标签:poi microsoft sof system details rod alt mem comm
将一个对象的集合转化成另一个对象的集合
List orderDetailList = orderDetailService.listOrderDetails();
List cartDTOList = orderDetailList.stream()
.map(e -> new CartDTO(e.getProductId(), e.getProductQuantity()))
.collect(Collectors.toList());
交集 (list1 + list2)
List intersect = list1.stream()
.filter(list2::contains)
.collect(Collectors.toList());
差集
//(list1 - list2)
List reduce1 = list1.stream().filter(item -> !list2.contains(item)).collect(toList());
//(list2 - list1)
List reduce2 = list2.stream().filter(item -> !list1.contains(item)).collect(toList());
并集
//使用并行流
List listAll = list1.parallelStream().collect(toList());
List listAll2 = list2.parallelStream().collect(toList());
listAll.addAll(listAll2);
去重并集
List listAllDistinct = listAll.stream()
.distinct().collect(toList());
从List中过滤出一个元素
User match = users.stream()
.filter((user) -> user.getId() == 1).findAny().get();
Map集合转 List
List list = map.entrySet().stream().sorted(Comparator.comparing(e -> e.getKey()))
.map(e -> new Person(e.getKey(), e.getValue())).collect(Collectors.toList());
List list = map.entrySet().stream().sorted(Comparator.comparing(Map.Entry::getValue)).map(e -> new Person(e.getKey(), e.getValue())).collect(Collectors.toList());
List list = map.entrySet().stream().sorted(Map.Entry.comparingByKey()).map(e -> new Person(e.getKey(), e.getValue())).collect(Collectors.toList());
List集合转 Map
/*使用Collectors.toMap形式*/
Map result = peopleList.stream().collect(Collectors.toMap(p -> p.name, p -> p.age, (k1, k2) -> k1));
//其中Collectors.toMap方法的第三个参数为键值重复处理策略,如果不传入第三个参数,当有相同的键时,会抛出一个IlleageStateException。
//或者
Map result1 = list.stream().collect(Collectors.toMap(Hosting::getId, Hosting::getName));
//List -> Map
List peopleList = new ArrayList();
peopleList.add(new People("test1", "111"));
peopleList.add(new People("test2", "222"));
Map result = peopleList.stream().collect(HashMap::new,(map,p)->map.put(p.name,p.age),Map::putAll);
List 转 Map
/**
* List -> Map
* 需要注意的是:
* toMap 如果集合对象有重复的key,会报错Duplicate key ....
* apple1,apple12的id都为1。
* 可以用 (k1,k2)->k1 来设置,如果有重复的key,则保留key1,舍弃key2
*/
Map appleMap = appleList.stream().collect(Collectors.toMap(Apple::getId, a -> a,(k1, k2) -> k1));
List 转 List
List
Collectors toList
streamArr.collect(Collectors.toList());
List collectList = Stream.of(1, 2, 3, 4)
.collect(Collectors.toList());
System.out.println("collectList: " + collectList);
// 打印结果 collectList: [1, 2, 3, 4]
Collectors toMap
map value 为对象 student
Map map = list.stream().collect(Collectors.toMap(Student::getId, student -> student));
// 遍历打印结果
map.forEach((key, value) -> {
System.out.println("key: " + key + " value: " + value);
});
map value 为对象中的属性
Map map = list.stream().collect(Collectors.toMap(Student::getId, Student::getName));
map.forEach((key, value) -> {
System.out.println("key: " + key + " value: " + value);
});
字典查询和数据转换 toMap时,如果value为null,会报空指针异常
