Python权威指南的10个项目(1~5)
2020-12-13 06:13
YPE html PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN" "http://www.w3.org/TR/REC-html40/loose.dtd">
标签:用户 ring 遇到 本地 rip roo interrupt ref 学习
引言:??我相信学习Python过的朋友,一定会喜欢上这门语言,简单,库多,易上手,学习成本低,但是如果是学习之后,不经常使用,或者工作中暂时用不到,那么不久之后又会忘记,久而久之,就浪费了很多的时间再自己的“曾经”会的东西上。所以最好的方法就是实战,通过真是的小型项目,去巩固,理解,深入Python,同样的久而久之就不会忘记。
??所以这里小编带大家编写10个小型项目,去真正的实操Python,这10个小型项目是来自《Python权威指南》中后面10个章节的项目,有兴趣的朋友可以自行阅读。希望这篇文章能成为给大家在Python的学习道路上的奠基石。
??建议大家是一边看代码,一边学习,文章中会对代码进行解释:
这里是项目的gitlab地址(全代码):
https://gitlab.com/ZZY478086819/actualcombatproject
1. 项目1:自动添加标签
??这个项目主要介绍如何使用Python杰出的文本处理功能,包括使用正则表达式将纯文本文件转换为用 HTML或XML等语言标记的文件。
(1) 问题描述
??假设你要将一个文件用作网页,而给你文件的人嫌麻烦,没有 以HTML格式编写它。你不想手工添加需要的所有标签,想编写一个程序来自动完成这项工作。大致而言,你的任务是对各种文本元素(如标题和突出的文本)进行分类,再清晰地标记它 们。就这里的问题而言,你将给文本添加HTML标记,得到可作为网页的文档,让Web浏览器能 够显示它。然而,创建基本引擎后,完全可以添加其他类型的标记(如各种形式的XML和LATEX 编码)。对文本文件进行分析后,你甚至可以执行其他的任务,如提取所有的标题以制作目录。
(2) 代码实现前准备
实现思路:
?? - 输入无需包含人工编码或标签
?? - 程序需要能够处理不同的文本块(如标题、段落和列表项)以及内嵌文本(如突出的文 本和URL)。
?? - 虽然这个实现添加的是HTML标签,但应该很容易对其进行扩展,以支持其他标记语言
有用的工具:
?? - 肯定需要读写文件,至少要从标准输入
?? - 可能需要迭代输入行
?? - 需要使用一些字符串方法
?? - 可能用到一两个生成器
?? - 可能需要模块re
(3) 简单实现
分为两个步骤:
- 找出文本块:要找出这些文本块,一种简单的方法是,收集空行前的所有行并将它们返回,然后重复这样 的操作。不需要收集空行,因此不需要返回空文本块(即多个空行)。另外,必须确保文件的最 后一行为空行,否则无法确定最后一个文本块到哪里结束。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#生成器lines是个简单的工具,在文件末尾添加一个空行
def lines(file):
for line in file:
yield line
yield ‘\n‘
# 生成器blocks实现了刚才描述的方法。生成文本块时,将其包含的所有行合并,
#并将两端多余的空白(如列表项缩进和换行符)删除,得到一个表示文本块的字符串。
def blocks(file):
block=[]
for line in lines(file):
if line.strip():
block.append(line)
elif block:
yield ‘‘.join(block).strip()
block=[]
if __name__==‘__main__‘:
file=‘../../file_data/test_input.txt‘
