这48个Java技术点,让你的面试成功率提升5倍!
2021-07-10 15:04
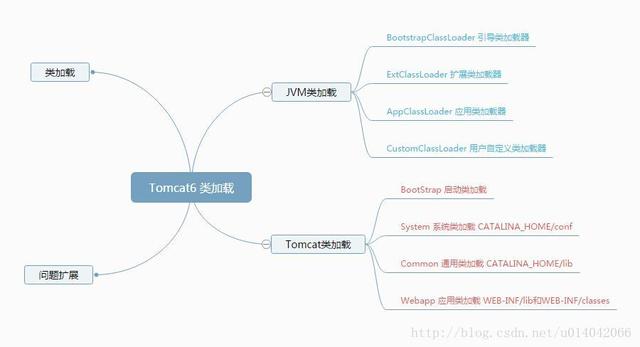
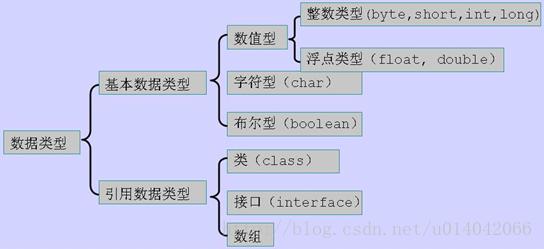
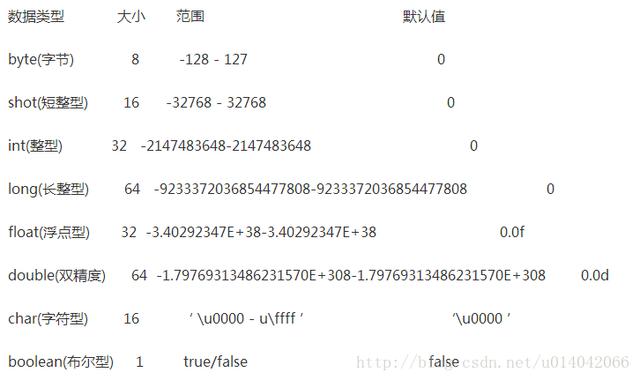
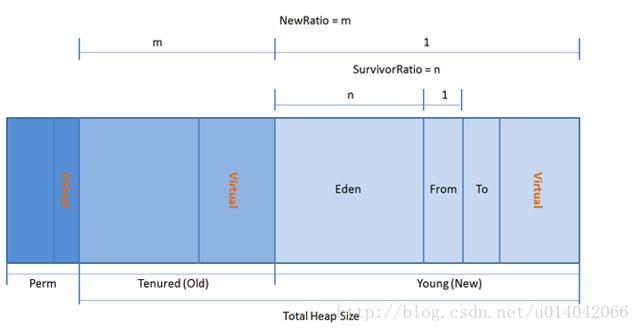
标签:html point 可见性 记录 理解 hashset 存储 zhang 永久代 JAVA中的几种基本类型,各占用多少字节? 下图单位是bit,非字节 1B=8bit String能被继承吗?为什么? 不可以,因为String类有final修饰符,而final修饰的类是不能被继承的,实现细节不允许改变。平常我们定义的String str=”a”;其实和String str=new String(“a”)还是有差异的。 前者默认调用的是String.valueOf来返回String实例对象,至于调用哪个则取决于你的赋值,比如String num=1,调用的是 public static String valueOf(int i) { return Integer.toString(i); } 后者则是调用如下部分: public String(String original) { this.value = original.value; this.hash = original.hash; } 最后我们的变量都存储在一个char数组中 private final char value[]; 也为大家推荐了技术教程: Java8零基础入门https://edu.csdn.net/course/detail/3044?utm_source=bokeyuanxk Drools7规则引擎入门教程https://edu.csdn.net/course/detail/5523?utm_source=bokeyuanxk Spring Boot开发小而美的个人博客https://edu.csdn.net/course/detail/6359?utm_source=bokeyuanxk 探究Linux的总线、设备、驱动模型https://edu.csdn.net/course/detail/5329?utm_source=bokeyuanxk 软件测试入门到精通https://edu.csdn.net/course/detail/8729?utm_source=bokeyuanxk Spring Boot 入门https://edu.csdn.net/course/detail/9068?utm_source=boekeyuanxk Java多线程+网银取款案例精讲https://edu.csdn.net/course/detail/8973?utm_source=bokeyuanxk String, Stringbuffer, StringBuilder 的区别。 String 字符串常量(final修饰,不可被继承),String是常量,当创建之后即不能更改。(可以通过StringBuffer和StringBuilder创建String对象(常用的两个字符串操作类)。) StringBuffer 字符串变量(线程安全),其也是final类别的,不允许被继承,其中的绝大多数方法都进行了同步处理,包括常用的Append方法也做了同步处理(synchronized修饰)。其自jdk1.0起就已经出现。其toString方法会进行对象缓存,以减少元素复制开销。 public synchronized String toString() { if (toStringCache == null) { toStringCache = Arrays.copyOfRange(value, 0, count); } return new String(toStringCache, true); } StringBuilder 字符串变量(非线程安全)其自jdk1.5起开始出现。与StringBuffer一样都继承和实现了同样的接口和类,方法除了没使用synch修饰以外基本一致,不同之处在于最后toString的时候,会直接返回一个新对象。 public String toString() { // Create a copy, don’t share the array return new String(value, 0, count); } ArrayList 和 LinkedList 有什么区别。 ArrayList和LinkedList都实现了List接口,有以下的不同点: 1、ArrayList是基于索引的数据接口,它的底层是数组。它可以以O(1)时间复杂度对元素进行随机访问。与此对应,LinkedList是以元素列表的形式存储它的数据,每一个元素都和它的前一个和后一个元素链接在一起,在这种情况下,查找某个元素的时间复杂度是O(n)。 2、相对于ArrayList,LinkedList的插入,添加,删除操作速度更快,因为当元素被添加到集合任意位置的时候,不需要像数组那样重新计算大小或者是更新索引。 3、LinkedList比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。 