算法详解之最近公共祖先(LCA)
2020-12-13 05:37
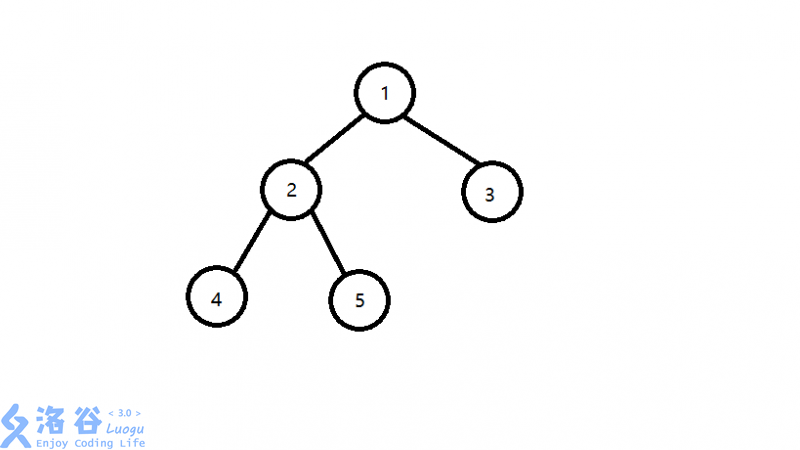
标签:开始 初学 情况 处理 dfs 居中 否则 集合 upload 首先是最近公共祖先的概念(什么是最近公共祖先?): 在一棵没有环的树上,每个节点肯定有其父亲节点和祖先节点,而最近公共祖先,就是两个节点在这棵树上深度最大的公共的祖先节点。 换句话说,就是两个点在这棵树上距离最近的公共祖先节点。 所以LCA主要是用来处理当两个点仅有唯一一条确定的最短路径时的路径。 有人可能会问:那他本身或者其父亲节点是否可以作为祖先节点呢? 答案是肯定的,很简单,按照人的亲戚观念来说,你的父亲也是你的祖先,而LCA还可以将自己视为祖先节点。 举个例子吧,如下图所示4和5的最近公共祖先是2,5和3的最近公共祖先是1,2和1的最近公共祖先是1。 这就是最近公共祖先的基本概念了,那么我们该如何去求这个最近公共祖先呢? 通常初学者都会想到最简单粗暴的一个办法:对于每个询问,遍历所有的点,时间复杂度为\(O(n*q)\) ,很明显,n和q一般不会很小。 怎么办办? LCA其实有很多种解法,这里介绍 什么是Tarjan(离线)算法呢?顾名思义,就是在一次遍历中把所有询问一次性解决,所以其时间复杂度是\(O(n+q)\)。 Tarjan算法的优点在于相对稳定,时间复杂度也比较居中,也很容易理解。 下面详细介绍一下Tarjan算法的基本思路: 任选一个点为根节点,从根节点开始。 遍历该点u所有子节点v,并标记这些子节点v已被访问过。 若是v还有子节点,返回2,否则下一步。 合并v到u上。 寻找与当前点u有询问关系的点v。 若是v已经被访问过了,则可以确认u和v的最近公共祖先为v被合并到的父亲节点a。 遍历的话需要用到dfs来遍历(相信来看的人都懂吧...),至于合并,最优化的方式就是利用并查集来合并两个节点。 个人感觉这样还是有很多人不太理解,所以打算模拟一遍给大家看。 