【Spark MLlib速成宝典】基础篇01Windows下spark开发环境搭建(Scala版)
2021-07-19 23:15
目录
安装jdk
安装Scala IDE for Eclipse
配置Spark
配置Hadoop
创建Maven工程
Scala代码
条目7
条目8
条目9
|
安装jdk |
要求安装jdk1.8或以上版本。
返回目录
|
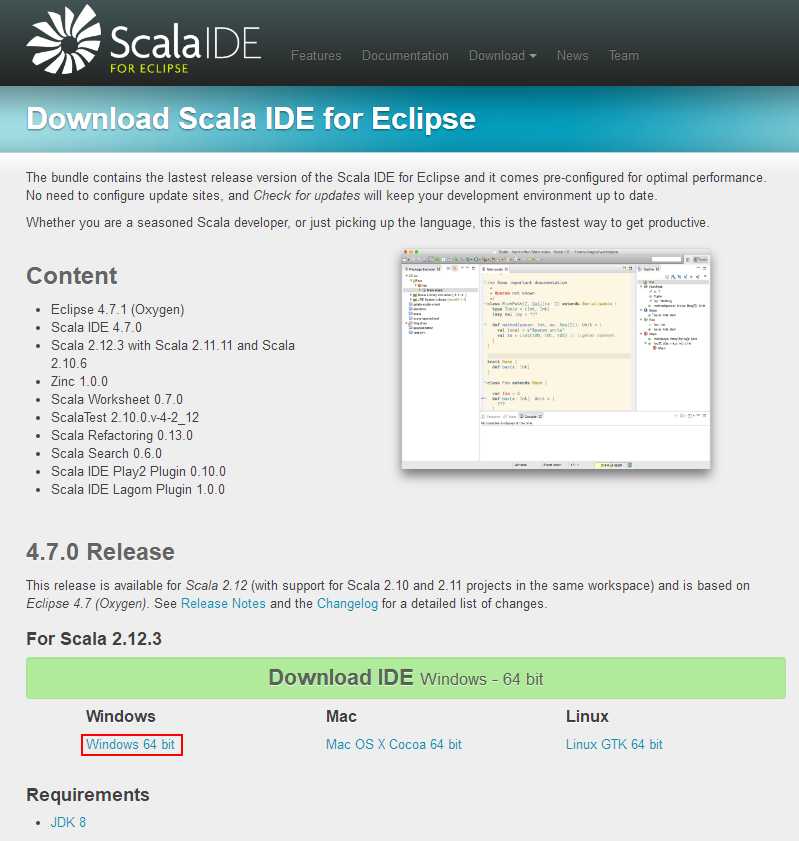
安装Scala IDE for Eclipse |
无需额外安装scala,这个IDE里面已经集成了。
官方下载:http://scala-ide.org/download/sdk.html
返回目录
|
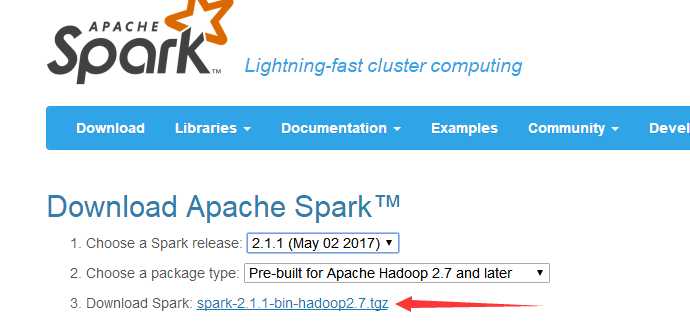
配置Spark |
