蚂蚁变大象:浅谈常规网站是如何从小变大的(十)(转)
2020-12-07 07:50
标签:style blog class java javascript ext width strong art get color 原文:http://blog.sina.com.cn/s/blog_6203dcd60100y9r7.html
【第十三阶段
:分布式计算和存储的运维设计与考虑】
以上的部分已经从前到后的将系统架构进行了描述,同时针对我们会遇到的问题进行了分析和处理,提出了一些解决方案,以保证我们的系统在不断增长的压力之下,如何的良好运转。
不过,我们很少描述运维相关的工作,以及设计如何和运维相关联。系统运维的成败,直接决定了系统设计的成败。所以系统的运维问题,是设计中必须考虑的问题。特别是当我们有成千上万的(tens of thousands)台机器的时候,运维越发显得重要。因此,在系统设计初期,就应当把运维问题纳入其中来进行综合的考虑。
如果我们用人来管机器,在几台、几十台机器的时候是比较可行的。出了问题,人直接上,搞定!不过,当我们有几百台、几千台、几万台、几十万台机器的时候,我们如果要让人去搞定,那就未见得可行了。
首先,人是不一定靠谱的。即使再聪明可靠的人,也有犯错误的时候。按照一定概率计算,如果我们机器数量变多,那么出错的绝对数量也是很大的。同时,人和人之间的协作也可能会出现问题。另外,每个人的素质也是不一样的。
其次,随着机器数量的膨胀,需要投入更多的人力来管理机器。人的精力是有限的,机器增多以后,需要增加人力来管理机器。这样的膨胀是难以承受的。
再次,人工恢复速度慢。如果出现了故障,人工来恢复的速度是比较慢的,一般至少是分钟级别。这对于要提供7×24小时的服务来说,系统稳定运行的指标是存在问题的。同时,随着机器的增多,机器出问题的概率一定的条件下,绝对数量会变多,这也导致我们的服务会经常处于出错的情况之下。
还有,如果涉及到多地机房,如何来管理还是一个比较麻烦的事情。
如果我们能转换思维,在设计系统的时候,如果能有一套自动化管理的模式,借助电脑的计算能力和运算速度,让机器来管理机器,那我们的工作就轻松了。
比如,我们可以设计一套系统,集成了健康检查、负载均衡、任务调度、自动数据切片、自动数据恢复等等功能,让这套系统来管理我们的程序,一旦出现问题,系统可以自动的发现有问题的机器,并自动修复或处理。
当然以上都是比较理想的情况。凡事没有绝对之说,只是需要尽可能达到一个平衡。
好了,说了这么多的问题,要表述的一点就是:人来管理机器是不靠谱的,我们需要尽量用机器来管理机器!
接下来,我们比较简单的描述一下一个比较理想的自动化管理模型。
我们将我们的系统层次进行初步的划分。
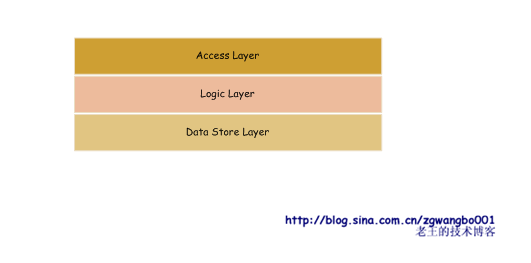
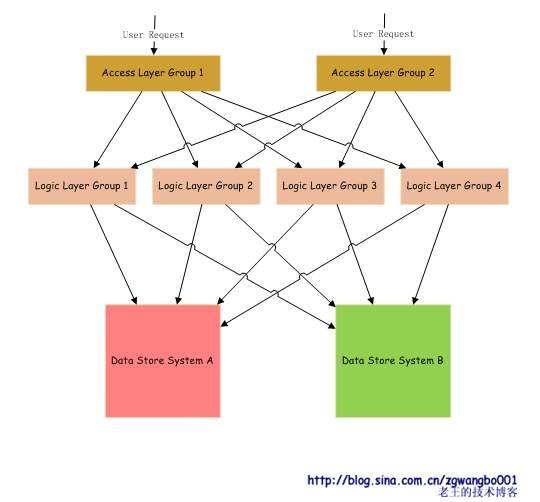
我们将系统粗略的划分为三个层次:访问接入层、逻辑处理层和数据存储层。上一次对下一层进行调用,获取数据,并返回。
因此,如果我们能够做到,说下一层提供给上一层足够可靠的服务,我们就可以简化我们的设计模型了。
好,那如果要提供足够可靠的服务,方便调用的话,应该如何来做呢?
