Python构建web应用(进阶版)->对网页HTML优化逻辑显示
2021-07-13 19:04
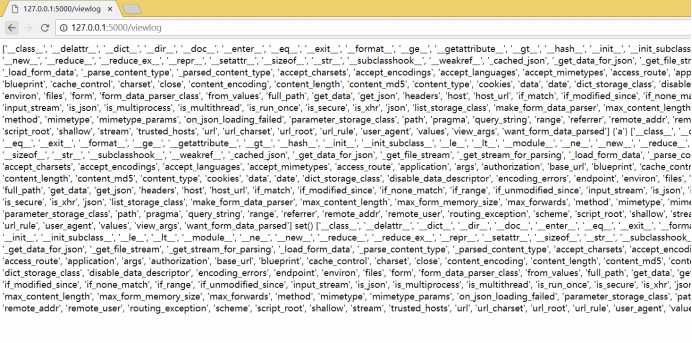
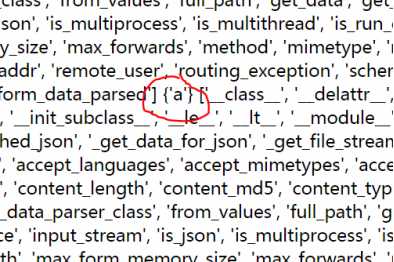
标签:soscw data 进制 bsp 几句话 重要 属性 特定 python 本篇是承接上一篇web应用(入门级)的内容往下顺延的,阅读后将会了解HTML逻辑显示优化,如下图所示,从杂乱无章的日志文件到一个整齐的列表显示。 —————————————————————————— 我是分割线 ————————————————————————————————— 在下面的内容之前需要了解存储和管理数据的知识。 关于web应用,应该记录每个web请求的数据。这样有利于分析这些问题: 已经响应了多少个请求?最常用的字母列表是什么?请求来自哪个IP地址?哪个浏览器用的最多?…… 1.建立一个txt空文件(hh.txt),指定一个变量(a)打开这个文件,后面参数‘a’的含义是采用追加模式打开这个文件。open会返回一个流,赋值给a变量 2.然后打印消息到文件流。 3.完成工作,最后关闭,文件流进行清理。 4.读是open的默认模式,所以不需要提供模式参数,打开文件时仍需要指定一个变量(read),然后open会返回一个文件流赋给read变量。 5.for循环每次循环读取一个数据行,没有数据行即终止。 6.工作完成,关闭文件流进行清理。 访问模式:(r w主要针对文本文件) 访问模式 说明 r 以只读方式打开文件,文件的指针会放在文件的开头。(默认模式) w 以可写方式打开文件,文件存在时:覆盖,不存在时:创建新文件。 a 以追加方式打开文件,文件存在:指针放在文件结尾,不存在时:创建新文件进行写入。 rb 以二进制格式打开一个文件用于只读。 wb 以可读方式打开二进制文件。 ab 以追加方式打开二进制文件。 r+ 打开一个文件用于读写,文件指针在开头。 rb+ wb+ 以二进制格式打开一个文件用于只读。 ab+ x 打开一个新文件进行写数据,如果文件存在则失败。 