with open(file,‘r+‘) as f :
for line in blocks(f):
print(line)
- 添加一些标记:可按如下基本步骤进行:打印一些起始标记、对于每个文本块,在段落标签内打印它、打印一些结束标记。假设要将第一个文本块放在一级标题标签(h1)内,而不是段 落标签内。另外,还需将用星号括起的文本改成突出文本(使用标签em)。这样程序将更有用一些。 由于已经编写好了函数blocks。
import sys,re
#引用刚刚编写的util模块
from util import *
print(‘
zzy-python ‘)
title = True
file=‘../../file_data/test_input.txt‘
#for block in blocks(sys.stdin) 这里可以使用标准的输入,小编为了方便运行,就本地读取
with open(file) as f:
for block in blocks(f):
re.sub(r‘\*(.+?\*)‘,r‘\1‘,block)
if title:
print(‘‘)
print(block)
print(‘
‘)
title=False
else:
print(‘‘)
print(block)
print(‘
‘)
print(‘‘)??到这简单的实现就完成了但是如果要扩展这个原型,该如何办呢?可在for循环中添加检查,以确定文本块是否是标题、列表项等。为此,需要添加其他的正则表达式,代码可能很快变得很乱。更重要的是,要让程序输出其他格式的代码(而不是HTML)很难,但是这个项目的目标之一就是能够轻松地添加其他输出格式。
(4) 完整实现
??为了提高可扩展性,需提高程序的模块化程度(将功能放在 独立的组件中)。要提高模块化程度,方法之一是采用面向对象设计。这里我们需要寻找一些抽象,让程序在变得复杂时也易于管理。下面先来列出一些潜在的组件:
?? 解析器:添加一个读取文本并管理其他类的对象。
?? 规则:对于每种文本块,都制定一条相应的规则。这些规则能够检测不同类型的文本块 并相应地设置其格式。
?? 过滤器:使用正则表达式来处理内嵌元素。
?? 处理程序:供解析器用来生成输出。每个处理程序都生成不同的标记。
那么接下来,小编就对这几个组件,进行详细介绍:
① 处理程序
??对于每种文本块,它都提供两个处理方法:一个用于添加起始标签,另一个用于添加结束标签。例如它可能包含用于处理段落的方法start_paragraph和end_paragraph。生成HTML代码时,可像 下面这样实现这些方法:
class HTMLRenderer:
def start_paragraph(self):
print(‘‘)
def end_paragraph(self):
print(‘‘)对于其他类型的文本块,添加不同的开始和结束标签,对于形如连接,**包围的内容,需要特殊处理,例:
def sub_emphasis(self, match):
return ‘{}‘.format(match.group(1))当然对于简单的文本内容,我们只需要:
def feed(self, data):
print(data)最后,我们可以创建一个处理程序的父类,负责处理一些管 理性细节。例如:不通过全名调用方法(如start_paragraph---start(selef,name)---调用 ’start_’+ name方法)等等。
② 规则
??处理程序的可扩展性和灵活性都非常高了,该将注意力转向解析(对文本进行解读) 了。为此,我们将规则定义为独立的对象,而不像初次实现中那样使用一条包含各种条件和操作 的大型if语句。规则是供主程序(解析器)使用的。主程序必须根据给定的文本块选择合适的规则来对其进 行必要的转换。换而言之,规则必须具备如下功能。
?? - 知道自己适用于那种文本块(条件)。
?? - 对文本块进行转换(操作)。