//方法一
Map> resultMaps = Arrays.stream(dictTypes)
.collect(Collectors.toMap(i -> i, i -> Optional.ofNullable(dictMap.get(i)).orElse(new ArrayList()), (k1, k2) -> k2));
//方法二
Map> resultMaps = Arrays.stream(dictTypes)
.filter(i -> dictMap.get(i) != null).collect(Collectors.toMap(i -> i, dictMap::get, (k1, k2) -> k2));
//方法三
Map memberMap = list.stream().collect(HashMap::new, (m,v)->
m.put(v.getId(), v.getImgPath()),HashMap::putAll);
System.out.println(memberMap);
//方法四
Map memberMap = new HashMap();
list.forEach((answer) -> memberMap.put(answer.getId(), answer.getImgPath()));
System.out.println(memberMap);
Map memberMap = new HashMap();
for (Member member : list) {
memberMap.put(member.getId(), member.getImgPath());
}
假设有一个User实体类,有方法getId(),getName(),getAge()等方法,现在想要将User类型的流收集到一个Map中,示例如下:
Stream userStream = Stream.of(new User(0, "张三", 18), new User(1, "张四", 19), new User(2, "张五", 19), new User(3, "老张", 50));
Map userMap = userSteam.collect(Collectors.toMap(User::getId, item -> item));
假设要得到按年龄分组的Map,可以按这样写:
Map> ageMap = userStream.collect(Collectors.toMap(User::getAge, Collections::singletonList, (a, b) -> {
List resultList = new ArrayList(a);
resultList.addAll(b);
return resultList;
}));
Map map = persons
.stream()
.collect(Collectors.toMap(
p -> p.age,
p -> p.name,
(name1, name2) -> name1 + ";" + name2));
System.out.println(map);
// {18=Max, 23=Peter;Pamela, 12=David}
Map 转 另一个Map
//示例1 Map> 转 Map
Map> map = new HashMap();
map.put("java", Arrays.asList("1.7", "1.8"));
map.entrySet().stream();
@Getter
@Setter
@AllArgsConstructor
public static class User{
private List versions;
}
Map collect = map.entrySet().stream()
.collect(Collectors.toMap(
item -> item.getKey(),
item -> new User(item.getValue())));
//示例2 Map 转 Map
Map pointsByName = new HashMap();
Map maxPointsByName = new HashMap();
Map gradesByName = pointsByName.entrySet().stream()
.map(entry -> new AbstractMap.SimpleImmutableEntry(
entry.getKey(), ((double) entry.getValue() /
maxPointsByName.get(entry.getKey())) * 100d))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
Collectors toSet
Set result = Stream.of("aa", "bb", "cc", "aa").collect(HashSet::new, HashSet::add, HashSet::addAll);
//Collectors类中已经预定义好了toList,toSet,toMap,toCollection等方便使用的方法,所以以上代码还可以简化如下:
Set result2 = Stream.of("aa", "bb", "cc", "aa").collect(Collectors.toSet());
Set collectSet = Stream.of(1, 2, 3, 4).collect(Collectors.toSet());
System.out.println("collectSet: " + collectSet);
// 打印结果 collectSet: [1, 2, 3, 4]
Stack stack1 = stream.collect(Collectors.toCollection(Stack::new));
// collect toString
String str = stream.collect(Collectors.joining()).toString();
Collectors groupingBy
Map> ageMap2 = userStream
.collect(Collectors.groupingBy(User::getAge));
//groupingBy 分组后操作
//Collectors中还提供了一些对分组后的元素进行downStream处理的方法:
//counting方法返回所收集元素的总数;
//summing方法会对元素求和;
//maxBy和minBy会接受一个比较器,求最大值,最小值;