上表没有写全,规律:r--read; w--write; a--add to; b--binary; + --读写 这样可以完成和之前的open相同的操作,并且后面不用close()关闭文件。这些内容是在Python内部有一个上下文管理协议,它完成收尾的工作,在需要时调用close。 之前提到的程序可以在添加内容了,我们想对这个web应用的数据进行存储记录下来。 回顾之前的程序内容: 在下面添加一个函数 调用这个函数时,req参数作为当前的flask请求对象,res参数作为调用vsearch_for_letters函数的结果.然后函数log_request把req和res的值追加到一个名为vsearch.log的文件。 使用这个函数时,我们添加到上面的do_search中进行调用,当然在调用之前需要定义函数,所以调整位置后的程序如下: 保存后在webapp文件夹中运行cmd,输入python vsearch_for_web.py 然后打开浏览器输入地址http://127.0.0.1:5000进行测试,试过几次之后会发现生成了一个log文件 下来让日志显示在web浏览器里,所以新建一个URL: /viewlog 在最后面添加代码: 保存测试后键入http://127.0.0.1:5000/viewlog看到: 这些好像只是浏览器接受和显示最后的结果,并没有最开始搜索的内容,检查网页的源代码,直接浏览器中右键 这些内容和刚才的并没有太大差别,还是没有看到搜索的内容,web拒绝显示用户搜索的数据,因为HTML中 Flask包含一个escape函数,调用时提供一个字符串,其中不包含任何特殊字符: 对一些包含特殊字符的字符串使用这个函数,它会将转义为<和> 在第一行调用加入escape然后在后面的return后使用函数:escape(contents) 新的测试结果: 注意到刚才是红色的字变成了黑色字,,不过这些数字并不能看出来什么。 更改代码: 只在最后的print做了修改,把req的内容通过dir()列出然后转成字符输出。 下来测试新的日志记录代码,先完成下列步骤: 仔细看看现在的内容,有意义了吗? 这似乎有些乱,不过仔细看会发现有一些我们查找到的值。 现在可以看到每个请求都有大量的关联方法和属性,记录所有的属性是没有意义的。其中有三个对于日志记录很重要: 下面对代码进行进一步的调整。 