzer analyzer = new IKAnalyzer();
//创建indexWriterConfig
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LATEST,analyzer);
//创建indexWriter
return new IndexWriter(directory, indexWriterConfig);
}
//删除全部索引
@Test
public void deleteIndex() throws IOException {
IndexWriter indexWriter=null;
try {
//创建indexWriter
indexWriter = getIndexWriter();
//删除指定索引
indexWriter.deleteDocuments(new Term("name","java"));
}finally {
if (indexWriter!=null){
indexWriter.close();
}
}
}
//删除索引
@Test
public void deleteIndexAll() throws IOException {
IndexWriter indexWriter=null;
try {
//创建indexWriter
indexWriter =getIndexWriter();
//删除指定索引
indexWriter.deleteAll();
}finally {
if (indexWriter!=null){
indexWriter.close();
}
}
}
//修改索引
@Test
public void updateIndex() throws IOException {
IndexWriter indexWriter = getIndexWriter();
Document document=new Document();
IndexableField i=new TextField("name","apa", Field.Store.YES);
document.add(i);
indexWriter.updateDocument(new Term("name","apache"),document);
}
}