下载Spark,我下载的版本如图所示
官方下载:http://spark.apache.org/downloads.html
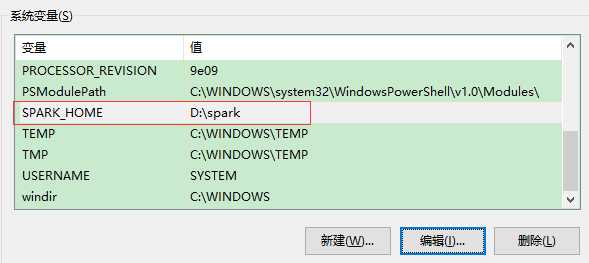
配置环境变量
变量名:SPARK_HOME 变量值:D:\spark (不能有空格)
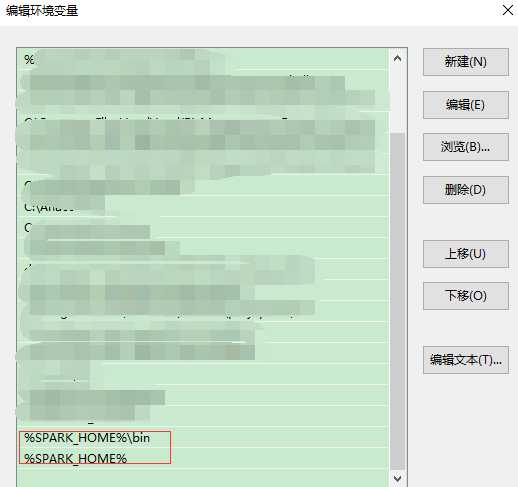
添加到Path
安装pyspark包:
命令行执行:pip install pyspark
返回目录
|
配置Hadoop |
无需安装完整的Hadoop,但需要hadoop.dll,winutils.exe等文件。根据下载的Spark版本,下载相应版本的hadoop2.7.1。
链接:https://pan.baidu.com/s/1jHRu9oE 密码:wdf9
配置环境变量
