python第三天
2020-12-13 01:54
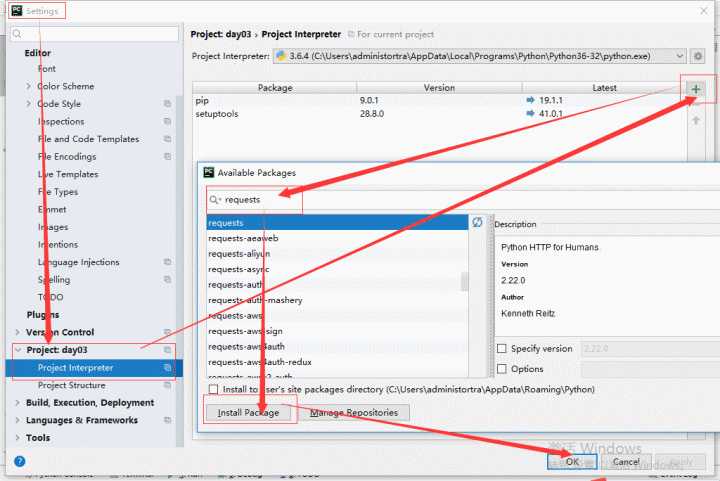
标签:html 二进制流 数据 项目 爬虫 空间 ext alt 自带 #以上是函数内置模块 time() ,json(),load() 的应用 图片解释如下图 #以下是函数的命名空间 #以下是爬虫百度页面的具体需要获取的信息 和具体操作 #以下是爬取梨视频的操作 #图一 点击视频可找到对应的链接 #图二 #安装requests库 方法 #安装清华园的访问外网 python第三天 标签:html 二进制流 数据 项目 爬虫 空间 ext alt 自带 原文地址:https://www.cnblogs.com/xiaohuangxiong/p/11018810.html # 1:time
# import time
# print(time.time())
# #等待2s
# time.sleep(2)
# print(time.time())
#2 os模块
# sys模块
# import os
# #可以与操作系统中的文件进行交互
# #判断文件路径是否存
# # 可以实现对路径
# # 也可以是绝对路径
# q=os.path.exists(‘haha.txt‘)
# s=os.path.exists(r‘C:\Users\administortra\PycharmProjects\untitled\day03\haha.txt‘)
# print(q,s)
# #获取当前环境根目录
# print(os.path.dirname(__file__))
import os
import sys
#获取python在环境变量中的路径
print(sys.path)
#把项目的根目录添加到环境变量中
sys.path.append(os.path.dirname(__file__))
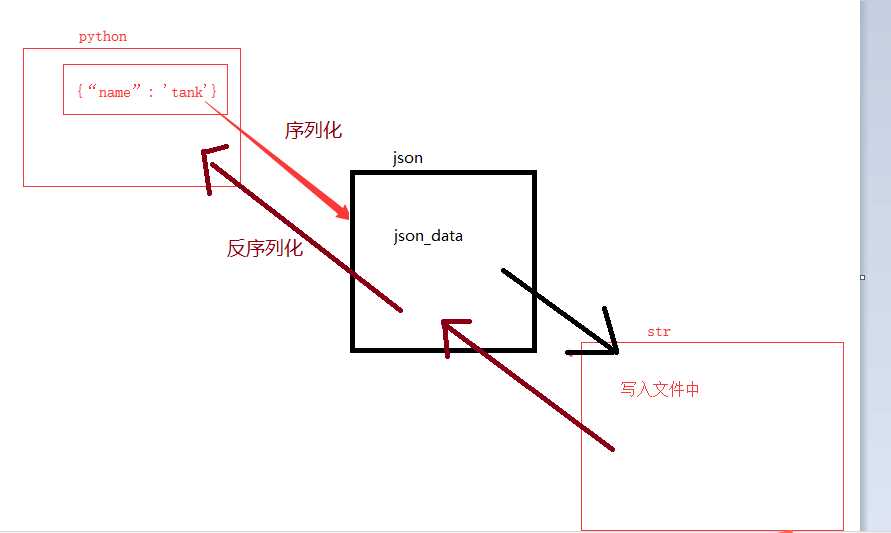
#json
# 八字点转成json数据
# 再把json转化成字符串
import json
user_info={‘name‘:‘tank‘,‘pwd‘:‘123‘}
res=json.dumps(user_info)
print(res)
print(type(res))
with open(‘user.json‘,‘wt‘,encoding=‘utf-8‘) as f:
f.write(res)
# loads: 反序列化
# json.loads()
# 把json文件数据读到内存中
# with open(‘user.json‘,‘r‘,encoding=‘utf-8‘) as f:
# #读到的是字符串
# res=f.read()
#
# user_dict=json.loads(res)
# #load是把json格式的字符串转化成dict类型
# print(user_dict)
# print(type(user_dict))
# dump简单的用法
user_info={‘name‘:‘tank‘,‘pwd‘:‘123‘}