假设我们有一组数据 9个节点 8条边 联通情况如下: 1--2,1--3,2--4,2--5,3--6,5--7,5--8,7--9 即下图所示的树 设我们要查找最近公共祖先的点为9--8,4--6,7--5,5--3; 设 下面开始模拟过程: 取1为根节点,往下搜索发现有两个儿子2和3; 先搜2,发现2有两个儿子4和5,先搜索4,发现4没有子节点,则寻找与其有关系的点; 发现6与4有关系,但是 发现没有和4有询问关系的点了,返回此前一次搜索,更新 表示4已经被搜完,更新 先搜7,发现7有一个子节点9,搜索9,发现没有子节点,寻找与其有关系的点; 发现8和9有关系,但是 发现没有和9有询问关系的点了,返回此前一次搜索,更新vis[9]=1; 表示9已经被搜完,更新 发现5和7有关系,但是 发现没有和7有关系的点了,返回此前一次搜索,更新 表示7已经被搜完,更新 发现9与8有关系,此时 发现没有与8有关系的点了,返回此前一次搜索,更新 表示8已经被搜完,更新 发现7和5有关系,此时 又发现5和3有关系,但是 返回此前一次搜索,更新 发现2没有未被搜完的子节点,寻找与其有关系的点; 又发现没有和2有关系的点,则此前一次搜索,更新 表示2已经被搜完,更新f[2]=1,继续搜3,发现3有一个子节点6; 搜索6,发现6没有子节点,则寻找与6有关系的点,发现4和6有关系; 此时 发现没有与6有关系的点了,返回此前一次搜索,更新 更新 发现5和3有关系,此时 发现没有和3有关系的点了,返回此前一次搜索,更新 更新 经过这次dfs我们得出了所有的答案,有没有觉得很神奇呢?是否对Tarjan算法有更深层次的理解了呢? 参考博文:https://www.cnblogs.com/jvxie/p/4854719.html 算法详解之最近公共祖先(LCA) 标签:开始 初学 情况 处理 dfs 居中 否则 集合 upload 原文地址:https://www.cnblogs.com/hulean/p/11144059.html若图片出锅请转至here
概念
几一个Tarjan大法好!
Tarjan(u)//marge和find为并查集合并函数和查找函数
{
for each(u,v) //访问所有u子节点v
{
Tarjan(v); //继续往下遍历
marge(u,v); //合并v到u上
标记v被访问过;
}
for each(u,e) //访问所有和u有询问关系的e
{
如果e被访问过;
u,e的最近公共祖先为find(e);
}
