机器学习之推荐算法
2020-12-13 02:55
标签:rms turn 因子 距离 rom 开发 uil table sel 1、知识点 2、代码实现推荐案例 3、基于物品的协同过滤图 机器学习之推荐算法 标签:rms turn 因子 距离 rom 开发 uil table sel 原文地址:https://www.cnblogs.com/ywjfx/p/11061313.html"""
推荐系统
1、相似度计算:
1、欧几里德距离
2、皮尔逊相关系数
3、Cosin距离
2、推荐相似度选择:
1、固定数量的邻居
2、基于相似度门槛的邻居
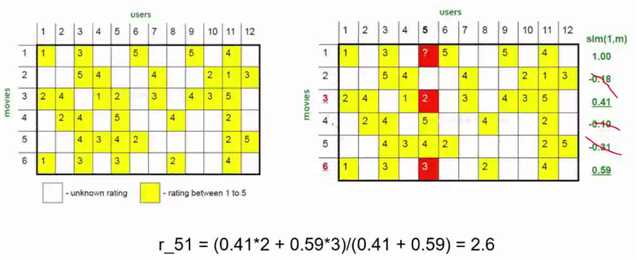
3、基于用户的协同过滤:根据用户和其他用户之间的相关系数值,选择值越小的用户数据,并和该用户比较,推荐物品
需要解决的问题:1、已知用户评分矩阵R(一般很稀疏) 2、推断矩阵中空格empty cells处的值
基于用户的协同过滤不利于对全0矩阵进行推荐,其解决方案:
1、相似度计算最好使用皮尔逊相似度
2、考虑共同打分物品的数目
3、对打分进行归一化处理
4、设置一个相似度阈值
缺点:1、稀疏问题(很多值为0) 2、大用户量不利于计算,因此不推荐基于用户的协同过滤
row:为用户 ,column:为物品
场景:实时新闻、突发情况(实时数据)
4、基于物品的协同过滤:根据物品和物品之间的相似度,然后取阈值,获取相邻的值,即推荐物品 (一般使用皮尔逊相关系数)
优点:1、计算性能高,用户数量大于物品数量
row:为用户物品 ,column:为用户
场景:图书、电子商务、电影(离线数据)
5、用户冷启动问题(即用户注册的时候):
1、引导用户把自己的一些属性表达出来
2、利用现有的开发数据平台
3、根据用户注册的属性
4、推荐排序榜单
6、物品冷启动问题:
1、文本分析
2、主题模型
3、打标签
4、推荐排行榜单
7、隐语义模型:将矩阵进行分解,然后求解隐含特征F,从而可以根据F得到一个先的具有填充值的NM矩阵,从而实现推荐,即NM = NF * FM
1、从数据出发,今天个性化推荐
2、用户和物品之间有着隐含联系
3、隐含因子让计算机能理解就好
4、将用户和物品通过中介隐含因子联系起来
隐语义模型参数选择:
1、隐特征的个数F,通常F=100
2、学习率alpha 别太大
3、正则化参数lambda,别太大
4、负样本和正样本比例ratio
8、协同过滤与 隐语义对比
1、原理:协同过滤基于统计方法,隐语义基于建模
2、空间复杂度,隐语义模型较小
3、实时推荐依旧难,目前离线计算多
9、模型评估指标
1、准确率 :均方误差
2、召回率 :正负样本中,推荐正样本中正确的比例
3、覆盖率
4、多样性
推荐难点:
1、计算量解决
2、模型的好坏怎么评估,怎么更新
suprise 推荐系统api
url:https://surprise.readthedocs.io/en/stable/getting_started.html
数据地址:http://files.grouplens.org/datasets/movielens/ml-100k-README.txt
基于用户的协同过滤:
"""
# coding = utf-8
from __future__ import (absolute_import,division,print_function,unicode_literals)
from surprise import SVD,KNNBasic
from surprise import Dataset
from surprise import evaluate,print_perf
from surprise import GridSearch
import pandas as pd
import os
import io
from surprise import KNNBaseline
def collaborativeFiltering():
"""
协同过滤算法
:return:
"""
#1、加载数据
data = Dataset.load_builtin(‘ml-100k‘)
data.split(n_folds=3)#3折,结果有3个
#2、实例化协同过滤算法对象
algo = KNNBasic()
pref =evaluate(algo,data,measures=[‘RMSE‘,‘MAE‘])#算法模型评估
print_perf(pref)
def matrixFactorization():
"""
SVD,矩阵分解
:return:
"""
param_grid = {‘n_epochs‘:[5,10],‘lr_all‘:[0.002,0.005],‘reg_all‘:[0.4,0.6]}
grid_search = GridSearch(SVD,param_grid,measures=[‘RMSE‘,‘FCP‘])
data = Dataset.load_builtin(‘ml-100k‘)
data.split(n_folds=3) # 3折,结果有3个
grid_search.evaluate(data)
print(grid_search.best_score[‘RMSE‘]) #最好的得分值
print(grid_search.best_params[‘RMSE‘]) # 最好的得分值
result_df =pd.DataFrame.from_dict(grid_search.cv_results)
print(result_df)
def recommendItem():
data = Dataset.load_builtin(‘ml-100k‘) #加载u.data文件
trainset = data.build_full_trainset()
sim_options = {‘name‘:‘pearson_baseline‘,‘user_based‘:False} #皮尔逊相似度pearson_baseline ,‘user_based‘:False表示基于物品的协同过滤
algo = KNNBaseline(sim_options=sim_options) #协同过滤
algo.train(trainset) #训练
#获取电影的id
rid_to_name,name_to_rid = read_item_names()
toy_story_raw_id = name_to_rid[‘Now and Then (1995)‘]
print(toy_story_raw_id) #数据文件中的id
toy_story_inner_id =algo.trainset.to_inner_iid(toy_story_raw_id)
print(toy_story_inner_id)#实际计算矩阵中的id
toy_story_neighbors_id = algo.get_neighbors(toy_story_inner_id,k=10)
print(toy_story_neighbors_id) #实际计算矩阵中的id
toy_story_neighbors_id = (algo.trainset.to_raw_iid(inner_id) for inner_id in toy_story_neighbors_id) #数据文件中的id
toy_story_neighbors_name = (rid_to_name[rid] for rid in toy_story_neighbors_id) #数据文件中的name
print("##########推荐item#########")
for movie in toy_story_neighbors_name:
print(movie)
def read_item_names():
file_name=(‘./ml-100k/u.item‘)
rid_to_name={}
name_to_rid={}
with io.open(file_name,‘r‘,encoding=‘ISO-8859-1‘) as f:
for line in f:
line = line.split(‘|‘)
rid_to_name[line[0]] = line[1]
name_to_rid[line[1]]=line[0]
return rid_to_name,name_to_rid
if __name__ == ‘__main__‘:
recommendItem()