with open(‘user.json‘,‘w‘,encoding=‘utf-8‘) as f:
#方法一
#即把user_info以json文件写成字符串格式
#str1=json.dump(user_info)
#f.write
#dunmp自带write功能
#方法二
json.dump(user_info,f)
#loads()
with open(‘user.json‘,‘r‘,encoding=‘utf-8‘) as f:
#方法一
#res=f.read()
#user_dict=json.loads(res)
#print(usr_dict)
#方法二
user_dict=json.load(f)
print(user_dict)
# 函数名称空间
# python解释器自带的:内置名称空间
# 自定义的py文件内 顶着最左边写的 成为全局名称空间
# 函数内部定义的 :局部名称空间
name=‘tank‘
def fun1():
print(‘func1 haha‘)
print(name)
#name查找顺序 先在fun1中查找是否有定义
# 再去函数外部找看是否有全局定义
#最后去Python解释其中查找
#print(name)
fun1()
# http协议
# url
#
#
# 请求方式
# get
#
#
# 请求头 cookie:
# user-agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36
# host:www.baidu.com
import requests
response=requests.get(url=‘https://www.baidu.com/‘)
response.encoding=‘utf-8‘
print(response)
#返回响应状态代码
print(response.status_code)#200
#返回响应文本
print(response.text)
print(type(response.text))#
import requests
res=requests.get(url=‘https://video.pearvideo.com/mp4/third/20190613/cont-1565757-12164372-114428-hd.mp4‘)
print(res.content)
with open(‘视频.mp4‘,‘wb‘) as f:
f.write(res.content)
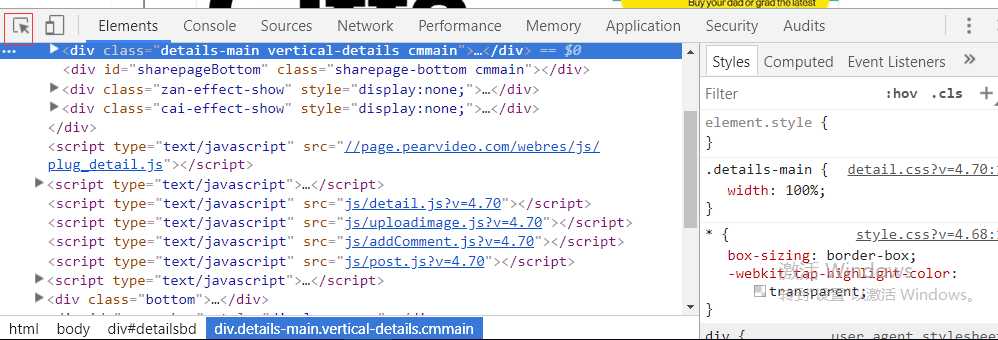
#先获得url 具体获得方式下图1贴出 输出二进制流文件 把它写到(视频.mp4)文件#中
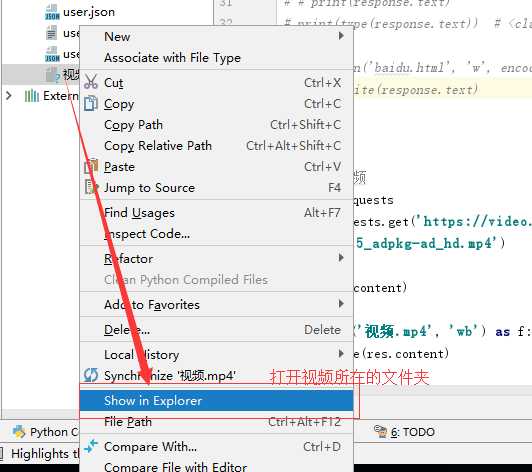
#写完后怎么查看下图二贴出