数据结构与算法之图
2020-12-13 02:09
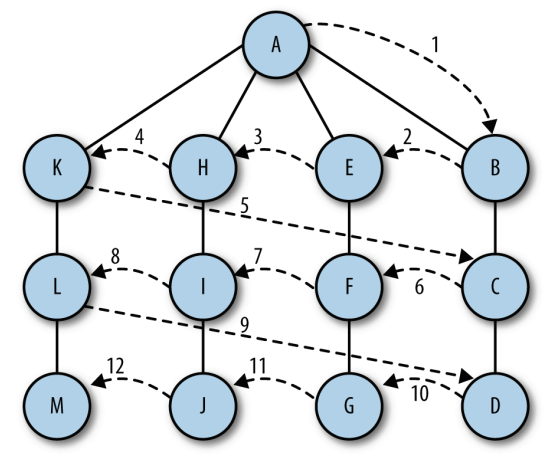
标签:它的 cto img 表示 marked 另一个 label += function 定义:图由边的集合及顶点的集合组成。顶点也有权重, 也称为成本。 如果一个图的顶点对是有序的, 则可以称之为有向图。在对有向图中的顶点对排序后, 便可以在两 如果图是无序的, 则称之为无序图, 或无向图。 图中的一系列顶点构成路径, 路径中所有的顶点都由边连接。 路径的长度用路径中第一个顶点到最后一个顶点之间边的数量表示。 由指向自身的顶点组成的路径称为环, 环的长度为 0。 圈是至少有一条边的路径, 且路径的第一个顶点和最后一个顶点相同。 无论是有向图还是无向图, 只要是没有重复边或重复顶点的圈, 就是一个简单圈。 除了第一个和最后一个顶点以外, 路径的其他顶点有重复的圈称为平凡圈。 如果两个顶点之间有路径, 那么这两个顶点就是强连通的, 反之亦然。 如果有向图的所有的顶点都是强连通的, 那么这个有向图也是强连通的。 用Vertex类表示节点,Vertex 类有两个数据成员: 一个用于标识顶点, 另一个是表明这个顶点是否被访问过的布尔值。它们分别被命名为 label 和 wasVisited。 用邻接表或邻接表数组来表示边。数组的索引表示顶点,元素是一个数组,里面的成员是与该顶点相连的其他顶点。因此邻接表是一个二维的数组。 搜索图分两种方式:深度优先和广度优先。 广度优先搜索算法:数据结构是队列。通过将顶点存入队列中,最先入队列的顶点先被探索。 深度优先 深度优先搜索包括从一条路径的起始顶点开始追溯, 直到到达最后一个顶点, 然后回溯,继续追溯下一条路径, 直到到达最后的顶点, 如此往复, 直到没有路径为止。 思路:访问一个没有访问过的顶点, 将它标记为已访问, 再递归地去访问在初始顶点的邻接表中其他没有访问过的顶点。 广度优先 广度优先搜索从第一个顶点开始, 尝试访问尽可能靠近它的顶点。 本质上, 这种搜索在图上是逐层移动的, 首先检查最靠近第一个顶点的层, 再逐渐向下移动到离起始顶点最远的层。 用JS实现以上两种搜索方法: 利用广度优先搜索方法查找最短路径(查找顶点1和顶点4之间的最短路径): 需要再扩展一个方法,通过执行一次广度优先搜索后得到的edgeTo数组来找到1和4节点之间相互连接的节点: 数据结构与算法之图 标签:它的 cto img 表示 marked 另一个 label += function 原文地址:https://www.cnblogs.com/simpul/p/11027185.html图
