在Windows的控制台界面下输出BMPString的内容
2020-12-13 14:21
标签:c语言 unicode 在解析X.509格式的数字证书时,有时候从证书中提取出的 commonName、countryName 等项的值类型是 BMPString,特别当这些值是中文的时候。此时如果在 Windows 的控制台下使用使用 wprintf() 输出这些值,显示的结果是乱码。 为了搞清楚产生乱码的原因,找到一张证书,查看其中的 countryName,对应的 ASN.1 编码类型是BMPString,编码是:0x1E, 0x4, 0x4E, 0x2D, 0x56, 0xFD,对应值为“中国”。在网上查询了”中国“对应的 Unicode 编码是 {0x4E, 0x2D, 0x56, 0xFD},0x4E, 0x2D 对应字符“中”,0x56, 0xFD 对应字符“国” 。将字符 0x4E, 0x2D, 0x56, 0xFD 顺序放入一个字符数组,依次调用 setlocale() 、wprintf()
函数,输出为乱码。 在网上查了一下,对于BMPString 的 ASN.1 编码,其负载部分采用 Unicode 编码中的 UTF-16 编码方式,一个字符的编码占两个字节。但是这两个字节中哪一个用来存放编码的高 8 位、哪一个用来存放编码的低 8 位,在不同的地方有不同处理方式。在 ASN.1 编码中,一般对于负载部分的编码都采用 big-endian 顺序,所以从数字证书中提取出来的“中国”对应的编码为 {0x4E, 0x2D, 0x56, 0xFD},其顺序是 Big-endian 顺序。在 Intel
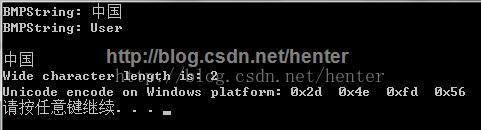
的 CPU 上通常使用 little-endian 字节顺序,Windows 中处理数据也采用 little-endian 顺序,所以在 Windows 中试图输出Big-endian 顺序编码的字符,当然会产生乱码。(顺便说一句,对于 UniversalString 的ASN.1 编码,其负载部分采用Unicode 编码中的 UTF-32 编码方式,一个字符的编码占四个字节。) 要解决输出乱码的问题,方法是在输出前,先将 Big-endian 顺序编码的字符转换为 little-endian 顺序编码的字符,然后再输出,就不会产生乱码了。下面给出一个示例程序: 输出结果如下图: 在Windows的控制台界面下输出BMPString的内容 标签:c语言 unicode 原文地址:http://blog.csdn.net/henter/article/details/40616461/**************************************************
* Author: HAN Wei
* Author's blog: http://blog.csdn.net/henter/
* Date: Oct 30th, 2014
* Description: demonstrate how to print BMPString
on Windows console
**************************************************/
#include
上一篇:python读写本地文件
下一篇:C#操作XML
文章标题:在Windows的控制台界面下输出BMPString的内容
文章链接:http://soscw.com/essay/34002.html