??因此每个规则对象都必须包含两个方法:condition和action:
方法condition只需要一个参数:待处理的文本块。它返回一个布尔值,指出当前规则是否 适用于处理指定的文本块。方法action也将当前文本块作为参数,但为了影响输出,它还必须能够访问处理器对象。
#我们以标题规则为例:
def condition(self, block):
#如果文本块符合标题的定义,就返回True;否则返回False。
def action(self, block, handler):
/**调用诸如handler.start(‘headline‘)、handler.feed(block)和handler.end(‘headline‘)等方法。
我们不想尝试其他规则,因此返回True,以结束对当前文本块的处理。*/??当然这里还可以定义一个rule的父类,比如action,condition方法可以在不同的规则中有自己的实现。
③ 过滤器
??由于Handler类包含方法sub,每个过滤器都可用一个正则表达 式和一个名称(如emphasis或url)来表示。
④ 解析器
??接下来就是应用的核心,Parser类。它使用一个处理程序以及一系列规则和过滤器 将纯文本文件转换为带标记的文件(这里是HTML文件)。
其中包括了:完成准 备工作的构造函数、添加规则的方法、添加过滤器的方法以及对文件进行解析的方法。
⑤ 创建规则和过滤器
??至此,万事俱备,只欠东风——还没有创建具体的规则和过滤器。目前绝大部分工作都是在让规则和过滤器与处理程序一样灵活。通过使用一组复杂的规则,可处理复杂的文档,但我们将保持尽可能简单。只创建分别用于处理题目、其他标题和列表项的规则。应将相连的列表项视为一个列表,因此还将创建一个处理 整个列表的列表规则。最后,可创建一个默认规则,用于处理段落,即其他规则未处理的所有文本块。各个不同的复杂文档的规则已经在代码块中解释。
??最后我们通过正则表达式,添加过滤器,分别找出:出要突出的内容、URL和Email 地址。(https://gitlab.com/ZZY478086819/actualcombatproject)
至此我们将以上的内容通过代码实现,具体代码小编已经上传至github上,具体的编写步骤为:
处理程序(handlers.py) → 规则(rules.py)→主程序(markup.py)
2. 项目2:绘制图表
这个项目主要介绍:用Python创建图表。具体地说,你将创建一个PDF文件,其中包含的图表对 从文本文件读取的数据进行了可视化。虽然常规的电子表格软件都提供这样的功能,但Python提 供了更强大的功能。
PDF介绍:它指的 是可移植的文档格式(portable document format)。PDF是Adobe开发的一种格式,可表示任何包 含图形和文本的文档。不同于Microsoft Word等文档,PDF文件是不可编辑的,但有适用于大多 数平台的免费阅读器软件。另外,无论在哪种平台上使用什么阅读器来查看,显示的PDF文件都 相同;而HTML格式则不是这样的,它要求平台安装指定的字体,还必须将图片作为独立的文件 进行传输。
(1) 问题描述
根据不同的文本内容,生成相应的建PDF格式(和其他格式)的图形和文档。这个项目主要将根据有关太阳黑子的数据 (来自美国国家海洋和大气管理局的空间天气预测中心)创建一个折线图。创建的程序必须具备如下功能:
- 从网上下载数据文件
- 对数据文件进行解析,并提取感兴趣的内容
- 根据这些数据创建PDF图形
(2) 准备工作
- 图形生成包:ReportLab(import reportlab)
- 测试数据:http://www.swpc.noaa.gov中下载
(3) 简单实现
ReportLab由很多部分组成,让你能够以多种方式生成输出。就生成PDF而言,最基本的模块 是pdfgen,其中的Canvas类包含多个低级绘图方法。例如,要在名为c的Canvas上绘制直线,可调 用方法c.line。
