一致性hash算法
2020-12-13 02:33
标签:md5 存储 影响 端口号 算法实现 缓存 不同的 高性能 其他 一致性哈希算法在分布式缓存领域的 MemCached,负载均衡领域的 Nginx 以及各类 RPC 框架中都有广泛的应用 普通的哈希表算法一般都是计算出哈希值后,通过取余操作将 key 值映射到不同的服务器上 Memcached 是一个高性能的分布式缓存系统,然而服务端没有分布式功能,各个服务器不会相互通信。 在这个过程中,客户端的算法首先要保证缓存的数据尽量均匀地分布在各个服务器上, 客户端算法是客户端分布式缓存性能优劣的关键。 首先将缓存服务器( ip + 端口号)进行哈希,映射成环上的一个节点 需要缓存数据时,计算出缓存数据 key 值的 hash key,同样映射到环上 顺时针选取最近的一个服务器节点作为该缓存应该存储的服务器 服务器 B 宕机下线,服务器 B 中存储的缓存数据要进行迁移,但由于一致性哈希环的存在,只需要迁移key 值为1的数据, 由于服务器 B 下线,key 值为1的数据顺时针最近的服务器是 C ,所以数据存迁移到服务器 C 上。 现实情况下,服务器在一致性哈希环上的位置不可能分布的这么均匀,导致了每个节点实际占据环上的区间大小不一。 MD5 算法 一致性hash算法 标签:md5 存储 影响 端口号 算法实现 缓存 不同的 高性能 其他 原文地址:https://www.cnblogs.com/jis121/p/11043687.html一致性哈希算法的应用
一致性哈希算法解决的问题
但是当服务器数量发生变化时,取余操作的除数就会发生变化,所有 key 所映射的服务器几乎都会改变,这对分布式缓存系统来说是不可以接受的。
一致性哈希算法能尽可能减少了服务器数量变化所导致的缓存迁移。memcached
它的分布式实现依赖于客户端的程序库,这也是 Memcached 的一大特点。
比如第三方的 spymemcached客户端就基于一致性哈希算法实现了其分布式缓存的功能。
1、向 Memcached 添加数据,首先客户端的算法根据 key 值计算出该 key 对应的服务器。
2、向选出的服务器保存缓存数据。
3、获取数据时,对于相同的 key ,客户端的算法还可以选出相同的服务器,从而获取数据
其次是当个别服务器下线或者上线时,会出现数据迁移,应该尽量减少需要迁移的数据量。以分布式缓存场景为例,分析一下一致性哈希算法环的原理
(取到ip+端口的hash值,以此值作为key,ip+端口作为value,放入TreeMap
(假如最终计算出的的hash key为5)
(从TreeMap中查找第一个大于等于5的key所对应的服务器,如果没有找到,则取TreeMap中的第一个服务器)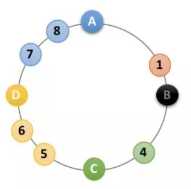
其他的数据的存储服务器不会发生变化。这也是一致性哈希算法比取余映射算法出色的地方。
这种情况下,可以增加虚节点来解决。通过增加虚节点,使得每个节点在环上所“管辖”的区域更加均匀。
这样就既保证了在节点变化时,尽可能小的影响数据分布的变化,而同时又保证了数据分布的均匀。几款比较常见的哈希算法
CRC 算法
MurmurHash 算法
FNV 算法
Ketama 算法