Spark 学习笔记之 Streaming Window
2021-07-19 16:25
标签:obj res gpo print mina rdd ons object log Streaming Window: 上图意思:每隔2秒统计前3秒的数据 slideDuration: 2 windowDuration: 3 例子: 运行结果: Spark 学习笔记之 Streaming Window 标签:obj res gpo print mina rdd ons object log 原文地址:http://www.cnblogs.com/AK47Sonic/p/8052451.html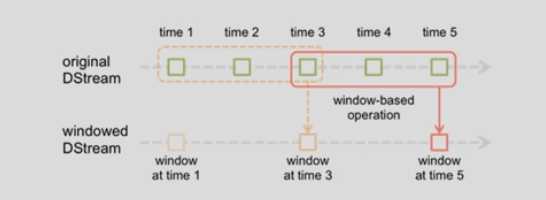
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
object WindowStreaming {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("KafkaDirect").setMaster("local[1]")
val ssc = new StreamingContext(conf, Seconds(1))
val kafkaMapParams = Map[String, Object](
"bootstrap.servers" -> "192.168.1.151:9092,192.168.1.152:9092,192.168.1.153:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "g1",
"auto.offset.reset" -> "latest", //earliest|latest
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topicsSet = Set("ScalaTopic")
val kafkaStream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topicsSet, kafkaMapParams)
)
val finalResultRDD: DStream[(Int, String)] = kafkaStream.flatMap(row => row.value().split(" "))
.map((_, 1)).reduceByKeyAndWindow((x: Int, y: Int) => x + y, Seconds(3), Seconds(2))
.transform(rdd => rdd.map(tuple => (tuple._2, tuple._1))
.sortByKey(false).map(tuple => (tuple._1, tuple._2))
)
finalResultRDD.print()
ssc.start()
ssc.awaitTermination()
}
}

文章标题:Spark 学习笔记之 Streaming Window
文章链接:http://soscw.com/essay/106343.html