我们可以针对每一层来看。
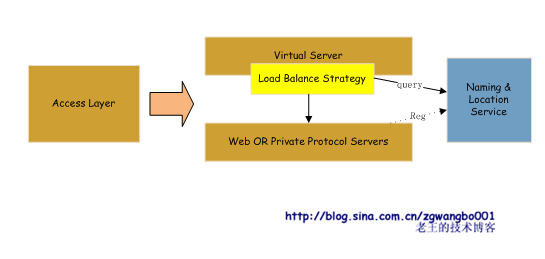
首先,看看访问接入层:
所有的Web Server和
Private Protocol Server将服务注册到命名和定位服务上。一旦注册后,NLS会定期去检查服务的存活,如果服务宕掉,会自动摘除,并发出报警信息,供运维人员查阅。等服务恢复后,再自动注册。
Virtual Server从NLS获取服务信息,并利用负载均衡策略去访问对应的后继服务。而对外,只看到有一台Virtual Server。
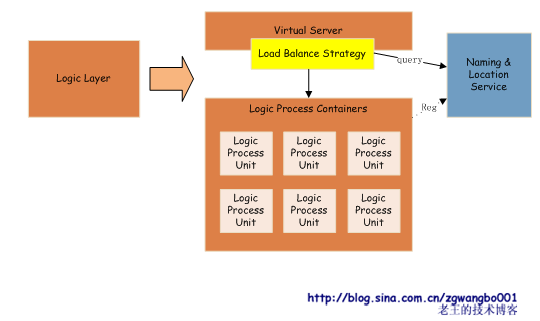
接下来,我们看看逻辑层:
由于HTTP的无状态性,我们将逻辑代码按标准接口写成一个个的逻辑处理单元,放入到我们的逻辑处理容器之中,进行统一的运行。并通过容器,到NLS中注册。Virtual Server通过NLS获取到对应的信息,并通过负载均衡策略将数据转发到下游。
这里比较关键的数据处理单元,实际就是我们要写的业务逻辑。业务逻辑的编写,我们需要严格按照容器提供的规范(如IDL的标准等),并从容器获取资源(如存储服务、日志服务等)。这样上线也变的简单,只需要将我们的处理单元发布到对应的容器目录下,容器就可以自动的加载服务,并在NLS上注册。如果某一个服务出现异常,就从NLS上将其摘掉。
容器做的工作就相对比较多。需要提供基本的服务注册功能、服务分发功能等。同时,还需要提供各种资源,如:存储服务资源(通过NLS、API等,提供存储层的访问接口)、日志服务资源等,给处理单元,让其能够方便的计算和处理。
总体来说,因为HTTP的无状态特性,以及不存在数据的存储,逻辑层要做到同构化是相对比较容易的,并且同构化以后的运维也就非常容易了。
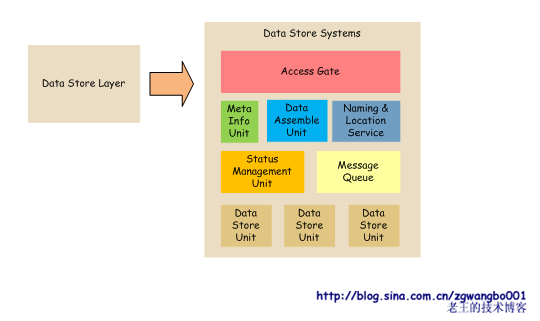
最后,看看数据存储层。
存储层是运维设计中最难的一部分。因为根据不同的业务需要,可能提供不同的存储引擎,而不同的存储引擎实现的机理和方式可能完全不一样。比如,为了保证数据的有效性和一致性,有些存储系统需要使用事务;而有些业务,可能为了追求高效,可能会牺牲一些数据的一致性,而提供快速的KV查询等等。
因此,数据存储层的异构性就是运维设计中亟待解决的问题。
一种比较理想的方式,就是让各个存储系统,隐藏内部的实现,对外提供简单的访问接口。而在系统内部,通过meta server、data assemble server、status manager、message queue等管理单元来管理数据存储单元。当然,这只是其中一种方式。也可以利用mysql类似的主从级联方式来管理,这种方式也是可行的。
数据存储系统的设计,也没有一个固定的规范(比如:Big
Table、Cassandra、Oracle数据库集群等),所以运维的设计需要在系统中来充分考虑。上述图示只是提供了一种简单的设计方案。
好了,有了多个层次的详细分析以后,上一层次调用下一层次,就直接通过固定的地址进行访问即可。
不过有一个问题就是,如果我们的Virtual
Server是一个单点,出现故障后,该层就不能提供服务。这个是我们不可接受的。怎么办呢?