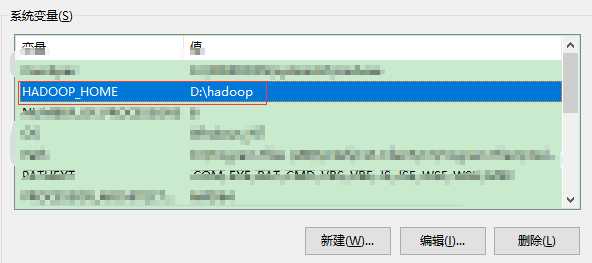
添加到Path

重启计算机!!!环境变量才生效!!!
返回目录
|
创建Maven工程 |
创建Maven工程可以快速引入项目需要的jar包。pom.xml文件里包含了一些重要的配置信息。这里提供一个可用的Maven工程:
链接:https://pan.baidu.com/s/1hsLAcWc 密码:nfta
导入Maven工程:
可以先将我提供的工程拷贝到workspace,然后引入
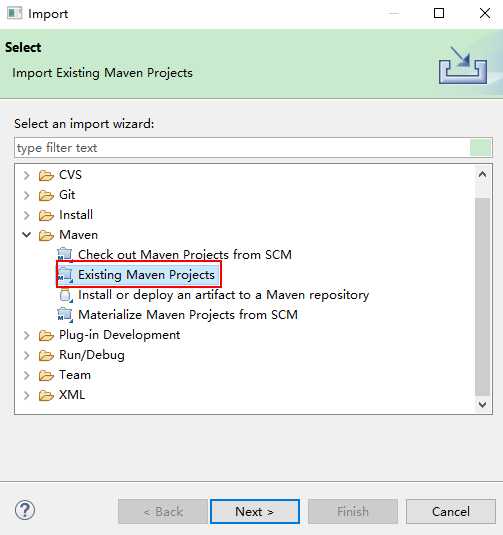
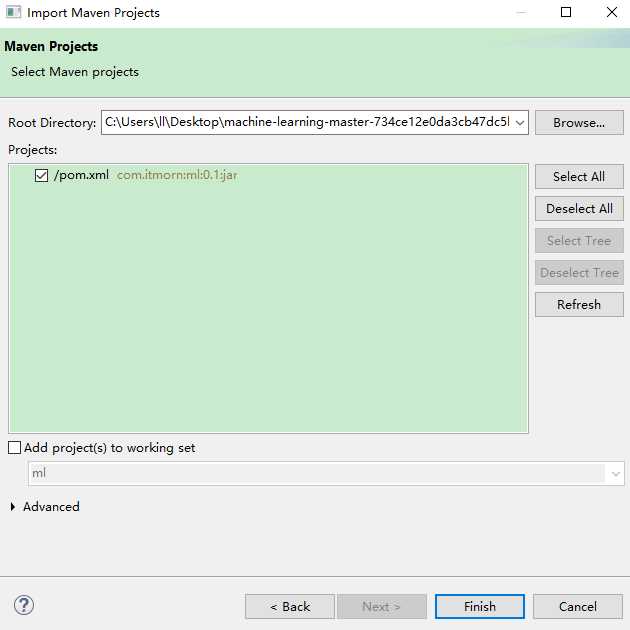
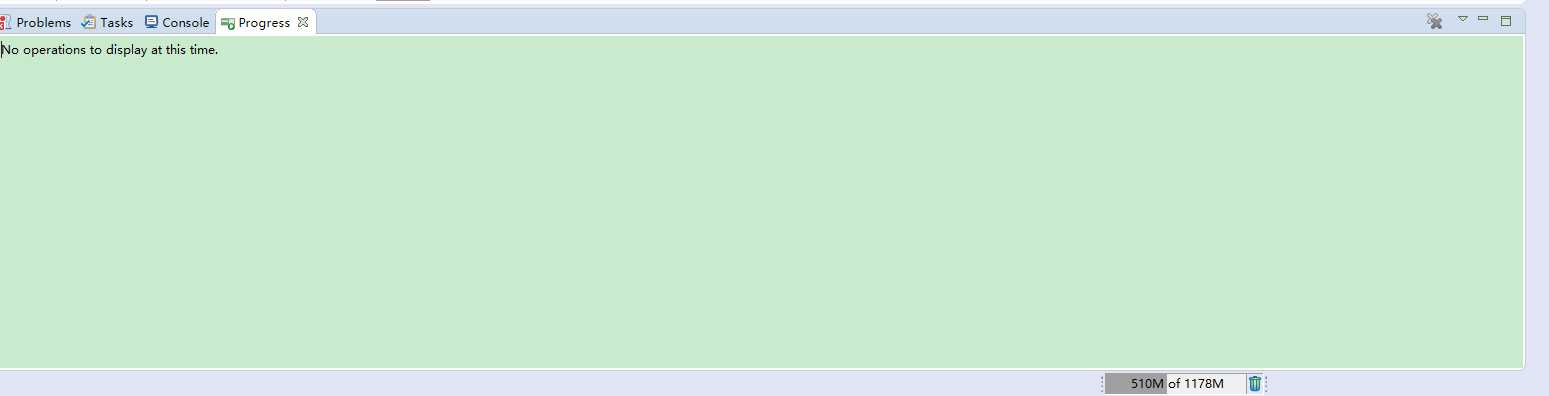
引入后,会自动下载一些jar包,需要等待几分钟