分别输出这些内容,end=‘|’表示把默认的换行符替换为|,这样一个请求的数据就是一行内容。 这是新的日志文件的内容:可以看到数据都在一行而且整齐了很多 上文中的连续四个print好像有些多余,其实可以缩减到一个print语句中,有一个可选的参数sep,它可以设置分隔符,默认为空格。 下来改进那几行print代码: 继续刚才那五个步骤,就是重新测试的步骤。提示:存代码、删日志、新键入。 然后查看URL:/viewlog会发现少了很多 可以找到里面有搜索的字符串也有结果,看来已经有意义了。可是如何更加规范这些内容呢? 下面是vsearch.log文件中的一个数据行: ImmutableMultiDict([(‘phrase‘, ‘this is s test of the posting capability‘), (‘letters‘, ‘aeiou‘)])|127.0.0.1|Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36|{‘o‘, ‘a‘, ‘e‘, ‘i‘} 三个|分割了四部分内容,第一部分是表单数据。第二部分是远程机器的IP地址。第三部分是web浏览器的标识字符串。最后一部分是函数调用的结果。 下来在>>>中进行测试: join前面的‘|’意思是使用|将每个字符串连接起来。 使用给定的|,将字符串分割成一个列表。 修改代码: 使用文件打开的open命令,用|将日志中的记录转换成一个列表,这样会看起来更加美观,可读性强。 需要修改的是view_the_log函数。 有一些地方需要解释: 也许你会对contents[-1].append(escape(item))有疑问,理解这行代码技巧从内向外、从左向右读。首先是外围for循环的item开始,它会传递到escape,在用append将得到的字符串追加到contents末尾 ( [-1] ) 。contents是一个嵌套列表。 保存代码然后进行测试: 现在的输出变成了一个嵌套列表,而不再是一个字符串列表。现在我们使用一个设计的jinja2模板处理contents,就基本能得到所需的可读的输出了。 HTML提供了一组标记来定义表格的内容:包括 每个标记都有对应的一个结束标记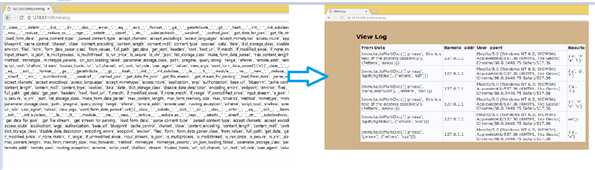