讲讲类的实例化顺序,比如父类静态数据,构造函数,字段,子类静态数据,构造函数,字段,当 new 的时候, 他们的执行顺序。 此题考察的是类加载器实例化时进行的操作步骤(加载–>连接->初始化)。 父类静态代变量、 父类静态代码块、 子类静态变量、 子类静态代码块、 父类非静态变量(父类实例成员变量)、 父类构造函数、 子类非静态变量(子类实例成员变量)、 子类构造函数。 测试demo:http://blog.csdn.net/u014042066/article/details/77574956 参阅我的博客《深入理解类加载》:http://blog.csdn.net/u014042066/article/details/77394480 用过哪些 Map 类,都有什么区别,HashMap 是线程安全的吗,并发下使用的 Map 是什么,他们内部原理分别是什么,比如存储方式, hashcode,扩容, 默认容量等。 hashMap是线程不安全的,HashMap是数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,采用哈希表来存储的, 参照该链接:https://zhuanlan.zhihu.com/p/21673805 JAVA8 的 ConcurrentHashMap 为什么放弃了分段锁,有什么问题吗,如果你来设计,你如何设计。 参照:https://yq.aliyun.com/articles/36781 有没有有顺序的 Map 实现类, 如果有, 他们是怎么保证有序的。 TreeMap和LinkedHashMap是有序的(TreeMap默认升序,LinkedHashMap则记录了插入顺序)。 参照:http://uule.iteye.com/blog/1522291 抽象类和接口的区别,类可以继承多个类么,接口可以继承多个接口么,类可以实现多个接口么。 1、抽象类和接口都不能直接实例化,如果要实例化,抽象类变量必须指向实现所有抽象方法的子类对象,接口变量必须指向实现所有接口方法的类对象。 2、抽象类要被子类继承,接口要被类实现。 3、接口只能做方法申明,抽象类中可以做方法申明,也可以做方法实现 4、接口里定义的变量只能是公共的静态的常量,抽象类中的变量是普通变量。 5、抽象类里的抽象方法必须全部被子类所实现,如果子类不能全部实现父类抽象方法,那么该子类只能是抽象类。同样,一个实现接口的时候,如不能全部实现接口方法,那么该类也只能为抽象类。 6、抽象方法只能申明,不能实现。abstract void abc();不能写成abstract void abc(){}。 7、抽象类里可以没有抽象方法 8、如果一个类里有抽象方法,那么这个类只能是抽象类 9、抽象方法要被实现,所以不能是静态的,也不能是私有的。 10、接口可继承接口,并可多继承接口,但类只能单根继承。 继承和聚合的区别在哪。 继承指的是一个类(称为子类、子接口)继承另外的一个类(称为父类、父接口)的功能,并可以增加它自己的新功能的能力,继承是类与类或者接口与接口之间最常见的关系;在Java中此类关系通过关键字extends明确标识,在设计时一般没有争议性; 聚合是关联关系的一种特例,他体现的是整体与部分、拥有的关系,即has-a的关系,此时整体与部分之间是可分离的,他们可以具有各自的生命周期,部分可以属于多个整体对象,也可以为多个整体对象共享;比如计算机与CPU、公司与员工的关系等;表现在代码层面,和关联关系是一致的,只能从语义级别来区分; 参考:http://www.cnblogs.com/jiqing9006/p/5915023.html 讲讲你理解的 nio和 bio 的区别是啥,谈谈 reactor 模型。 IO是面向流的,NIO是面向缓冲区的 参考:https://zhuanlan.zhihu.com/p/23488863 http://developer.51cto.com/art/201103/252367.htm http://www.jianshu.com/p/3f703d3d804c 反射的原理,反射创建类实例的三种方式是什么 参照:http://www.jianshu.com/p/3ea4a6b57f87?amp http://blog.csdn.net/yongjian1092/article/details/7364451 反射中,Class.forName 和 ClassLoader 区别。 https://my.oschina.net/gpzhang/blog/486743 描述动态代理的几种实现方式,分别说出相应的优缺点。 Jdk cglib jdk底层是利用反射机制,需要基于接口方式,这是由于 Proxy.newProxyInstance(target.getClass().getClassLoader(), target.getClass().getInterfaces(), this); Cglib则是基于asm框架,实现了无反射机制进行代理,利用空间来换取了时间,代理效率高于jdk http://lrd.ele.me/2017/01/09/dynamic_proxy/ 动态代理与 cglib 实现的区别 同上(基于invocationHandler和methodInterceptor) 为什么 CGlib 方式可以对接口实现代理。 同上 final 的用途 类、变量、方法 http://www.importnew.com/7553.html 写出三种单例模式实现。 