个顶点之间绘制一个箭头。 有向图表明了顶点的流向。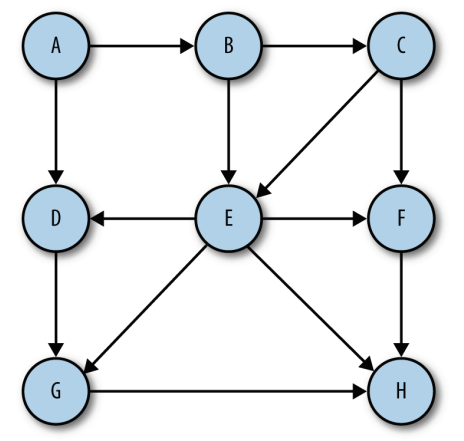
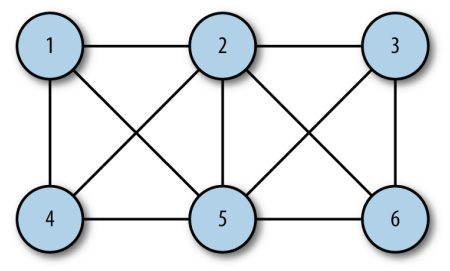
表示顶点
function Vertex(label){
this.label = label;
}表示边
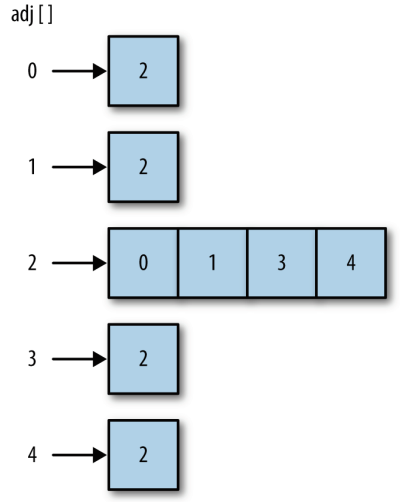
构建图与搜索图
深度优先搜索算法:数据结构是栈。通过将顶点存入栈中,沿着路径探索顶点,存在新的相邻顶点就去访问。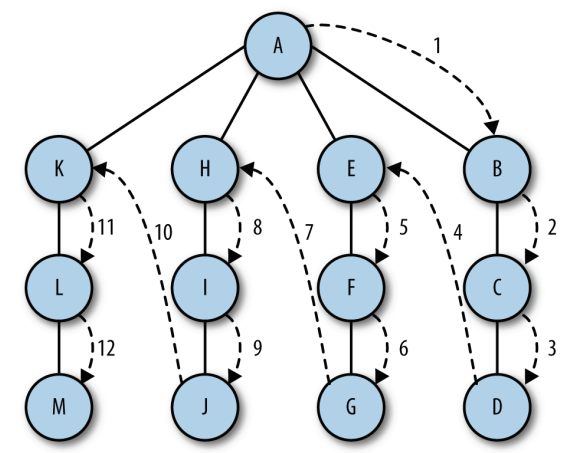
// 创建图类
function Graph(v){
this.vertices = v; // 共有多少个节点
this.edges = 0; // 有多少条边
this.adj = []; // 邻接表数组
for(var i = 0;i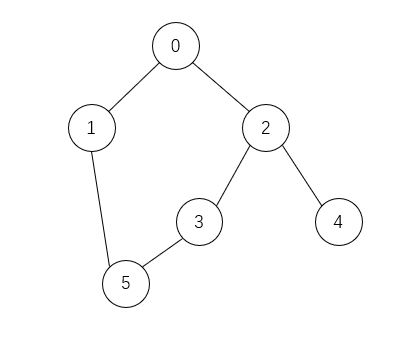
Graph.prototype.pathTo = function(w, v){
this.bfs(w);
var source = w; // 顶点w作为起点
if(!this.hasPathTo(v)){
return undefined;
}
var path = []; // 保存路径,不过是从终点到起点的
for(var i = v; i != source; i = this.edgeTo[i]){
path.push(i);
}
path.push(source);
return path;
}
Graph.prototype.hasPathTo(v){
return this.marked[v];
}
var g = new Graph(6);
g.addEdge(0, 1);
g.addEdge(0, 2);
g.addEdge(1, 5);
g.addEdge(2, 3);
g.addEdge(3, 5);
g.addEdge(2, 4);
g.showGraph();
g.pathTo(4, 1); // [1, 0, 2, 4]