6存储和管理数据
打开、处理(process)和关闭文件
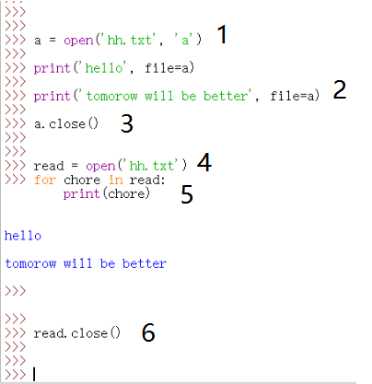
使用with对文件操作
with open(‘hh.txt‘) as a:
for chore in a:
print(chore, end = ‘ ‘)
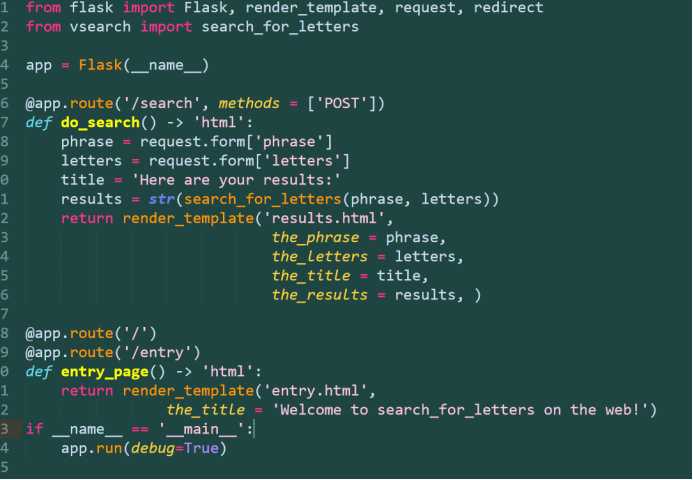
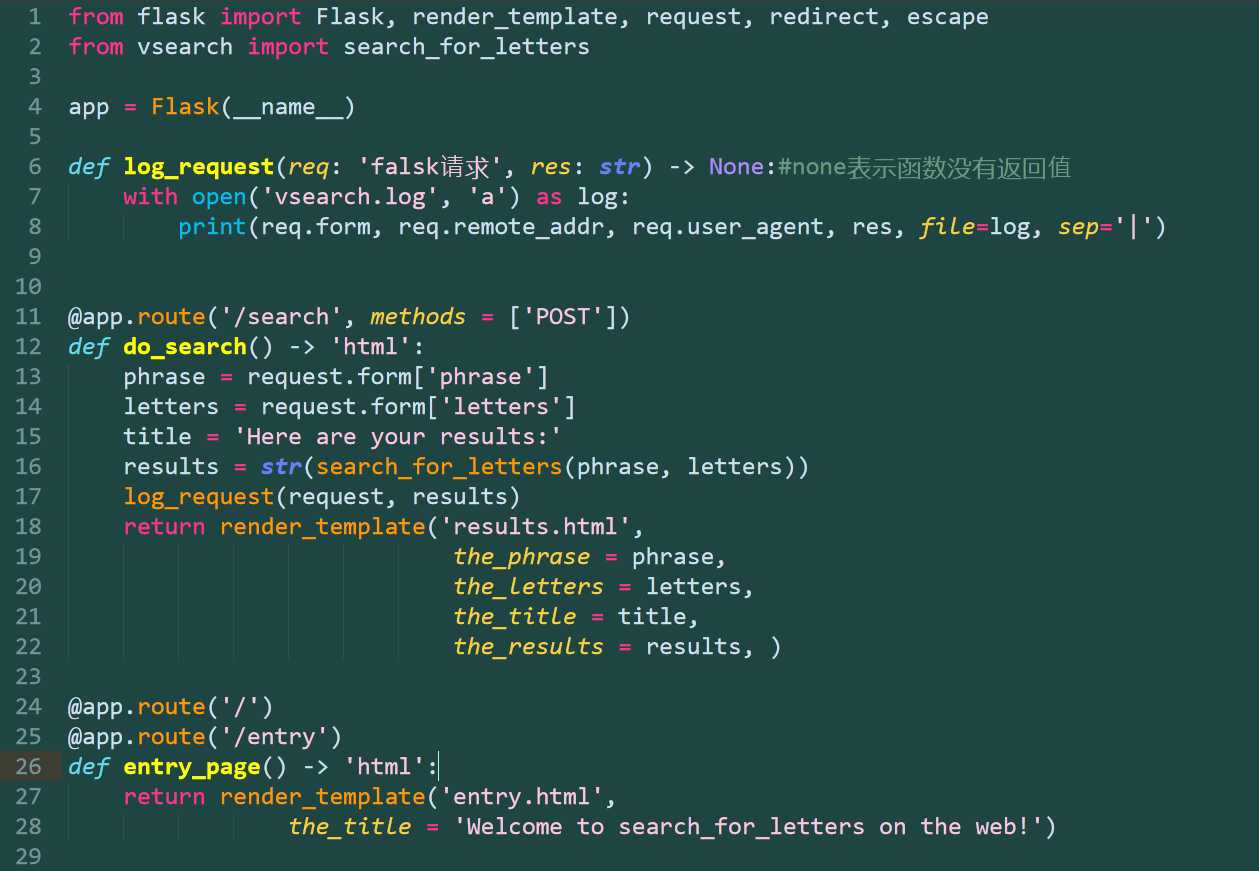
def log_request(req: ‘flask_request‘, res: str) -> None:
with open(‘vsearch.log‘, ‘a‘) as log:
print(req, res, file=log)
通过web应用查看日志
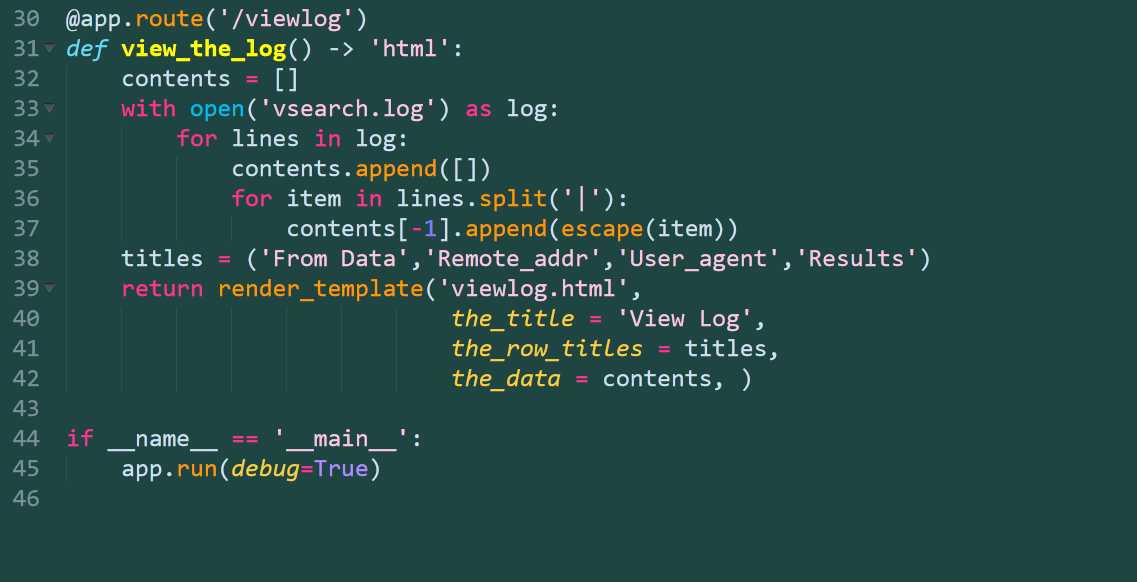
@app.route(‘/viewlog‘)
def view_the_log() -> str:
with open(‘vsearch.log‘) as log:
contents = log.read()
return contents
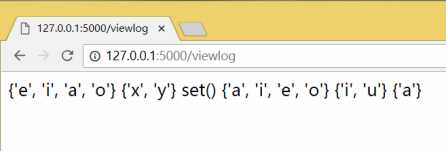
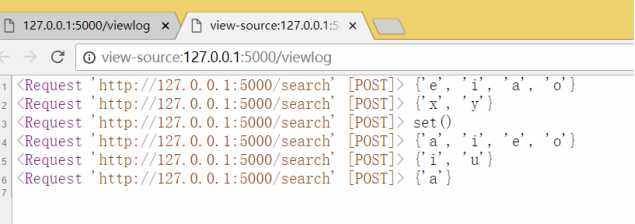
转义数据

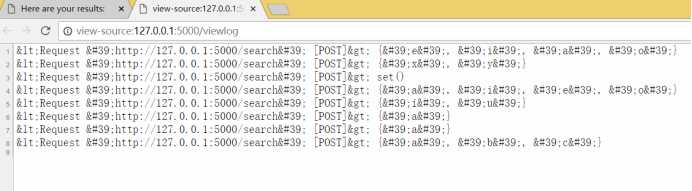

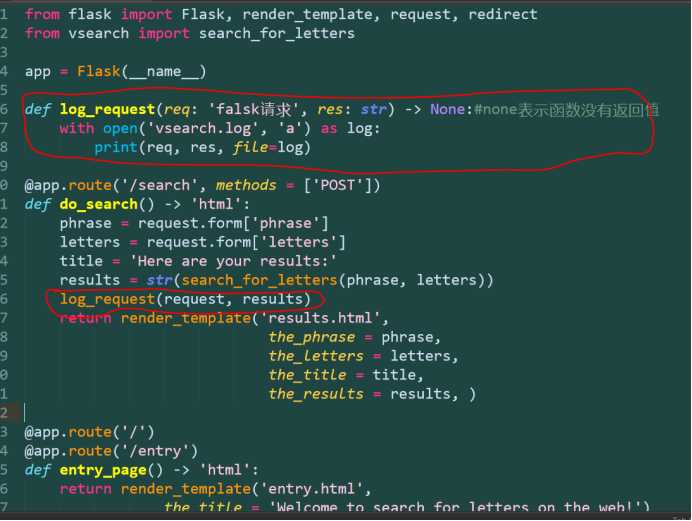
记录特定的web请求属性
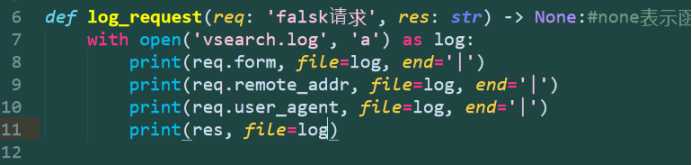

def log_request(req: ‘falsk请求‘, res: str) -> None:
with open(‘vsearch.log‘, ‘a‘) as log:
print(req.form, req.remote_addr, req.user_agent, res, file=log, sep=‘|‘)
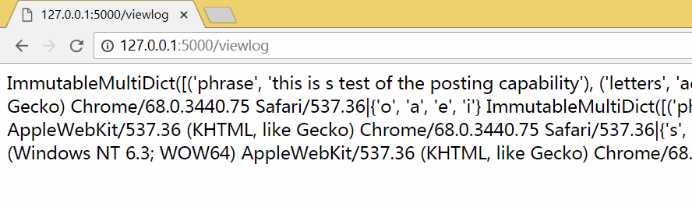