懒汉式单例,饿汉式单例,双重检查等 参考:https://my.oschina.net/dyyweb/blog/609021 如何在父类中为子类自动完成所有的 hashcode 和 equals 实现?这么做有何优劣。 同时复写hashcode和equals方法,优势可以添加自定义逻辑,且不必调用超类的实现。 参照:http://java-min.iteye.com/blog/1416727 请结合 OO 设计理念,谈谈访问修饰符 public、private、protected、default 在应用设计中的作用。 访问修饰符,主要标示修饰块的作用域,方便隔离防护 同一个类 同一个包 不同包的子类 不同包的非子类 Private √ Default √ √ Protected √ √ √ Public √ √ √ √ public: Java语言中访问限制最宽的修饰符,一般称之为“公共的”。被其修饰的类、属性以及方法不 仅可以跨类访问,而且允许跨包(package)访问。 private: Java语言中对访问权限限制的最窄的修饰符,一般称之为“私有的”。被其修饰的类、属性以 及方法只能被该类的对象访问,其子类不能访问,更不能允许跨包访问。 protect: 介于public 和 private 之间的一种访问修饰符,一般称之为“保护形”。被其修饰的类、 属性以及方法只能被类本身的方法及子类访问,即使子类在不同的包中也可以访问。 default:即不加任何访问修饰符,通常称为“默认访问模式“。该模式下,只允许在同一个包中进行访 问。 深拷贝和浅拷贝区别。 http://www.oschina.net/translate/java-copy-shallow-vs-deep-in-which-you-will-swim 数组和链表数据结构描述,各自的时间复杂度 http://blog.csdn.net/snow_wu/article/details/53172721 error 和 exception 的区别,CheckedException,RuntimeException 的区别 http://blog.csdn.net/woshixuye/article/details/8230407 请列出 5 个运行时异常。 同上 在自己的代码中,如果创建一个 java.lang.String 对象,这个对象是否可以被类加载器加载?为什么 类加载无须等到“首次使用该类”时加载,jvm允许预加载某些类。。。。 http://www.cnblogs.com/jasonstorm/p/5663864.html 说一说你对 java.lang.Object 对象中 hashCode 和 equals 方法的理解。在什么场景下需要重新实现这两个方法。 参考上边试题 在 jdk1.5 中,引入了泛型,泛型的存在是用来解决什么问题。 泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数,泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,以提高代码的重用率 http://baike.baidu.com/item/java%E6%B3%9B%E5%9E%8B 这样的 a.hashcode() 有什么用,与 a.equals(b)有什么关系。 hashcode hashcode()方法提供了对象的hashCode值,是一个native方法,返回的默认值与System.identityHashCode(obj)一致。 通常这个值是对象头部的一部分二进制位组成的数字,具有一定的标识对象的意义存在,但绝不定于地址。 作用是:用一个数字来标识对象。比如在HashMap、HashSet等类似的集合类中,如果用某个对象本身作为Key,即要基于这个对象实现Hash的写入和查找,那么对象本身如何实现这个呢?就是基于hashcode这样一个数字来完成的,只有数字才能完成计算和对比操作。 hashcode是否唯一 hashcode只能说是标识对象,在hash算法中可以将对象相对离散开,这样就可以在查找数据的时候根据这个key快速缩小数据的范围,但hashcode不一定是唯一的,所以hash算法中定位到具体的链表后,需要循环链表,然后通过equals方法来对比Key是否是一样的。 equals与hashcode的关系 equals相等两个对象,则hashcode一定要相等。但是hashcode相等的两个对象不一定equals相等。 https://segmentfault.com/a/1190000004520827 有没有可能 2 个不相等的对象有相同的 hashcode。 有 Java 中的 HashSet 内部是如何工作的。 底层是基于hashmap实现的 http://wiki.jikexueyuan.com/project/java-collection/hashset.html 什么是序列化,怎么序列化,为什么序列化,反序列化会遇到什么问题,如何解决。 http://www.importnew.com/17964.html 什么情况下会发生栈内存溢出。 如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常。 如果虚拟机在动态扩展栈时无法申请到足够的内存空间,则抛出OutOfMemoryError异常。 