//mapping函数会应用到downstream结果上,并需要和其他函数配合使用;
Map sexCount = userStream.collect(Collectors.groupingBy(User::getSex,Collectors.counting()));
Map ageCount = userStream.collect(Collectors.groupingBy(User::getSex,Collectors.summingInt(User::getAge)));
Map> ageMax = userStream.collect(Collectors.groupingBy(User::getSex,Collectors.maxBy(Comparator.comparing(User::getAge))));
Map> nameMap = userStream.collect(Collectors.groupingBy(User::getSex,Collectors.mapping(User::getName,Collectors.toList())));
groupingBy 根据年龄来分组:
Map peopleByAge = peoples.stream()
.filter(p -> p.age > 12).collect(Collectors.groupingBy(p -> p.age, Collectors.toList()));
groupingBy 根据年龄分组,年龄对应的键值List存储的为Person的姓名:
Map peopleByAge = people.stream()
.collect(Collectors.groupingBy(p -> p.age, Collectors.mapping((Person p) -> p.name, Collectors.toList())));
//mapping即为对各组进行投影操作,和Stream的map方法基本一致。
groupingBy 根据姓名分组,获取每个姓名下人的年龄总和:
Map sumAgeByName = peoples.stream().collect(Collectors.groupingBy(p -> p.name, Collectors.reducing(0, (Person p) -> p.age, Integer::sum)));
/* 或者使用summingInt方法 */
sumAgeByName = peoples.stream().collect(Collectors.groupingBy(p -> p.name, Collectors.summingInt((Person p) -> p.age)));
groupingBy Boolean分组:
Map> collectGroup = Stream.of(1, 2, 3, 4)
.collect(Collectors.groupingBy(it -> it > 3));
System.out.println("collectGroup : " + collectGroup);
// 打印结果
// collectGroup : {false=[1, 2, 3], true=[4]}
groupingBy 按年龄分组
Map> personsByAge = persons.stream().collect(Collectors.groupingBy(p -> p.age));
personsByAge.forEach((age, p) -> System.out.format("age %s: %s\n", age, p));
// age 18: [Max]
// age 23: [Peter, Pamela]
// age 12: [David]
Collectors partitioningBy
Collectors中还提供了partitioningBy方法,接受一个Predicate函数,该函数返回boolean值,用于将内容分为两组。假设User实体中包含性别信息getSex(),可以按如下写法将userStream按性别分组:
Map> sexMap = userStream
.collect(Collectors.partitioningBy(item -> item.getSex() > 0));
可以看到Java8的分组功能相当强大,当然你还可以完成更复杂的功能。另外Collectors中还存在一个类似groupingBy的方法:partitioningBy,它们的区别是partitioningBy为键值为Boolean类型的groupingBy,这种情况下它比groupingBy更有效率。
partitioningBy 将数字的Stream分解成奇数集合和偶数集合。
Map> collectParti = Stream.of(1, 2, 3, 4)
.collect(Collectors.partitioningBy(it -> it % 2 == 0));
System.out.println("collectParti : " + collectParti);
// 打印结果
// collectParti : {false=[1, 3], true=[2, 4]}
Collectors joining
Collectors.joining 收集Stream中的值,该方法可以方便地将Stream得到一个字符串。joining函数接受三个参数,分别表示允(用以分隔元素)、前缀和后缀:
String names = peoples.stream().map(p->p.name).collect(Collectors.joining(","))
String strJoin = Stream.of("1", "2", "3", "4")
.collect(Collectors.joining(",", "[", "]"));
System.out.println("strJoin: " + strJoin);
// 打印结果
// strJoin: [1,2,3,4]
//字符串连接
String phrase = persons
.stream()
.filter(p -> p.age >= 18)
.map(p -> p.name)
.collect(Collectors.joining(" and ", "In Germany ", " are of legal age."));
System.out.println(phrase);
// In Germany Max and Peter and Pamela are of legal age.