从原始数据到可读的输出


def view_the_log() -> str:
contents = []
with open(‘vsearch.log‘) as log:
for lines in log:
contents.append([])
for item in lines.split(‘|‘):
contents[-1].append(escape(item))
return escape(contents)
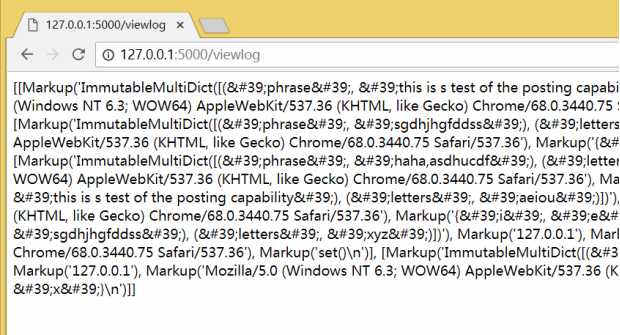
用HTML生成可读的输出
:一个表格,
,,和:一行表格数据,
:一个表格列标题和
:一个表格数据项(单元格)。
如果发现需要生成HTML,就应该使用jinja2模板引擎,它主要是设计用来生成HTML,这个引擎包含一些基本的编程构造,可以用来“自动实现”需要的显示逻辑。
下面是一个新模板下载的地址还是之前的http://python.itcarlow.ie/ed2/,名为viewlog.html,它可以将日志文件中的原始数据转换成一个HTML表格,这个模板希望传入contents嵌套列表作为他的参数。jinja2的for循环构造与Python类似,但需要注意的是行尾不需要冒号,因为%}相当于一个分隔符;每个循环的代码组用{% endfor %}结束。
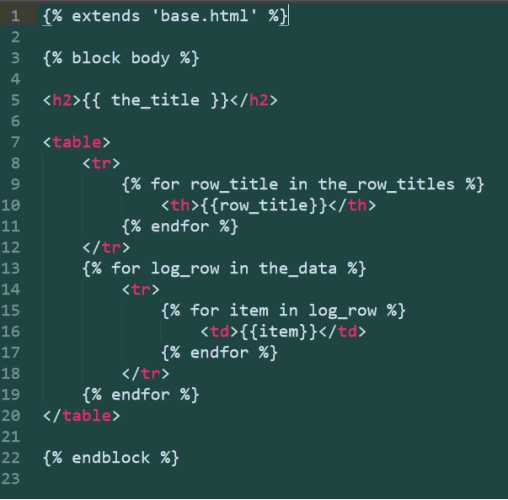
可以看到,第一个for循环希望在一个名为the_row_titles的变量中查找数据,而第二个for循环希望得到the_data中的数据。第三个for循环希望数据是一个数据项列表。
整个表在一个 这个模板需要放在templates文件夹下面。 要让viewlog.html调用render_template(render_template的函数,如果指定一个模板名和所需的参数,调用这个函数时会返回一个HTML串。),为它需要的三个参数分别传入值。下面创建一个描述性的标题元组,并把它赋值给the_row_titles,然后将contents的值赋给the_data。