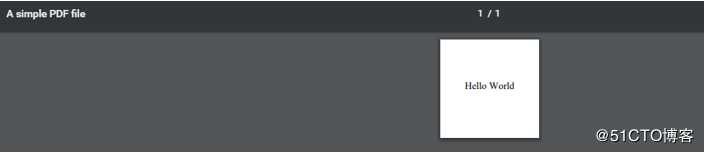
这里展示一个实例:它在一个100点×100点的PDF图形中央绘制字符串"Hello, world!"。
from reportlab.graphics.shapes import Drawing,String
from reportlab.graphics import renderPDF
#创建一个指定尺寸的Drawing对象
d=Drawing(100,100)
#再创建具有指定属性的图形元素(这里是一个String对象)
s=String(50,50,‘Hello World‘,textAnchor=‘middle‘)
#将图形元素添加到Drawing对象中
d.add(s)
#以PDF格式渲染Drawing对象,并将结果保存到文件中
renderPDF.drawToFile(d,‘hello.pdf‘,‘A simple PDF file‘)
(4) 绘制折折线
为绘制太阳黑子数据折线图,需要绘制一些直线。实际上,你需要绘制多条相连的直线。ReportLab提供了一个专门用于完成这种工作的类——PolyLine。
要绘制折线图,必须为数据集中的每列数据绘制一条折线。
①这里先创建出一个太阳黑子图形程序的第一个原型:
from reportlab.lib import colors
from reportlab.graphics.shapes import *
from reportlab.graphics import renderPDF
# Year Month Predicted High Low
data=[
(2007, 8, 113.2, 114.2, 112.2),
(2007, 9, 112.8, 115.8, 109.8),
(2007, 10, 111.0, 116.0, 106.0),
(2007, 11, 109.8, 116.8, 102.8),
(2007, 12, 107.3, 115.3, 99.3),
(2008, 1, 105.2, 114.2, 96.2),
(2008, 2, 104.1, 114.1, 94.1),
(2008, 3, 99.9, 110.9, 88.9),
(2008, 4, 94.8, 106.8, 82.8),
(2008, 5, 91.2, 104.2, 78.2),
]
#创建一个指定尺寸的Drawing对象
drawing=Drawing(200,150)
pred=[row[2]-40 for row in data]
high = [row[3]-40 for row in data]
low = [row[4]-40 for row in data]
times=[200*((row[0]+row[1]/12.0)-2007)-110 for row in data]
drawing.add(PolyLine(list(zip(times,pred)), strokeColor=colors.blue))
drawing.add(PolyLine(list(zip(times,high)), strokeColor=colors.blue))
drawing.add(PolyLine(list(zip(times,low)), strokeColor=colors.blue))
drawing.add(String(65,115,‘Sunspots‘,fontSize=18,fillColor=colors.red))
renderPDF.drawToFile(drawing,‘report1.pdf‘,‘Sunspots‘)
②最终版
这里为了方便我们直接读取本地的文件,测试文件已经放入项目中:Predict.txt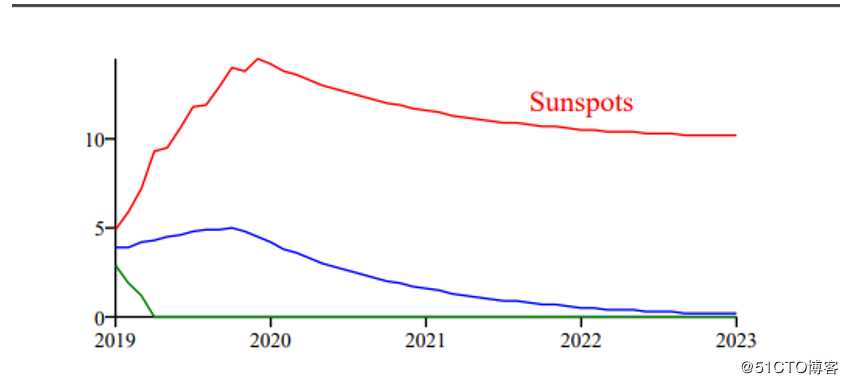
具体的项目代码粘贴在小编的github中!