参照:http://wiki.jikexueyuan.com/project/java-vm/storage.html JVM 的内存结构,Eden 和 Survivor 比例。 eden 和 survior 是按8比1分配的 http://blog.csdn.net/lojze_ly/article/details/49456255 jvm 中一次完整的 GC 流程是怎样的,对象如何晋升到老年代,说说你知道的几种主要的jvm 参数。 对象诞生即新生代->eden,在进行minor gc过程中,如果依旧存活,移动到from,变成Survivor,进行标记代数,如此检查一定次数后,晋升为老年代, http://www.cnblogs.com/redcreen/archive/2011/05/04/2037056.html http://ifeve.com/useful-jvm-flags/ https://wangkang007.gitbooks.io/jvm/content/jvmcan_shu_xiang_jie.html 你知道哪几种垃圾收集器,各自的优缺点,重点讲下 cms,包括原理,流程,优缺点 Serial、parNew、ParallelScavenge、SerialOld、ParallelOld、CMS、G1 https://wangkang007.gitbooks.io/jvm/content/chapter1.html 垃圾回收算法的实现原理。 http://www.importnew.com/13493.html 当出现了内存溢出,你怎么排错。 首先分析是什么类型的内存溢出,对应的调整参数或者优化代码。 https://wangkang007.gitbooks.io/jvm/content/4jvmdiao_you.html JVM 内存模型的相关知识了解多少,比如重排序,内存屏障,happen-before,主内存,工作内存等。 内存屏障:为了保障执行顺序和可见性的一条cpu指令 重排序:为了提高性能,编译器和处理器会对执行进行重拍 happen-before:操作间执行的顺序关系。有些操作先发生。 主内存:共享变量存储的区域即是主内存 工作内存:每个线程copy的本地内存,存储了该线程以读/写共享变量的副本 http://ifeve.com/java-memory-model-1/ http://www.jianshu.com/p/d3fda02d4cae http://blog.csdn.net/kenzyq/article/details/50918457 简单说说你了解的类加载器。 类加载器的分类(bootstrap,ext,app,curstom),类加载的流程(load-link-init) http://blog.csdn.net/gjanyanlig/article/details/6818655/ 讲讲 JAVA 的反射机制。 Java程序在运行状态可以动态的获取类的所有属性和方法,并实例化该类,调用方法的功能 http://baike.baidu.com/link?url=C7p1PeLa3ploAgkfAOK-4XHE8HzQuOAB7K5GPcK_zpbAa_Aw-nO3997K1oir8N–1_wxXZfOThFrEcA0LjVP6wNOwidVTkLBzKlQVK6JvXYvVNhDWV9yF-NIOebtg1hwsnagsjUhOE2wxmiup20RRa#7 你们线上应用的 JVM 参数有哪些。 -server Xms6000M -Xmx6000M -Xmn500M -XX:PermSize=500M -XX:MaxPermSize=500M -XX:SurvivorRatio=65536 -XX:MaxTenuringThreshold=0 -Xnoclassgc -XX:+DisableExplicitGC -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:-CMSParallelRemarkEnabled -XX:CMSInitiatingOccupancyFraction=90 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+PrintClassHistogram -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -Xloggc:log/gc.log g1 和 cms 区别,吞吐量优先和响应优先的垃圾收集器选择。 Cms是以获取最短回收停顿时间为目标的收集器。基于标记-清除算法实现。比较占用cpu资源,切易造成碎片。 G1是面向服务端的垃圾收集器,是jdk9默认的收集器,基于标记-整理算法实现。可利用多核、多cpu,保留分代,实现可预测停顿,可控。 http://blog.csdn.net/linhu007/article/details/48897597 请解释如下 jvm 参数的含义: -server -Xms512m -Xmx512m -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -XX:MaxTenuringThreshold=20 XX:CMSInitiatingOccupancyFraction=80 -XX:+UseCMSInitiatingOccupancyOnly。 