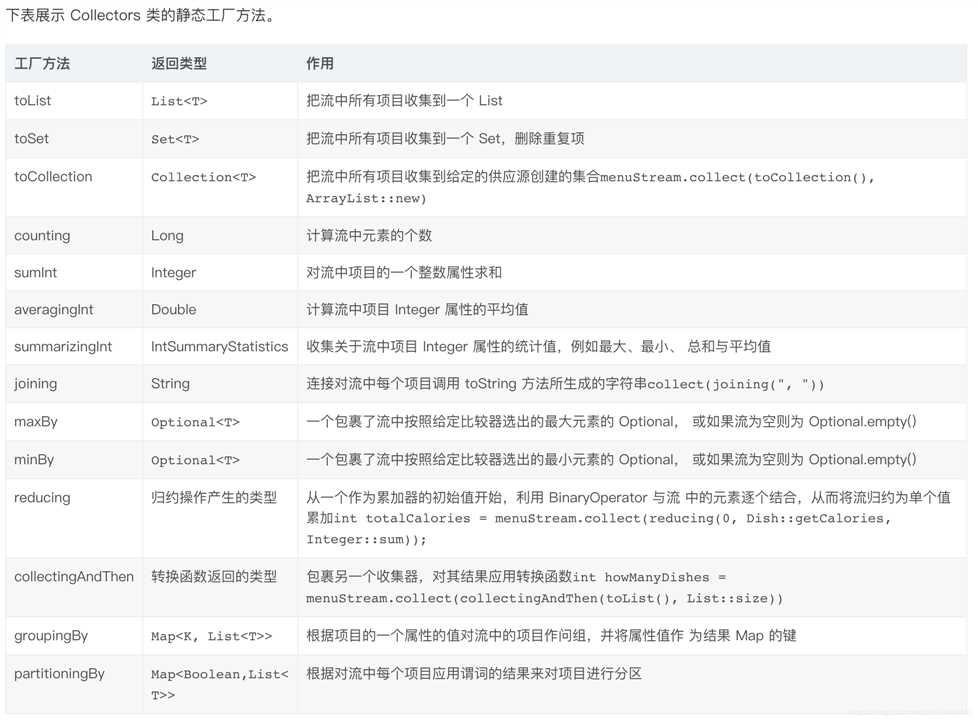
Collectors分别提供了求平均值averaging、总数couting、最小值minBy、最大值maxBy、求和suming等操作。但是假如你希望将流中结果聚合为一个总和、平均值、最大值、最小值,那么Collectors.summarizing(Int/Long/Double)就是为你准备的,它可以一次行获取前面的所有结果,其返回值为(Int/Long/Double)SummaryStatistics。
DoubleSummaryStatistics dss = people.collect(Collectors.summarizingDouble((Person p)->p.age));
double average=dss.getAverage();
double max=dss.getMax();
double min=dss.getMin();
double sum=dss.getSum();
double count=dss.getCount();
IntSummaryStatistics ageSummary = persons
.stream()
.collect(Collectors.summarizingInt(p -> p.age));
System.out.println(ageSummary);
// IntSummaryStatistics{count=4, sum=76, min=12, average=19.000000, max=23}
使用collect可以将Stream转换成值。maxBy和minBy允许用户按照某个特定的顺序生成一个值。
averagingDouble:求平均值,Stream的元素类型为double
averagingInt:求平均值,Stream的元素类型为int
averagingLong:求平均值,Stream的元素类型为long
counting:Stream的元素个数
maxBy:在指定条件下的,Stream的最大元素
minBy:在指定条件下的,Stream的最小元素
reducing: reduce操作
summarizingDouble:统计Stream的数据(double)状态,其中包括count,min,max,sum和平均。
summarizingInt:统计Stream的数据(int)状态,其中包括count,min,max,sum和平均。
summarizingLong:统计Stream的数据(long)状态,其中包括count,min,max,sum和平均。
summingDouble:求和,Stream的元素类型为double
summingInt:求和,Stream的元素类型为int
summingLong:求和,Stream的元素类型为long
Optional collectMaxBy = Stream.of(1, 2, 3, 4)
.collect(Collectors.maxBy(Comparator.comparingInt(o -> o)));
System.out.println("collectMaxBy:" + collectMaxBy.get());
// 打印结果
// collectMaxBy:4
Collectors averagingInt计算平均值
Double averageAge = persons
.stream()
.collect(Collectors.averagingInt(p -> p.age));
System.out.println(averageAge); // 19.0
原文阅读 传参
java8 Lambda Stream collect Collectors 常用实例
标签:poi microsoft sof system details rod alt mem comm
原文地址:https://www.cnblogs.com/blackCatFish/p/11074820.html