3. 项目3:万能的XML
这个项目的目标是,根据描述各种网页和目录的单个XML文件生成完整的网站。
实现目标:
- 整个网站由单个XML文件描述,该文件包含有关各个网页和目录的信息
- 程序应根据需要创建目录和网页
-
应能够轻松地修改整个网站的设计并根据新的设计重新生成所有网页
(1) 问题描述
在这个项目中,要解决的通用问题是解析(读取并处理)XML文件。小编之前接到的一个任务就是解析XML提取其中相应的字段,不过使用的java的dome4j解析的XML,虽然过程不复杂,但是我们看看Python有什么独到之处。
(2) 准备工作
- 使用的SAX解析器去解析XML(from xml.sax import make_parser)
- 要编写处理XML文件的程序,必须先设计要使用的XML格式(包含哪些属性?各个标签都用来做什么),相当于XML文件的元数据信息
这里有些朋友可能对XML格式不是很了解,这里小编做一个介绍:- ul >
title
这里的website是一个根标签,整个XML报告中只有一个。
director、h1、page、ul则属于website中的标签,可能有多个,也可能嵌套。
name="index" 表示标签中的属性的name 和value
这里我们只有了解一个XML报告中的每个标签的含义,才能做对应的解析,提取有用的信息。(3) 简单实现
说了这么多我们先简单实现一个解析XML,这里提供一个文件website.xml。
(具体文件小编会粘贴到自己的项目中)
这里我们通过解析website.xml,创建一个HTML页面,执行如下任务:
- 在每个page元素的开头,打开一个给定名称的新文件,并在其中写入合适的HTML首部(包 括指定的标题)。
- 在每个page元素的末尾,将合适的HTML尾部写入文件,再将文件关闭。
- 在page元素内部,遍历所有的标签和字符而不修改它们(将其原样写入文件)。
- 在page元素外部,忽略所有的标签(如website和directory)。#!/usr/bin/env python # -*- coding: utf-8 -*- from xml.sax.handler import ContentHandler from xml.sax import parse ‘‘‘ 这个模块主要完成: 简单的解析这个XML,提取有用信息,重新格式化为HTML格式, 最终根据不同page写入不同的HTML文件中 ‘‘‘ class PageMaker(ContentHandler): #跟踪是否在标签内部 passthrough = False #标签的开始 def startElement(self,name,attrs): if name==‘page‘: self.passthrough=True self.out= open(attrs[‘name‘] + ‘.html‘, ‘w‘) #创建输出到的HTML文件的名称 self.out.write(‘\n‘) #name="index" title="Home Page" #attrs[‘title‘]提取标签中属性的key-value self.out.write(‘{} \n‘.format(attrs[‘title‘])) self.out.write(‘\n‘) elif self.passthrough: #如果标签下有嵌套的子标签 self.out.write(‘‘) #标签的结束 def endElement(self, name): if name==‘page‘: self.passthrough = False self.out.write(‘\n\n‘) self.out.close() elif self.passthrough: self.out.write(‘{}>‘.format(name)) #标签中的内容比如:123
--- > 123 def characters(self, content): if self.passthrough:self.out.write(content) file_path=‘../../../file_data/website.xml‘ #解析 parse(file_path,PageMaker())解析完成之后在当前目录下:

出现这几个文件,就是解析出来的HTML。
不知道大家有没有发现以上代码的不足之处:
- 这里我们在startElement和endElement使用了if判断语句,这里我们只处理了一个page标签,如果要处理的标签很多,那么这个if将很长很长
- HTML代码时硬编码
- 我们查看标签的时候由一个director标签,这里是将不同的page放入不同的目录中,而以上的代码最终生成的HTML都在同一个目录下,这里我们再次实现时将会改进
(4) 最终版
这里由于小编将代码的各个功能进行了解耦,分不同的功能模块进行开发,这里小编将详细介绍每个步骤具体实现什么功能,当然最终的代码小编也会上传到github中供大家参考。
鉴于SAX机制低级而简单,编写一个混合类来处理管理性细节通常很有帮助。这些管理性细 节包括收集字符数据,管理布尔状态变量(如passthrough),将事件分派给自定义事件处理程序, 等等。就这个项目而言,状态和数据处理非常简单,因此这里将专注于事件分派。
① 分派器混合类
与其在标准通用事件处理程序(如startElement)中编写长长的if语句,不如只编写自定义 的具体事件处理程序(如startPage)并让它们自动被调用。你可在一个混合类中实现这种功能, 再通过继承这个混合类和ContentHandler来创建一个子类。
程序实现的功能:
- startElement被调用时,如果参数name为‘foo‘,它应尝试查找事件处理程序startFoo,并 使用提供给它的属性调用这个处理程序
- 同样,endElement被调用时,如果&am
下一篇:网页裁剪图片(FileAPI)