Server模式启动 最小堆内存512m 最大512m 每个线程栈空间1m 永久代256 最大永久代256 最大转为老年代检查次数20 Cms回收开启时机:内存占用80% 命令JVM不基于运行时收集的数据来启动CMS垃圾收集周期 简单讲讲 tomcat 结构,以及其类加载器流程。 Server- –多个service Container级别的:–>engine–》host–>context Listenter Connector Logging、Naming、Session、JMX等等 通过WebappClassLoader 加载class http://www.ibm.com/developerworks/cn/java/j-lo-tomcat1/ http://blog.csdn.net/dc_726/article/details/11873343 http://www.cnblogs.com/xing901022/p/4574961.html http://www.jianshu.com/p/62ec977996df tomcat 如何调优,涉及哪些参数。 硬件上选择,操作系统选择,版本选择,jdk选择,配置jvm参数,配置connector的线程数量,开启gzip压缩,trimSpaces,集群等 http://blog.csdn.net/lifetragedy/article/details/7708724 讲讲 Spring 加载流程。 通过listener入口,核心是在AbstractApplicationContext的refresh方法,在此处进行装载bean工厂,bean,创建bean实例,拦截器,后置处理器等。 https://www.ibm.com/developerworks/cn/java/j-lo-spring-principle/ 讲讲 Spring 事务的传播属性。 七种传播属性。 事务传播行为 所谓事务的传播行为是指,如果在开始当前事务之前,一个事务上下文已经存在,此时有若干选项可以指定一个事务性方法的执行行为。在TransactionDefinition定义中包括了如下几个表示传播行为的常量: TransactionDefinition.PROPAGATION_REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。 TransactionDefinition.PROPAGATION_REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起。 TransactionDefinition.PROPAGATION_SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。 TransactionDefinition.PROPAGATION_NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。 TransactionDefinition.PROPAGATION_NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。 TransactionDefinition.PROPAGATION_MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。 TransactionDefinition.PROPAGATION_NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。 https://www.ibm.com/developerworks/cn/education/opensource/os-cn-spring-trans/ Spring 如何管理事务的。 编程式和声明式 同上 Spring 怎么配置事务(具体说出一些关键的 xml 元素)。 说说你对 Spring 的理解,非单例注入的原理?它的生命周期?循环注入的原理, aop 的实现原理,说说 aop 中的几个术语,它们是怎么相互工作的。 核心组件:bean,context,core,单例注入是通过单例beanFactory进行创建,生命周期是在创建的时候通过接口实现开启,循环注入是通过后置处理器,aop其实就是通过反射进行动态代理,pointcut,advice等。 Aop相关:http://blog.csdn.net/csh624366188/article/details/7651702/ Springmvc 中 DispatcherServlet 初始化过程。 入口是web.xml中配置的ds,ds继承了HttpServletBean,FrameworkServlet,通过其中的init方法进行初始化装载bean和实例,initServletBean是实际完成上下文工作和bean初始化的方法。 http://www.soscw.com/info-detail-512105.html 这48个Java技术点,让你的面试成功率提升5倍! 标签:html point 可见性 记录 理解 hashset 存储 zhang 永久代 原文地址:https://www.cnblogs.com/ndsc2018/p/9561326.htmlJAVA基础 (文末有彩蛋)

JVM 知识
开源框架知识