要解决这样的问题,就是利用冗余。我们可以将我们的服务划分为多个组,分别由多个VS来管理。上层调用下层的时候,通过一定的选择策略来选择即可。这样,如果服务出现问题,我们就能通过冗余策略,将请求冗余到其他组上。
我们来看一个实例:
用户通过域名访问我们的服务,DNS通过访问IP解析,返回对应访问层的IP地址。访问层将请求转发到对应的逻辑处理组,逻辑处理组从不同的存储系统里获取数据,并返回处理结果。
通过以上的分析,我们通过原有的一些技术手段,可以做到比较好的自动化运维的方式。不过这种运维方式也不是完全智能的。有些时候也需要人工的参与。最难的一点就是存储系统的设计和实现。如果要完全的自动化的话,是一件比较难的事情。
说明:以上的描述是一个比较理想化的模型,要真正实现这种模型,需要很多的辅助手段,并且需要搭建很多基础设施。可能会遇到我们没有提到的很多的实际问题,比如:跨机房网络传输延迟、服务间隔离性、网卡带宽限制、服务的存活监控等等。因此,在具体实施的时候,需要仔细分析和考虑。
―――――――――――――
娱乐的分割线
―――――――――――――
昨天去看了2012北京车展,一次性把车已经看到麻木,只恨自己囊中羞涩。当然,看车模也是一个很重要的点。奉上照片。
―――――――――――――
回归技术的分割线
―――――――――――――
【第十四阶段
:杂货店】
前面将我遇到过的、我能想到的都基本列举出来了。由于能力所限,也就这点货了。接下来要给大家讲述的是一些比较杂的东西。但是在我们的网站发展中也是需要关注的,否则,即使我们的架构做的再好,这些点不跟上,我们的很多东西也没办法玩转。
1、防攻击
提前声明:由于我在这方面的研究很浅,了解的东西也仅限于原来课本上和工作中遇到的情况,所以如果有言之不对的地方请大家谅解。
人的思想良莠不齐,在这个充斥着利益的社会中,总有很多人想利用网络技术对我们的网站或者用户进行攻击,从而获取想得到的利益。
绝大部分的攻击都是因为我们自身程序写的有问题,攻击者利用程序本身的漏洞,发起攻击。所以我们需要很好的了解攻击的机理,并在程序中着重去处理和避免。
我自己将攻击划分为两大部分,基于服务能力的攻击和基于页面内容的攻击。
A、基于服务能力的攻击。
这种攻击,往往针对网站服务器本身。利用非法或者是恶意的请求,降低网站的服务能力,最终导致网站不能服务。
最常见的就是DoS(Denial of Service)和DDoS(Distributed Denial of Service)。
DoS往往是单机的攻击,利用协议或者是服务缺陷,耗尽服务资源。经典的案例:“死亡之ping”、“Syn flood”等等。
DDoS从名字上就可以看出,这种攻击采用分布式方式,攻击者控制成百上千的机器,然后集中发起访问攻击。让网站顷刻之间奔溃。即使我们服务能力再强,也是难以招架的。
基于服务能力的攻击的特点就是消耗服务器资源,降低服务器正常服务能力,从而使得服务器瘫痪。因此,对于他的控制也是需要从这个角度来下手。比如,增加DDoS防火墙等。
我们的服务层能控制的,就是对请求进行分析和判断,看看请求行为是否是攻击行为。比如:我们可以将所有到达服务的请求进行统一分析,如果同一个IP在一段时间内产生大量的请求,这个可能就是有问题的;或者,如果多个IP在一段时间内,大量请求同一个页面,这个也可能时候问题的;再者,如果突然之间,网站的访问量大增,这个有可能也是攻击。
在遇到这种情况的时候,我们有可能就需要对这种问题的请求进行拒绝,直接返回错误并关闭连接,保证我们的服务资源。如果是再严重一点的情况,我们可能就需要拒绝部分正常请求,保证系统一定的服务能力。
对于有一些不确定的情况,我们可以通过一些技术手段进行确认。比如,google在遭受攻击的时候,就会出验证码,让用户输入验证码来确认是否是攻击。
所以,在我们架构的接入层处,就需要有一个基于访问分析的防攻击策略系统,来帮我们做好这些基于服务能力的攻击。
B、基于页面内容的攻击
这种攻击,一般是为了获取用户数据信息,利用程序的漏洞,进行攻击,最终导致网站用户信息的泄露或者是网站数据的破坏。
常见的攻击有XSS、CSRF、SQL注入等等。