在呈现这个模板之前,还需要给the_title提供一个适当的值,修改函数view_the_log: 保存后是flask重启web应用,然后进入http://127.0.0.1:5000/viewlog查看日志: 我对这个结果很满意,因为终于得到了想要的输出,并且看起来很整齐。 点击右键查看网页源代码,会看到日志的每一个数据项都放在它自己的 后面的放大来看: 大体上可以看出来一些,现在对于网页的源代码好像有一些眉目了。 回顾整个代码: 对网页HTML优化逻辑显示,soscw.com" target="_blank">Python构建web应用(进阶版)->对网页HTML优化逻辑显示 标签:soscw data 进制 bsp 几句话 重要 属性 特定 python 原文地址:https://www.cnblogs.com/sebastiane-root/p/9541705.html标记中,描述性标题
中有单独的行
标记。每个日志数据项放在一个
标记中,日志文件中的各行有单独的
标记。(现在可能有些困难,不过后面就会理解这几句话的含义)
def view_the_log() -> ‘html‘:
contents = []
with open(‘vsearch.log‘) as log:
for lines in log:
contents.append([])
for item in lines.split(‘|‘):
contents[-1].append(escape(item))
titles = (‘From Data‘,‘Remote_addr‘,‘User_agent‘,‘Results‘)
return render_template(‘viewlog.html‘,
the_title = ‘View Log‘,
the_row_titles = titles,
the_data = contents,)
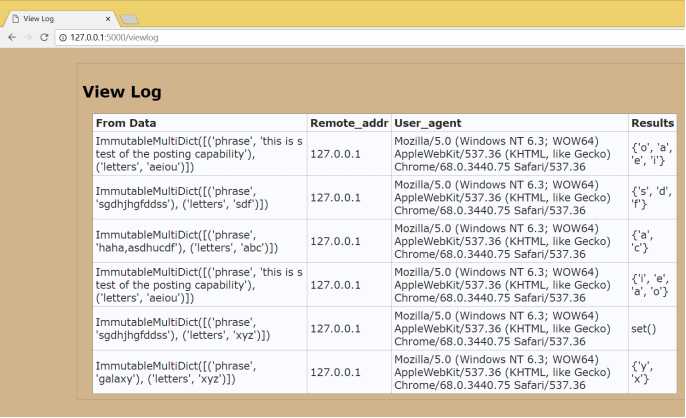
标记中,每个数据行也有自己的
标记,整个表放在一个HTML的
中。


上一篇:百度地图API 自定义标注图标
下一篇:JAVA 线程池
文章标题:Python构建web应用(进阶版)->对网页HTML优化逻辑显示
文章链接:http://soscw.com/essay/104752.html