下图说明jar包下载完毕
报错:
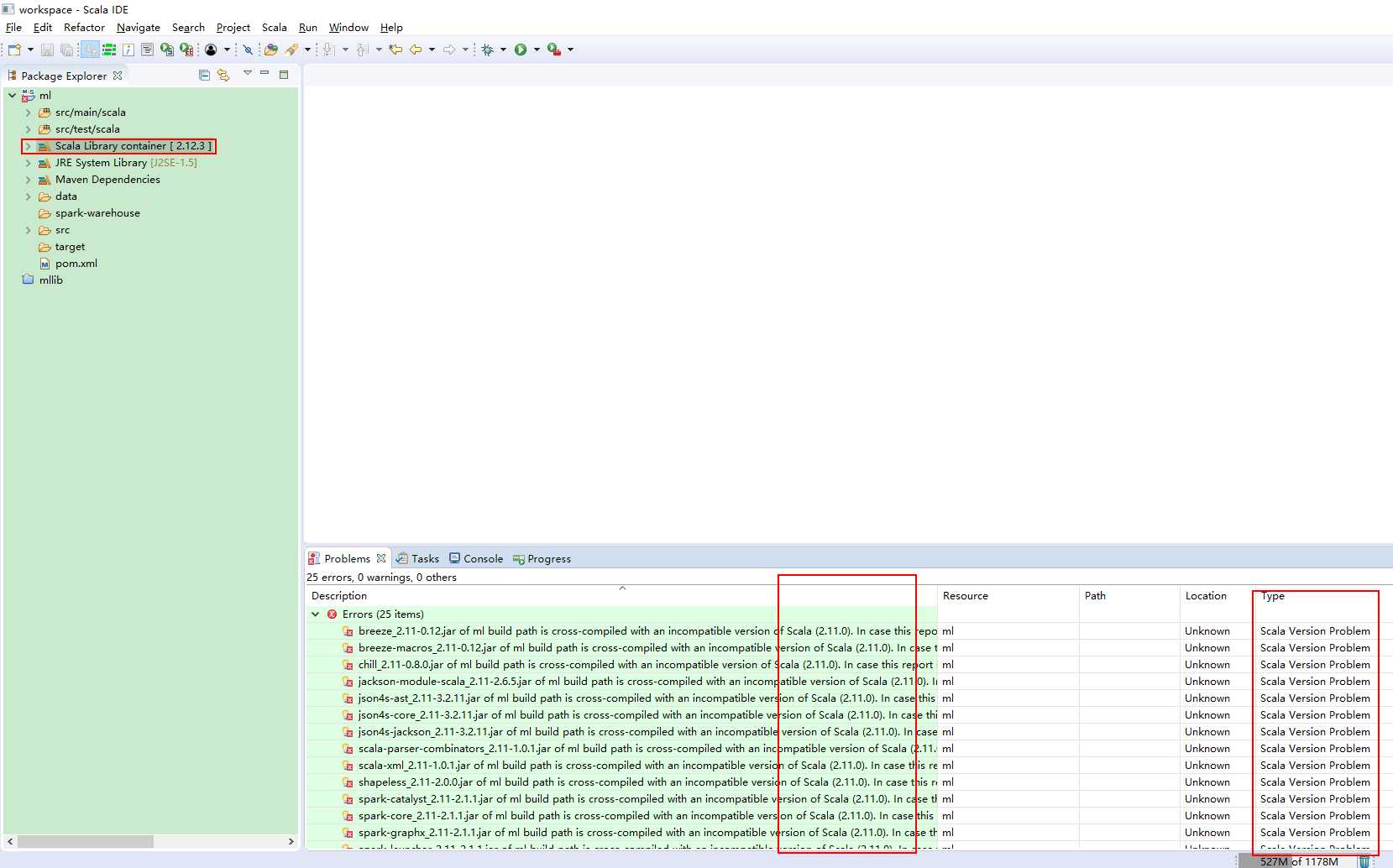
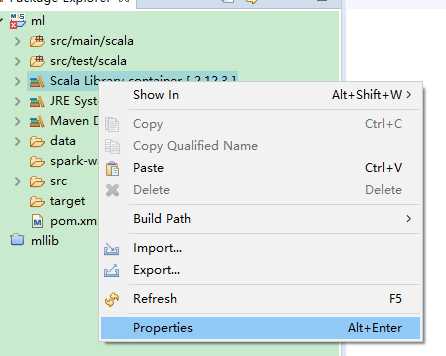
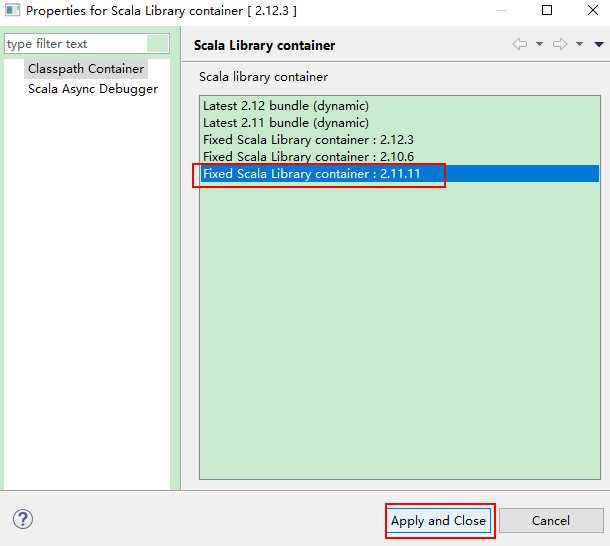
更换一下scala的依赖版本:
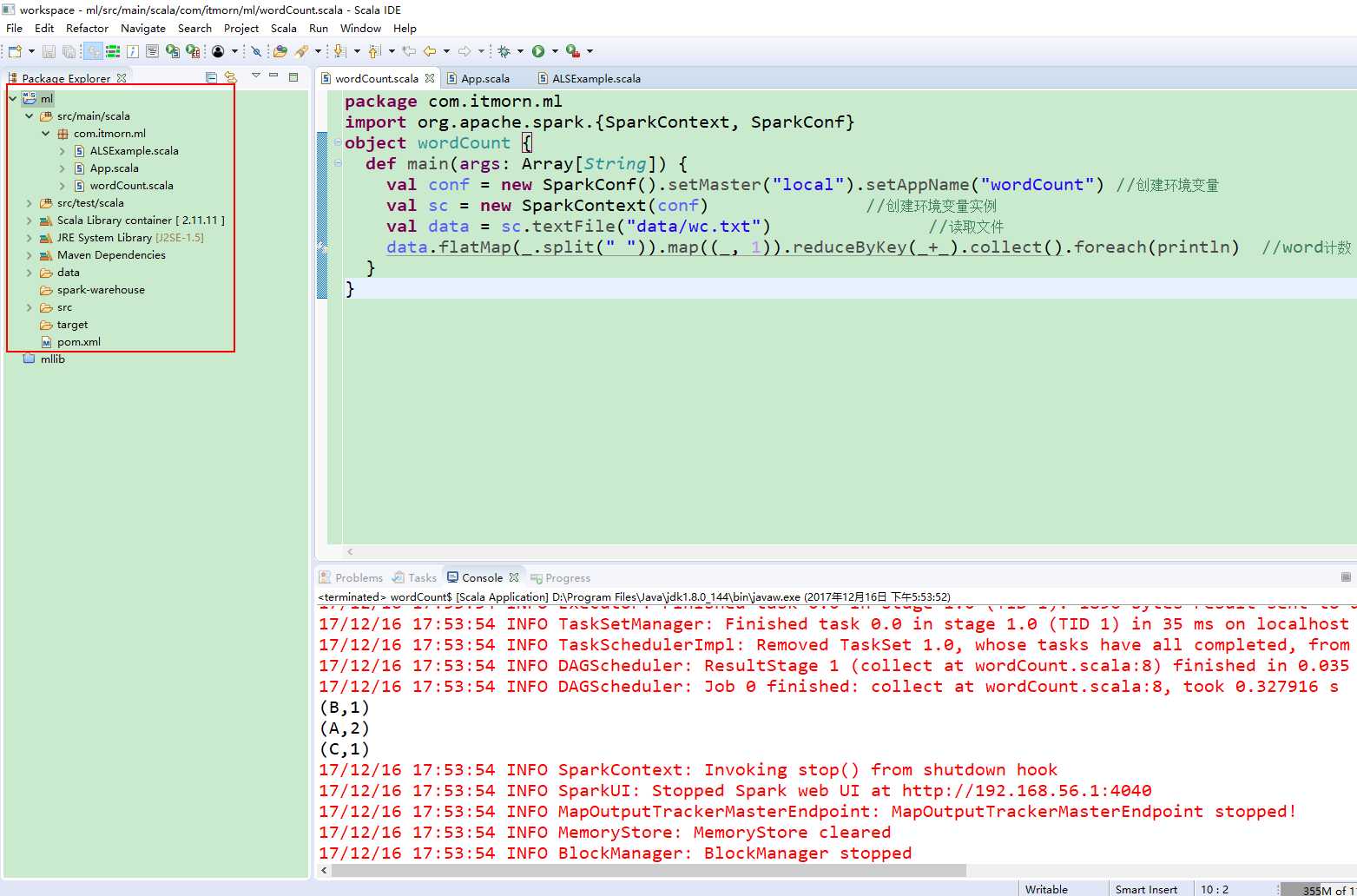
运行wordCount.scala程序
返回目录
|
Scala代码 |
package com.itmorn.ml import org.apache.spark.{SparkContext, SparkConf} object wordCount { def main(args: Array[String]) { val conf = new SparkConf().setMaster("local").setAppName("wordCount") //创建环境变量 val sc = new SparkContext(conf) //创建环境变量实例 val data = sc.textFile("data/wc.txt") //读取文件 data.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect().foreach(println) //word计数 } }
返回目录
|
条目7 |
。
返回目录
|
条目8 |
。
返回目录
文章标题:【Spark MLlib速成宝典】基础篇01Windows下spark开发环境搭建(Scala版)
文章链接:http://soscw.com/essay/106400.html