XSS(Cross Site Scripting),利用网站页面漏洞,植入JavaScript语句,破坏页面本身的展现或者数据,可以获取网站用户的信息,或是获得特殊的权限,能够对网站进行特殊的操作而获取利益。
因此,要解决这种攻击,最好的方式就是将程序写的更加的完善,对用户提交的内容进行HTML标签检查和转义等等。
CSRF(Cross-Site Request Forgery),这种跨站攻击,利用的两个点:1、用户登录;2、在不登出的情况下,访问恶意网站的提交代码。用户在我们的网站登录后,产生了cookie,第三方恶意网站通过一些手段,让用户访问了一个恶意网站,这个恶意网站发起对我们网站的一些提交调用,从而使得登录用户在不知情的情况下,提交了不是他想提交的数据。
因此,最根源的原因还是在于我们的提交接口是不安全的。
要解决这个问题,就是严格遵守HTTP协议的GET、POST等规范,同时,在提交的时候利用加密令牌、验证码等方式,来防止不知情的非法提交。
SQL注入,就是利用我们程序的漏洞,提交一些SQL语句,使得正常的SQL遭到截断,而执行一些非法的语句,使得数据遭到破坏,用户信息丢失等等。
这个问题产生的根源就是我们没有对提交的数据进行检查,SQL执行的时候,没有对数据进行转义(如; \ ’等特殊符号)。
那要解决这个问题也很简单,在SQL执行前,利用数据库提供的函数对SQL进行转义。
以上讲述的都是一些很常见的攻击方式,网络上讨论的也比较多。详细的可以通过网络来查询。
2、反作弊
我进入到公司的第一份工作就是做反作弊,之前也对这部分工作认识不是很清晰。到后来才发现,反作弊对于现在网站来说,有多么的重要,特别是UGC类的网站。如果是反作弊做的不好,这个网站基本上就废了。
作弊,从字面上就很容易理解,就是利用网站提供的功能,发表一些带有特殊目的的内容,骗取用户,从而达到金钱的、荣誉的、XXX的目的。因此,我们做反作弊的目的就是为了控制作弊用户不正常的行为,而保护正常用户。
从分析方式来讲,一般可以有智能和人工的方式。智能的方式一般就是利用数据挖掘、自然语言处理等来对信息进行分析,从而判断是否是作弊内容;而人工的方式,则是通过人工的去分析和判断,从而总结出经验,形成一套经验体系来对内容进行判断。
从作弊特点来讲,一般可以分为内容和行为作弊。基于内容的作弊一般可能是含有一些关键词,这些关键词本身就是很XX的词,因此这类问题只需要对关键词进行分析处理即可;对于另外一类,有可能不含有关键词,或者关键词很难分析,而是从某些行为上来判断。如:微薄的大量关注骗取反关注等,这一部分就需要从行为上来分析和判断。但是,往往我们都是将内容和行为相结合,来提升我们判断的准确度。
从处理方法来讲,一般可以有直接拒绝和分析后反馈的方式。如果我们有比较大的把握,通过一个提交行为就能分析出是作弊,那么我们就可以直接拒绝提交。如果我们不是很确定,我们可以通过一系列的行为内容分析以后再来判断,看之前的提交是否是作弊,如果是的话,我们就可以用分析后反馈的方式进行处理。
反作弊总的来说,就是需要用心去分析和挖掘,应该就能做的比较好。同时方法上需要充分利用现有的数据分析方法,对数据进行有效的分析,就能取得比较好的效果。
3、日志管理
我们的网站越来越大,对于日志其实是要求越来越严格。
一是反馈在日志的需求上。我们可能需要针对日志进行分析,或是针对日志做一些特殊的产品功能。
二是反馈在日志的产生量上。随着我们服务的增多和压力的增大,我们的日志可能每天以上G、T、P的数量级产生,如何有效的来组织日志,就是我们需要着重去关注的问题。
因此,需要我们对日志有以下的要求:
A、良好的日志打印框架。需要提供比较好的日志打印框架,方便程序打印日志;
B、标准的日志打印规范。越是大的系统,对于日志的规范要求越严格,否则到后来,日志就是没有办法管理的,或者是管理成本巨大;
C、统一的日志管理平台。对于日志的管理,最好是有统一的日志管理平台来处理。否则日志分散在各个机器上,没有办法进行统一的分析和处理,同时,对于历史日志的保存和管理也是没有办法进行的。