}f[]数组为并查集的父亲节点数组,初始化f[i]=i,vis[]数组为是否访问过的数组,初始为0; 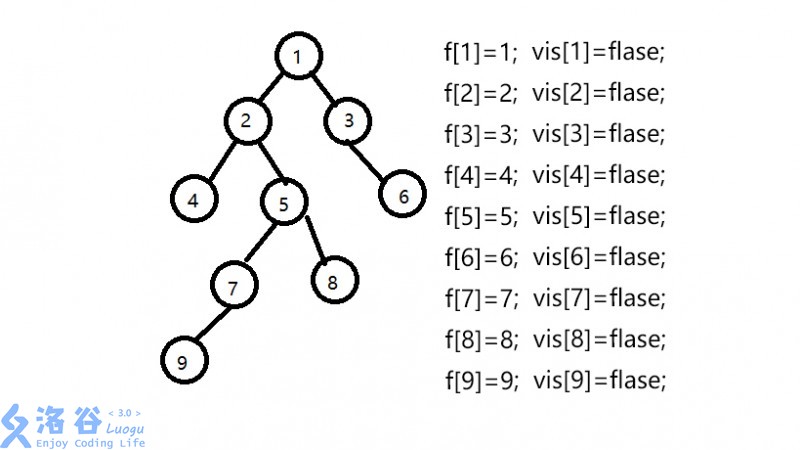
vis[6]=0,即6还没被搜过,所以不操作;vis[4]=1;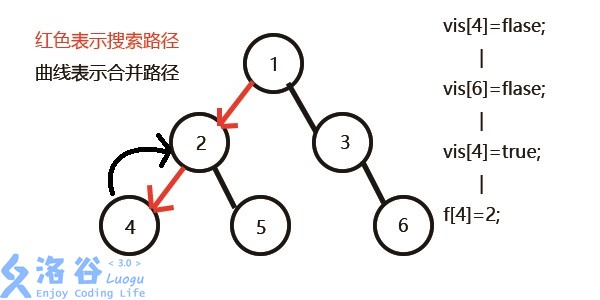
f[4]=2,继续搜5,发现5有两个儿子7和8;vis[8]=0,即8没被搜到过,所以不操作;f[9]=7,发现7没有没被搜过的子节点了,寻找与其有关系的点;vis[5]=0,所以不操作;vis[7]=1;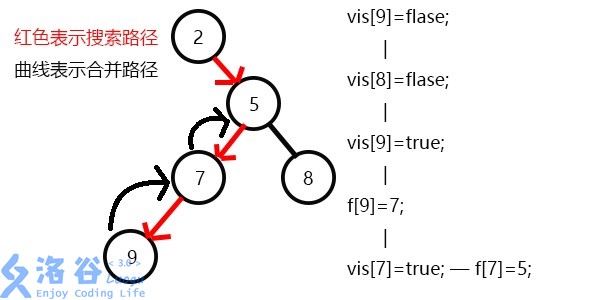
f[7]=5,继续搜8,发现8没有子节点,则寻找与其有关系的点;vis[9]=1,则他们的最近公共祖先为find(9)=5;(find(9)的顺序为f[9]=7-->f[7]=5-->f[5]=5 return 5;)vis[8]=1;f[8]=5,发现5没有没搜过的子节点了,寻找与其有关系的点;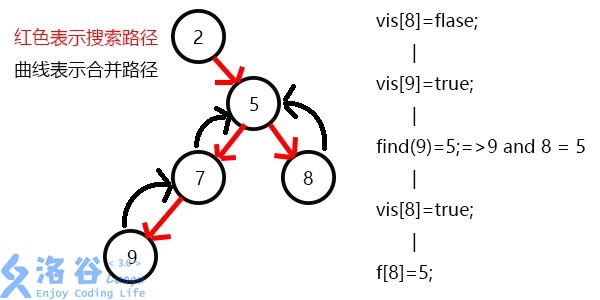
vis[7]=1,所以他们的最近公共祖先为find(7)=5;(find(7)的顺序为f[7]=5-->f[5]=5 return 5;)vis[3]=0,所以不操作,此时5的子节点全部搜完了;vis[5]=1,表示5已经被搜完,更新f[5]=2;vis[2]=1;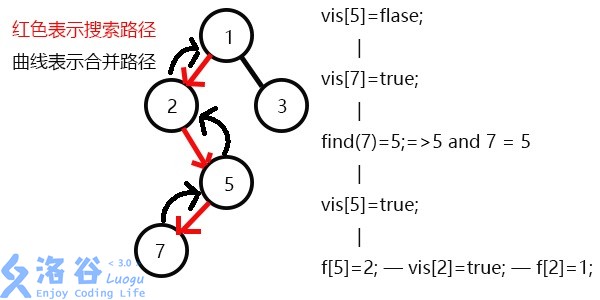
vis[4]=1,所以它们的最近公共祖先为find(4)=1;(find(4)的顺序为f[4]=2-->f[2]=2-->f[1]=1 return 1;)vis[6]=1,表示6已经被搜完了;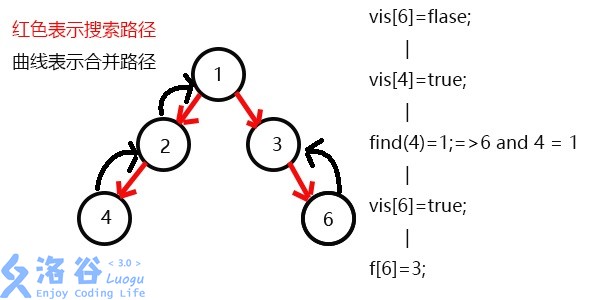
f[6]=3,发现3没有没被搜过的子节点了,则寻找与3有关系的点;vis[5]=1,则它们的最近公共祖先为find(5)=1;(find(5)的顺序为f[5]=2-->f[2]=1-->f[1]=1 return 1;)vis[3]=;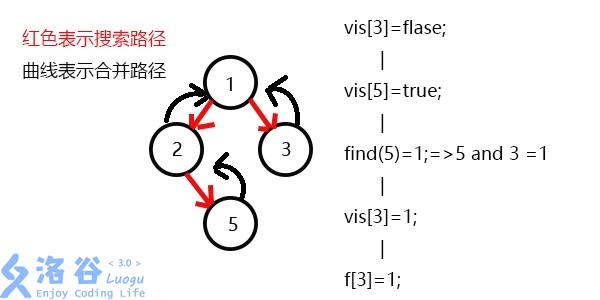
f[3]=1,发现1没有被搜过的子节点也没有有关系的点,此时可以退出整个dfs了。