python_机器学习_监督学习模型_决策树
2020-12-13 03:39
标签:rop desktop 决策树 ESS array https open 数值 wro 机器学习肿分类和预测算法的评估: a. 准确率 b.速度 c. 强壮行 d.可规模性 e. 可解释性 https://scikit-learn.org/stable/modules/tree.html 变量的不确定越大,熵也就越大。 生成后的决策树 逻辑代码: 但这段代码不是特别通用,而且有bug, 需要修改,但基本逻辑是正确的 python_机器学习_监督学习模型_决策树 标签:rop desktop 决策树 ESS array https open 数值 wro 原文地址:https://www.cnblogs.com/renfanzi/p/11078489.html1. 监督学习--分类

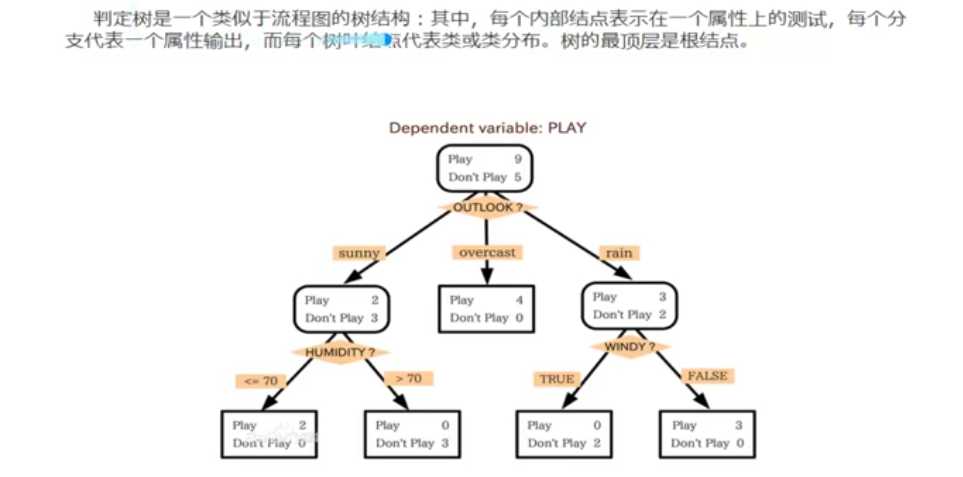
2. 什么是决策树/判定树(decision tree)?
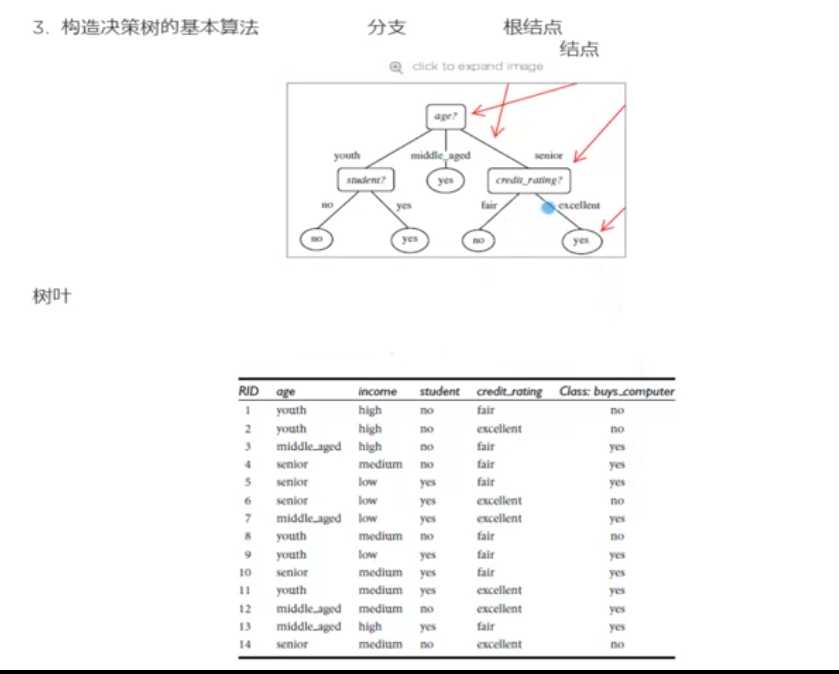
3. 熵(entropy)概念:

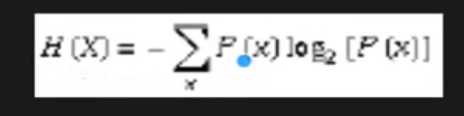
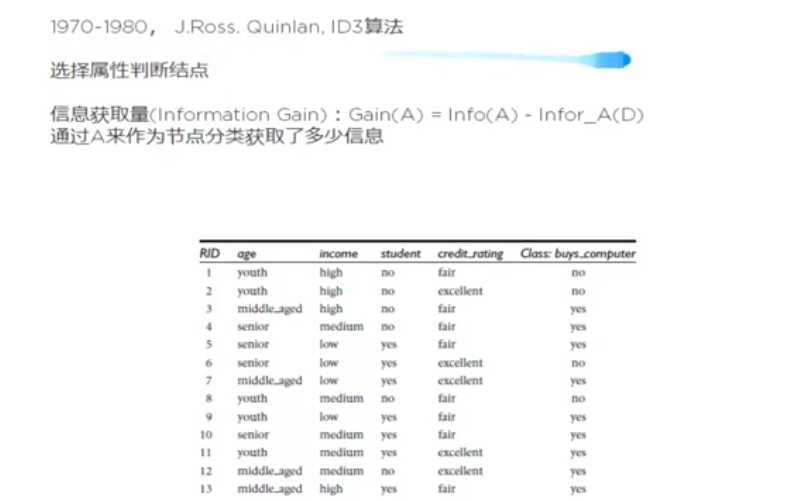
4. 决策树归纳算法(ID3)

5. 其他算法及优缺点

6. 决策树的应用


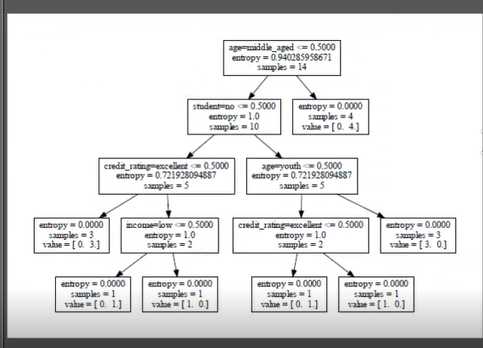
# -*- coding:utf-8 -*-
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import preprocessing
from sklearn import tree # 要求是数值型的值
from sklearn.externals.six import StringIO
"""
注意: 决策树要求要数值型的值,不能是字符串类型的值
例如: no, yes这样的值是不允许的
需要转换成矩阵
====================================
age income student
youth high no
youth high no
middle_aged high no
senior medium no
senior low yes
====================================
比如上面这种数据:
youth middle_aged senior high medium low ......
1 0 0 1 0 0
1 0 0 1 0 0
.....
"""
allElectronicsData = open(r"C:\Users\Administrator\Desktop\data.xlsx", ‘r‘)
reader = csv.reader(allElectronicsData)
print(reader)
headers = next(reader)
print(headers)
# ["RID", ‘age‘.....]
featureList = []
labelList = []
for row in reader:
labelList.append(row[len(row) - 1])
rowDict = {}
for i in range(1, len(row) - 1):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
print(featureList)
# [
# {"credit_rating": "fair", "age": "youth"},
# .... #作用,方便转换成矩阵。将数据转换成对象
# ]
vec = DictVectorizer()
dummyX = vec.fit_transform(featureList).toarray()
print("dummyX:" + str(dummyX)) # 转换成矩阵的数据了二维
print(vec.get_feature_names())
print("labelList: " + str(labelList))
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: " + str(dummyY))
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(dummyX, dummyY)
print("clf: ", str(clf))
# 存储决策树信息
# Graphviz 将dot转换成pdf的命令: dot -T pdf iris.dot -o output.pdf
# 可以查看decision tree 的形状了(看pdf的值)
with open(r"C:\Users\Administrator\Desktop\code\mechine_learning\allElectronicInformationGainOri.dot", "w") as f:
f = tree.export_graphviz(clf, feature_names = vec.get_feature_names(), out_file = f)
# 下面的代码属于预测的代码
# 属于转化后的矩阵数值,其实就是进行复制修改
oneRowX = dummyX[0, :]
print("oneRowX: " + str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX: ", str(newRowX))
predictedY = clf.predicted(newRowX)
# 预测 class_buys_labels的值
predicted("predictedY: " + str(predictedY))
if __name__ == ‘__main__‘:
main()