因此,对于我们架构的要求就是,提供标准日志打印库。其实业界也有很多好的库,比如log4j等。同时,需要根据业务特点,制定好标准的打印规范,最好将规范集成到库里,这样就能保证程序必须按规范打印。最后,是要有这样一个大容量数据存储和分析的平台。比如hadoop等,这样的分布式计算和处理平台,能比较好的满足我们对于日志的管理需求。
4、运维和监控体系
我们的服务能否良好的运行,除了架构以外,最重要的就是我们的运维和监控。我们之前的章节也讲述过,设计中必须要考虑运维的事情,否则这样的设计是没办法工作的。因此,一个好的体系,是需要有良好运维设计和考虑的。我们的运维和监控平台,必须能很好的配合线上架构,进行程序的发布、状态的监控以及问题的处理、问题追查。这几点缺一不可。
程序发布:最理想的情况是,系统自动发布程序,无需人工管理。程序发布后,由线上系统自动来接手启动服务。
状态监控:当程序放到线上开始运行的时候,我们就需要对程序的状态进行控制,如果出现异常,就需要提供预警机制,让后续处理单元来处理,并通知管理员。
问题处理:问题处理单元配合监控单元,对出现问题的机器或者是程序进行管理和处理,比如停止服务或者摘除机器等等。
问题追查:当问题机器或者程序摘除后,或者是服务异常后,需要能够快速的对问题进行追查和定位,避免更严重的问题出现。
一个好的运维和监控体系其实是一个系统工程,要考虑的因素相当的多,以上说的内容可能只是冰山的一角。
5、数据分析体系
一个好的系统,不光要能提供产品服务,还要能很好的提供产品分析和决策。这个时候,对于数据的分析就需要着重的考虑。其实,很多时候,不是技术决定了一个网站的发展,而是产品!
因此,数据分析对于网站的支持程度,很多时候决定了网站最后的发展。特别是一些中大型的网站,很多决策是需要基于对于数据的分析和判断。
数据分析工具现在也是比较多,最常用的就是数据挖掘和自然语言处理。经常会用的方法,如:分类、聚类、关联分析、语义分析等等。(我的研究生就是读的Data Mining方向,学了点基本概念,剩下的就是打酱油了,哈哈)
这一部分没有太多的实践过,所以紧紧提一提。真正涉及到的时候,可以着重的关注。
以上这些是我对于整体架构的补充和说明。这些内容都是在我们网站架构时必须要考虑的。否则,我们的架构体系很可能因为某些内容的缺失,而陷于瘫痪。
不过,因为个人能力和眼界有限,可能有些东西没有说到或者有遗漏,请谅解。
【总结】
终于在2012年的国际劳动节之前,洋洋洒洒的把这篇文章写完了。也是将自己对架构的所学、所见、所闻、所感基本上表达出来了。
同时,在即将迈入而立之年的时候,对自己过去十年编码生涯的一个回顾和总结。
高考的时候,我误打误撞进入了计算机系,不过我却很喜欢这一行,对编程的热爱推动着我不断的往前走。俗话说干一行爱一行,我觉得这个话其实可以反过来说:爱一行干一行。如果做一件事情最好有发自内心的热爱和兴趣,这样就能很好推动自己前进(我还记得我初中班主任说的一句话:兴趣是最好的老师。确实是的,我对语文就没啥兴趣,所以经常考试不及格,哈哈)。
我进入公司之前,做了几个网站,都有自己面临的问题,虽然也想了很多方案,但是当时也没有很好的解决。后来进了公司,从码工开始,一步步的了解分布式的设计,自己不断的问自己,这个为什么要这样设计,好处是什么,有什么问题。其实中间也亲历了几次架构的变迁。我自己感到很幸运,有机会能亲身参与其中。
后来,在反复的设计之后,总结出一点:不是为了架构而架构!而是根据实际业务的发展去定制需要的合理的架构。过渡架构设计会使得付出超过收获。
其实,架构的目的就是为了让系统运行的更轻松,开发者写代码更简单,运维者管理起来更方便。
最后,要感谢给予我帮助的朋友们,感谢大家的支持。名字很多,我都铭记于心,此处省略10000字。
在结束之前,来一句大家都已经很习惯的话:由于水平有限,文中有不慎之处敬请谅解和指正。 蚂蚁变大象:浅谈常规网站是如何从小变大的(十)(转),搜素材,soscw.com 蚂蚁变大象:浅谈常规网站是如何从小变大的(十)(转) 标签:style blog class java javascript ext width strong art get color 原文地址:http://www.cnblogs.com/ajianbeyourself/p/3701842.html